HP + Galileo Partner to Accelerate Trustworthy AI




Recent Posts


HP + Galileo Partner to Accelerate Trustworthy AI
Galileo and HP partner to enable faster and safer deployment of AI-powered applications.


Survey of Hallucinations in Multimodal Models
An exploration of type of hallucinations in multimodal models and ways to mitigate them.


Solving Challenges in GenAI Evaluation – Cost, Latency, and Accuracy
Learn to do robust evaluation and beat the current SoTA approaches

Galileo Luna: Breakthrough in LLM Evaluation, Beating GPT-3.5 and RAGAS
Research backed evaluation foundation models for enterprise scale


Webinar - The Future of Enterprise GenAI Evaluations
Evaluations are critical for enterprise GenAI development and deployment. Despite this, many teams still rely on 'vibe checks' and manual human evaluation. To productionize trustworthy AI, teams need to rethink how they evaluate their solutions.


Meet Galileo at Databricks Data + AI Summit
Join us at Databricks Data+AI Summit to see the latest innovations at the convergence of data and AI and learn from leading GenAI experts!

Webinar – Galileo Protect: Real-Time Hallucination Firewall
We’re excited to announce Galileo Protect – an advanced GenAI firewall that intercepts hallucinations, prompt attacks, security threats, and more in real-time! Register for our upcoming webinar to see Protect live in action.

Introducing Galileo Protect: Your Real-Time Hallucination Firewall
We're thrilled to unveil Galileo Protect, an advanced GenAI firewall solution that intercepts hallucinations, prompt attacks, security threats, and more in real-time.


Generative AI and LLM Insights: May 2024
The AI landscape is exploding in size, with some early winners emerging, but RAG reigns supreme for enterprise LLM systems. Check out our roundup of the top generative AI and LLM articles for May 2024.

Practical Tips for GenAI System Evaluation
It’s time to put the science back in data science! Craig Wiley, Sr Dir of AI at Databricks, joined us at GenAI Productionize 2024 to share practical tips and frameworks for evaluating and improving generative AI. Read key takeaways from his session.


Is Llama 3 better than GPT4?
Llama 3 insights from the leaderboards and experts

Enough Strategy, Let's Build: How to Productionize GenAI
At GenAI Productionize 2024, expert practitioners shared their own experiences and mistakes to offer tools and techniques for deploying GenAI at enterprise scale. Read key takeaways from the session on how to productionize generative AI.

The Enterprise AI Adoption Journey
2024 has been a landmark year for generative AI, with enterprises going from experimental proofs of concept to production use cases. At GenAI Productionize 2024, our enterprise executive panel shared lessons learned along their AI adoption journeys.


Mastering RAG: How To Observe Your RAG Post-Deployment
Learn to setup a robust observability solution for RAG in production

Generative AI and LLM Insights: April 2024
Smaller LLMs can be better (if they have a good education), but if you’re trying to build AGI you better go big on infrastructure! Check out our roundup of the top generative AI and LLM articles for April 2024.


GenAI at Enterprise Scale
Join Ya Xu, Head of Data and AI at LinkedIn, to learn the technologies, frameworks, and organizational strategies she uses to scale GenAI at LinkedIn.


Mastering RAG: Choosing the Perfect Vector Database
Master the art of selecting vector database based on various factors

Mastering RAG: How to Select A Reranking Model
Choosing the best reranking model for your RAG-based QA system can be tricky. This blog post simplifies RAG reranking model selection, helping you pick the right one to optimize your system's performance.

Generative AI and LLM Insights: March 2024
Stay ahead of the AI curve! Our February roundup covers: Air Canada's AI woes, RAG failures, climate tech & AI, fine-tuning LLMs, and synthetic data generation. Don't miss out!

Mastering RAG: How to Select an Embedding Model
Unsure of which embedding model to choose for your Retrieval-Augmented Generation (RAG) system? This blog post dives into the various options available, helping you select the best fit for your specific needs and maximize RAG performance.

Mastering RAG: Advanced Chunking Techniques for LLM Applications
Learn advanced chunking techniques tailored for Language Model (LLM) applications with our guide on Mastering RAG. Elevate your projects by mastering efficient chunking methods to enhance information processing and generation capabilities.

