HP + Galileo Partner to Accelerate Trustworthy AI
A Metrics-First Approach to LLM Evaluation




There has been tremendous progress in the world of Large Language Models (LLMs). We have seen a series of blockbuster models like GPT3, GPT3.5, GPT4, Falcon, MPT and Llama pushing the state of the art. The industry has started adopting them for various applications but there's a big problem. It's hard to figure out how well these models are performing. Companies are struggling to compare different LLMs for generative applications. The tendency of LLMs to hallucinate requires us to measure them carefully. In this blog, we discuss helpful metrics for evaluating LLMs and understanding their suitability for your use cases.
Need for new LLM evaluation metrics
It is easy to start building with Large Language Models (LLMs) such as OpenAI's ChatGPT, but they can be very difficult to evaluate. The main concerns around evaluations are:
- Human evaluation is costly and prone to errors: LLMs are used for varied generative tasks which cannot be judged by these metrics. In desperation, companies often rely on human vibe check. But human annotations are costly and full of biases which make evaluation slow and unreliable.
- Poor correlations with human judgment: Traditional metrics like BLEU / ROUGE have shown poor correlation with how humans evaluate model output. Without reliable metrics it becomes hard to know if the LLM app is release worthy.
- Absence of reliable benchmarks: Researchers have come up with benchmarks like Open LLM Leaderboard, but they do not evaluate the generative capability since the tasks contain multiple choice questions. The datasets used are also limited and might not have domain coverage for the target use case.
Given these challenges, companies should prioritize investments in the development of evaluation metrics. These metrics will enable them to make data-driven decisions without depending solely on human judgment. Let's explore some key metrics that can assist companies in designing an evaluation system to enhance their generative applications.
Types of LLM Evaluation Metrics
Over time, many metrics have been proposed to measure the quality of LLM outputs. How to best evaluate LLMs is still an active research work, but we have found some which are more useful than others. We categorize them below to make them easier to understand.


Top Level Metrics for LLM Evaluation
These are well known metrics which can be used for any application. They work for any input/output of the LLMs.
1. Context Adherence
Context adherence measures whether the model’s response is supported by the context given to it. This checks if the model is stating facts that are out of context—hallucinations. A score of 1 means it’s grounded, and there is a lower chance of hallucination.
Metric signal: Higher context adherence is correlated with higher output quality.
Examples:
Query: "What is the population of Paris, France?"
Retrieved docs:
Doc1: Census 2023 reported population of Paris to be 2.2 million.
Doc2: Census 2022 reported population of Paris to be 2.1 million.
Doc3: The population of Paris is more than 2 million.
High context adherence:
Response: "The population of Paris, France, according to the most recent census report, is approximately 2.2 million people."
In this example, the model's response is directly supported by the information present in the retrieved documents. It provides a specific population figure based on a reliable source, demonstrating groundedness.
Low context adherence:
Response: "Paris, France has a population of 10 million people."
In this example, the model's response is not grounded in the provided documents, and it seems to have fabricated a population figure that is not supported by the context.
2. Correctness
As the name suggests, correctness measures the factual correctness of the output. It was developed by Galileo, which leverages GPT-3.5 with chain of thought(CoT) prompting and self-consistency. It surfaces errors of precision and not recall. It is very useful for detecting hallucinations in different scenarios, like summarisation or open-domain QA.
Metric signal: Higher factuality is correlated with higher output quality.
Prompt: When did Aliens invade earth?
High factuality:
Response: Aliens have never invaded earth.
Low factuality:
Response: Aliens invaded earth on July 4th 2020.
3. LLM Uncertainty
A recent study has shown that log probability can help us find low quality generations. Uncertainty leverages the same philosophy as prompt perplexity but on the generated text. It is calculated by leveraging log probability given by the LLM for each generated token. For models like GPT-3.5 and GPT4 which do not give logprob, we use other models as proxy.
Metric signal: Lower LLM uncertainty is correlated with higher output quality.
Low uncertainty:
Prompt: “Where did the inventors of GPT3 architecture work?”
Response: “OpenAI”
The response here is correct and contains low uncertainty.
High uncertainty:
Prompt: “Where did the inventors of GPT5 architecture work?”
Response: “Deepmind”
The response here is incorrect and contains high uncertainty.
4. Prompt Perplexity
Prompt perplexity is simply the perplexity of the prompt given as input to the LLM. A recent study showed that the lower the perplexity of the prompt, the better suited the prompt is for the given task. High perplexity indicates lower understanding of the text which means the model has not understood the prompt. If the model is unable to understand its input (the prompt) it is more likely to generate poor outputs.
Metric signal: Lower prompt perplexity is correlated with higher output quality.
Low perplexity:
Translate the following English sentence into French: 'The quick brown fox jumps over the lazy dog.'
In this case, the prompt is clear and directly instructs the model on what task to perform. The model is likely to have a low perplexity because it can confidently understand and execute the translation task.
High perplexity:
"Can you, like, if you don't mind, convert to French for me? The quick brown fox jumps over the lazy dog.
In this example, the instruction is not very clear that it’s a translation task and does not highlight what is to be translated.
Metrics for Evaluating RAG Effectiveness


RAG refers to retrieval augmented generation where we add domain specific knowledge(DSK) in the prompt with the help of a search engine. This is required to make LLMs work with DSK which can be totally missing during its training on open web data. Let’s discuss metrics which help with improving the RAG system.
1. Context Relevance
Context relevance measures how relevant the context fetched was to the user query. Low score could be a sign of a bad doc chunking/retrieval strategy or of missing info. To address this, one would add more documents to context DB or change the retrieval indexing/retrieval strategy. This can help debug reasons for bad generations.
Metric signal: Higher context relevance is correlated with higher output quality.
Query: Please provide information about the impact of climate change on polar bears.
High context relevance:
Retrieved Documents:
Doc 1 title: "The Effects of Climate Change on Polar Bear Populations"
Doc 2 title: "Arctic Ecosystems and Climate Change"
Doc 3 title: "Polar Bear Conservation Efforts in a Warming World"
In this case, the context relevance is good because all three retrieved documents are directly related to the query about the impact of climate change on polar bears. T
Low context relevance:
Retrieved Documents:
Doc 1 title: "Polar bears are fascinating creatures living in the Arctic."
Doc 2 title: "Climate change is a global issue affecting various ecosystems."
Doc 3 title: "The significance of bears in cultural folklore."
In this example, there is an overlap of words like "polar bears" and "climate change" between the query and documents. However, the context relevance is low because none of the retrieved documents directly address the impact of climate change on polar bears.
2. Completeness
Completeness measures how thoroughly your model's response covers the relevant information available in the provided context. Completeness and Context Adherence work in tandem to ensure that the model's response is both consistent with the context and comprehensive in addressing all relevant information.
Context Adherence vs. Completeness: Context Adherence evaluates whether the model's response is consistent with the information in the context, while Completeness assesses whether all relevant information in the context is adequately addressed in the response. In essence, Context Adherence represents precision, whereas Completeness represents recall.
Metric signal: Higher context similarity is correlated with higher output quality.
Examples:
User Query: "Who was Galileo Galilei?"
Context: "Galileo Galilei was an Italian astronomer. Galileo was the first to see the Milky Way Galaxy in 1610 as individual stars through the telescope."
Low completeness
Generated Answer: "Galileo Galilei was Italian."
In this example, the model's response achieves perfect Context Adherence because the context supports everything it states. However, the response lacks completeness because it fails to mention that Galileo Galilei was an astronomer, which is relevant information provided in the context.
High completeness
Generated Answer: "Galileo Galilei was Italian astronomer."
In this example, the model's response achieves perfect completeness.