Mastering RAG: Improve RAG Performance With 4 Powerful RAG Metrics
Unlock the potential of RAG analysis with 4 essential metrics to enhance performance and decision-making. Learn how to master RAG methodology for greater effectiveness in project management and strategic planning.

Introducing RAG & Agent Analytics
Introducing a powerful set of workflows and research-backed evaluation metrics to evaluate and optimize RAG systems.

Generative AI and LLM Insights: February 2024
February's AI roundup: Pinterest's ML evolution, NeurIPS 2023 insights, understanding LLM self-attention, cost-effective multi-model alternatives, essential LLM courses, and a safety-focused open dataset catalog. Stay informed in the world of Gen AI!


Webinar - Fix Hallucinations in RAG Systems with Pinecone and Galileo
Watch our webinar with Pinecone on optimizing RAG & chain-based GenAI! Learn strategies to combat hallucinations, leverage vector databases, and enhance RAG analytics for efficient debugging.

Mastering RAG: How To Architect An Enterprise RAG System
Explore the nuances of crafting an Enterprise RAG System in our blog, "Mastering RAG: Architecting Success." We break down key components to provide users with a solid starting point, fostering clarity and understanding among RAG builders.

Galileo + Google Cloud: Evaluate and Observe Generative AI Applications Faster
Galileo on Google Cloud accelerates evaluating and observing generative AI applications.

Mastering RAG: LLM Prompting Techniques For Reducing Hallucinations
Dive into our blog for advanced strategies like ThoT, CoN, and CoVe to minimize hallucinations in RAG applications. Explore emotional prompts and ExpertPrompting to enhance LLM performance. Stay ahead in the dynamic RAG landscape with reliable insights for precise language models. Read now for a deep dive into refining LLMs.

Ready for Regulation: Preparing for the EU AI Act
Prepare for the impact of the EU AI Act with our actionable guide. Explore risk categories, conformity assessments, and consequences of non-compliance. Learn practical steps and leverage Galileo's tools for AI compliance. Ensure your systems align with regulatory standards.

Mastering RAG: 8 Scenarios To Evaluate Before Going To Production
Learn how to Master RAG. Delve deep into 8 scenarios that are essential for testing before going to production.


Introducing the Hallucination Index
The Hallucination Index provides a comprehensive evaluation of 11 leading LLMs' propensity to hallucinate during common generative AI tasks.


15 Key Takeaways From OpenAI Dev Day
Galileo's key takeaway's from the 2023 Open AI Dev Day, covering new product releases, upgrades, pricing changes and many more!

5 Key Takeaways From President Biden’s Executive Order For Trustworthy AI
Explore the transformative impact of President Biden's Executive Order on AI, focusing on safety, privacy, and innovation. Discover key takeaways, including the need for robust Red-teaming processes, transparent safety test sharing, and privacy-preserving techniques.


Paper - Galileo ChainPoll: A High Efficacy Method for LLM Hallucination Detection
ChainPoll: A High Efficacy Method for LLM Hallucination Detection. ChainPoll leverages Chaining and Polling or Ensembling to help teams better detect LLM hallucinations. Read more at rungalileo.io/blog/chainpoll.


Webinar - Deeplearning.ai + Galileo - Mitigating LLM Hallucinations
Join in on this workshop where we will showcase some powerful metrics to evaluate the quality of the inputs (data quality, RAG context quality, etc) and outputs (hallucinations) with a focus on both RAG and fine-tuning use cases.

Galileo x Zilliz: The Power of Vector Embeddings
Galileo x Zilliz: The Power of Vector Embeddings

RAG Vs Fine-Tuning Vs Both: A Guide For Optimizing LLM Performance
A comprehensive guide to retrieval-augmented generation (RAG), fine-tuning, and their combined strategies in Large Language Models (LLMs).

Webinar - Announcing Galileo LLM Studio: A Smarter Way to Build LLM Applications
Webinar - Announcing Galileo LLM Studio: A Smarter Way to Build LLM Applications


A Framework to Detect & Reduce LLM Hallucinations
Learn about how to identify and detect LLM hallucinations


Announcing LLM Studio: A Smarter Way to Build LLM Applications
LLM Studio helps you develop and evaluate LLM apps in hours instead of days.