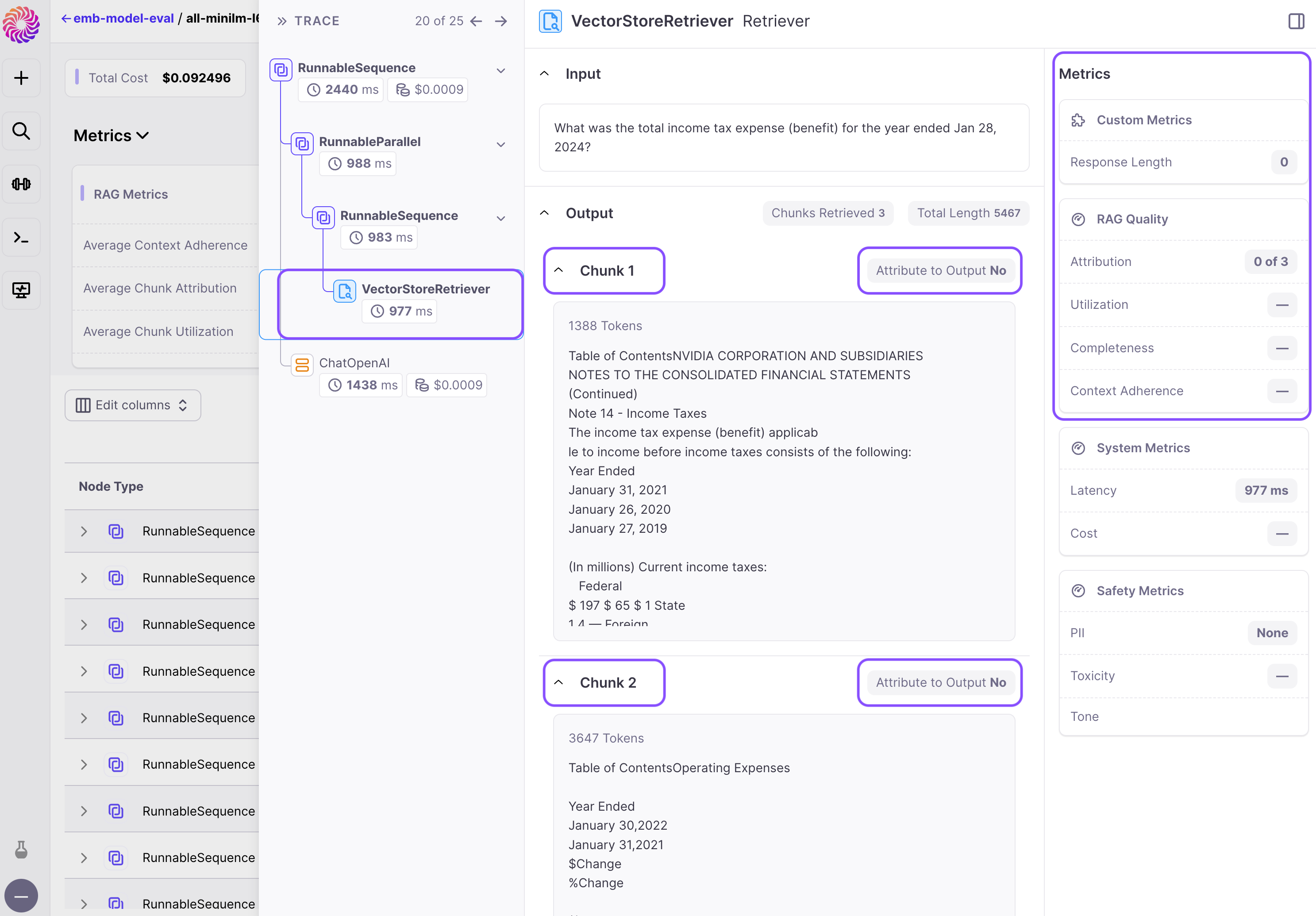
3. Chunk Attribution
Chunk Attribution measures whether each retrieved chunk affected the model's response. It is a binary metric, classifying each chunk as either Attributed or Not Attributed.
Chunk Attribution offers valuable insights for optimizing RAG pipelines in various ways:
1. Tuning the number of retrieved chunks: If the system generates satisfactory responses but many chunks are Not Attributed, reducing the number of retrieved chunks per example may enhance efficiency without compromising response quality. This optimization can lead to cost savings and reduced latency.
2. "Debugging" anomalous model behavior in individual examples: When analyzing specific model responses that are unsatisfactory or unusual, Chunk Attribution helps identify the chunks that influenced the response. This facilitates a quicker understanding of the underlying factors contributing to the issue, streamlining the debugging process for individual examples.
Metric signal: Higher chunk attribution is correlated with higher output quality.
Example:
Query: "Tell me about the discoveries of Galileo Galilei."
Retrieved Chunks:
Chunk 1: "Galileo Galilei was an Italian physicist, mathematician, and astronomer."