A Metrics-First Approach to LLM Evaluation
Learn about different types of LLM evaluation metrics needed for generative applications


5 Techniques for Detecting LLM Hallucinations
A survey of hallucination detection techniques

Understanding LLM Hallucinations Across Generative Tasks
The creation of human-like text with Natural Language Generation (NLG) has improved recently because of advancements in Transformer-based language models. This has made the text produced by NLG helpful for creating summaries, generating dialogue, or transforming data into text. However, there is a problem: these deep learning systems sometimes make up or "hallucinate" text that was not intended, which can lead to worse performance and disappoint users in real-world situations.


Pinecone + Galileo = get the right context for your prompts
Galileo LLM Studio enables Pineonce users to identify and visualize the right context to add powered by evaluation metrics such as the hallucination score, so you can power your LLM apps with the right context while engineering your prompts, or for your LLMs in production

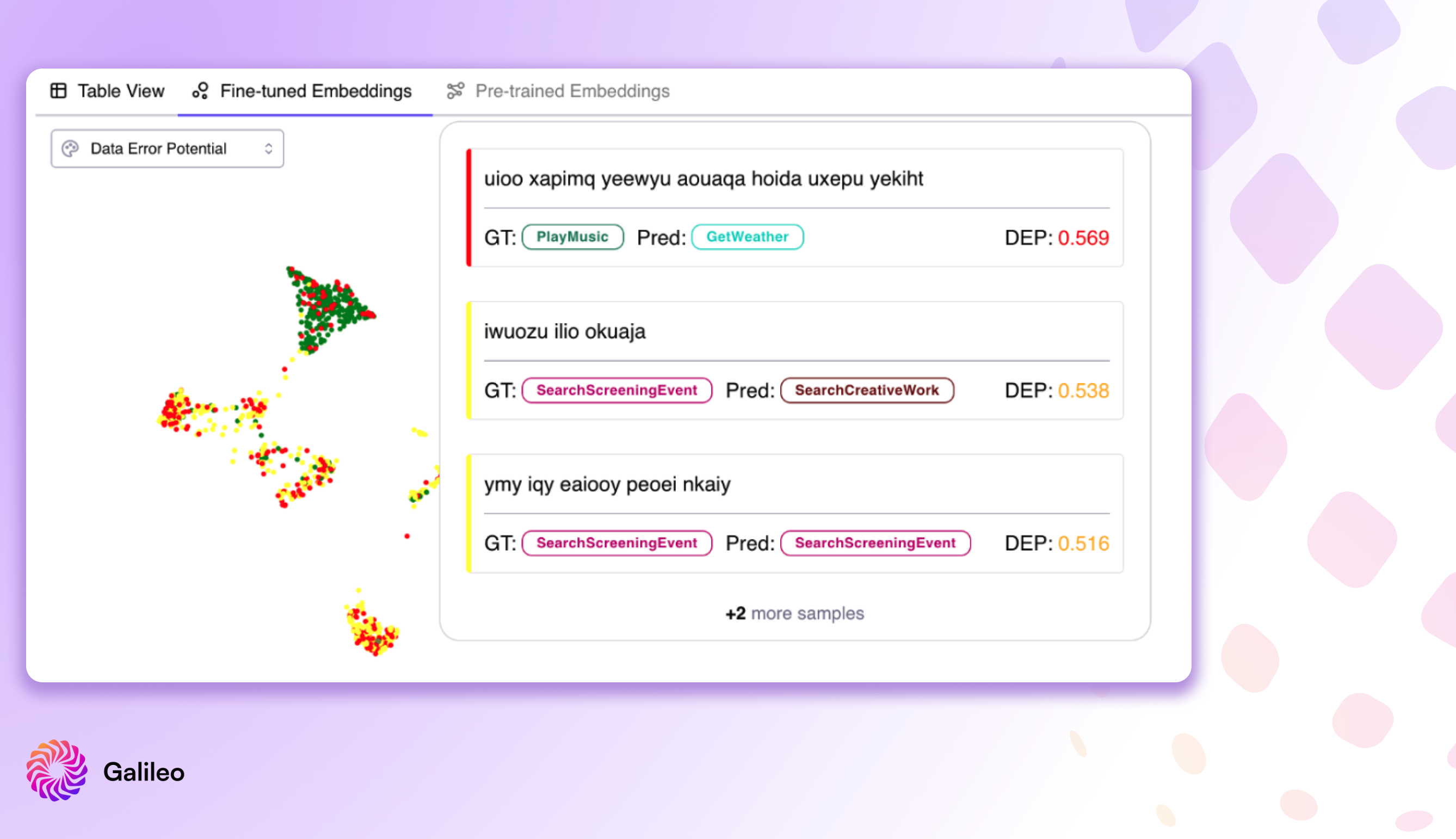
Introducing Data Error Potential (DEP) - New Powerful Metric for Quantifying Data Difficulty for a Model
The Data Error Potential (DEP) is a 0 to 1 score that provides a tool to very quickly sort and bubble up data that is most difficult and worthwhile to explore when digging into your model’s errors. Since DEP is task agnostic, it provides a strong metric to guide exploration of model failure modes.


LabelStudio + Galileo: Fix your ML data quality 10x faster
Galileo integrates deeply with Label Studio to help data scientists debug and fix their training data 10x faster.


ImageNet Data Errors Discovered Instantly using Galileo
Using Galileo you can surface labeling errors and model errors on the most popular dataset in computer vision. Explore the various error type and simple visualization tools to find troublesome data points.


Webinar - Unpacking The State of Data Quality in Machine Learning
Unpack the findings of our State of Machine Learning Data Quality Report. We have surveyed 500 experienced data professionals to learn what types of data they work with, what data errors they encounter, and what technologies they use.


Free Machine Learning Workshop - Build Higher Quality Models with Higher Quality Data
Learn how to instantly resolve data errors using Galileo. Galileo Machine Learning Data Quality Intelligence enables ML Practitioners to resolve data errors.

NLP: Huggingface Transformers NER, understanding BERT with Galileo
HuggingFace has proved to be one of the leading hubs for NLP-based models and datasets powering so many applications today. But in the case of NER, as with any other NLP task, the quality of your data can impact how well (or poorly) your models perform during training and post-production.


Building High-Quality Models Using High Quality Data at Scale
One neglected aspect of building high-quality models is that it depends on one crucial entity: high quality data. Good quality data in ML is the most significant impediment to seamless ML adoption across the enterprise.

How to Scale your ML Team’s Impact
Putting a high-quality Machine Learning (ML) model into production can take weeks, months, or even quarters. Learn how ML teams are now working to solve these bottlenecks.

Fixing Your ML Data Blindspots
When working on machine learning (ML) projects, the challenges are usually centered around datasets in both the pre-training and post-training phases, with their own respective issues that need to be addressed. Learn about different ML data blind spots and how to address these issues.

Being 'Data-Centric' is the Future of Machine Learning
Machine Learning is advancing quickly but what is changing? Learn what the state of ML is today, what being data-centric means, and what the future of ML is turning into.

4 Types of ML Data Errors You Can Fix Right Now ⚡️
In this article, Galileo founding engineer Nikita Demir discusses common data errors that NLP teams run into, and how Galileo helps fix these errors in minutes, with a few lines of code.

5 Principles You Need To Know About Continuous ML Data Intelligence
Build better models, faster, with better data. We will dive into what is ML data intelligence, and it's 5 principles you can use today.

“ML Data” : The past, present and future
Data is critical for ML. But it wasn't always this way. Learn about how focusing on ML Data quality came to become the central figure for the best ML teams today.

🔭 Improving Your ML Datasets, Part 2: NER
We used Galileo on the popular MIT dataset with a NER task, to find data errors fast, fix them, get meaningful gains within minutes, and made the fixed dataset available for use.


🔭 What is NER And Why It’s Hard to Get Right
In this post, we discuss the Named Entity Recognition (NER) task, why it is an important component of various NLP pipelines, and why it is particularly challenging to improve NER models.

🔭 Improving Your ML Datasets With Galileo, Part 1
We used Galileo on the popular Newsgroups dataset to find data errors fast, fix them, get meaningful gains within minutes, and made the fixed dataset available publicly for use.

Introducing ML Data Intelligence For Unstructured Data
“The data I work with is always clean, error free, with no hidden biases” said no one that has ever worked on training and productionizing ML models. Learn what ML data Intelligence is and how Galileo can help with your unstructured data.
All Tags
Subscribe to Newsletter
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