Chunk 2: "Galileo's telescopic observations supported the Copernican heliocentric model of the solar system."
Chunk 3: "He discovered the four largest moons of Jupiter, now known as the Galilean moons."
High chunk attribution:
Generated Answer: "Galileo Galilei, an Italian physicist, mathematician, and astronomer, made significant discoveries that reshaped our understanding of the universe. His telescopic observations provided evidence for the Copernican heliocentric model and led to the discovery of the four largest moons of Jupiter, now known as the Galilean moons."
In this case, all retrieved chunks are attributed since each contributes essential information to the model's response. Therefore, each chunk affected the generated answer, indicating high Chunk Attribution.
Low chunk attribution:
Query: "What was Galileo Galilei's nationality?"
Retrieved Chunks:
Chunk 1: "Galileo Galilei was an Italian physicist, mathematician, and astronomer."
Chunk 2: "Galileo's telescopic observations supported the Copernican heliocentric model of the solar system."
Chunk 3: "He discovered the four largest moons of Jupiter, now known as the Galilean moons."
Generated Answer: "Galileo Galilei was born in Pisa in 1564."
In this example, none of the retrieved chunks directly addresses Galileo Galilei's nationality. Although Chunk 1 mentions that he was Italian, the model's response does not incorporate this information. Therefore, none of the retrieved chunks significantly influenced the model's response regarding Galileo Galilei's nationality, indicating that they are Not Attributed.
4. Chunk Utilization
Chunk Utilization measures the fraction of text in each retrieved chunk that is used for model's response. It ranges from 0 to 1, where a value of 1 indicates that the entire chunk affected the response, while a lower value, such as 0.5, suggests that some text within the chunk did not contribute to the response. Low chunk utilization scores indicate that the chunks retrieved may be longer than necessary.
Metric signal: Higher chunk utilization is correlated with higher output quality.
High chunk utilization
User Query: "What are the main ingredients used in making pizza?"
Retrieved Chunk:
Chunk 1: "Pizza, a popular Italian dish, typically consists of a flattened bread base topped with tomato sauce, cheese, and various toppings. The base is traditionally made from wheat flour, water, yeast, salt, and olive oil. Tomato sauce, often seasoned with herbs and spices, serves as the primary topping, while mozzarella cheese is commonly used for its melting properties. Additional toppings may include meats such as pepperoni, vegetables like mushrooms and bell peppers, and other ingredients based on regional preferences."
Generated Answer: "Pizza typically consists of a flattened bread base topped with tomato sauce, cheese, and various toppings. The base is traditionally made from wheat flour, water, yeast, salt, and olive oil. Tomato sauce, often seasoned with herbs and spices, serves as the primary topping, while mozzarella cheese is commonly used for its melting properties. Additional toppings may include meats such as pepperoni, vegetables like mushrooms and bell peppers, and other ingredients based on regional preferences."
In this example, the retrieved chunk provides comprehensive information about the main ingredients used in making pizza, including details about the bread base, tomato sauce, cheese, and various toppings. The model's response utilizes the entire chunk effectively, as all the information contributes directly to answering the user query about pizza ingredients. Therefore, the chunk utilization is high.
Low chunk utilization
User Query: "What is the population of Tokyo, Japan?"
Retrieved Chunk:
Chunk 1: "Tokyo, officially Tokyo Metropolis, is the capital and most populous prefecture of Japan. It is the political, economic, and cultural center of the country. Tokyo is one of the 47 prefectures of Japan, consisting of 23 central city wards and multiple cities, towns, and villages west of the city center. The population of the Tokyo Metropolis is approximately 14 million people, making it one of the most populous urban areas in the world."
Generated Answer: "The population of the Tokyo Metropolis is approximately 14 million people."
In this example, the model's response only utilizes a small portion of the chunk, focusing solely on the population figure. Despite the chunk being attributed to the response, the utilization is low because the majority of the text in the chunk is not directly relevant to answering the user query.
Metrics for Evaluating Safety


Safety metrics are essential tools used to evaluate and maintain the safety and integrity of AI models and systems. These metrics encompass various aspects of safety, including the identification and mitigation of potential risks such as the presence of sensitive information, toxic content, inappropriate tones, sexism, and malicious prompt injections. By systematically assessing these factors, safety metrics play a crucial role in safeguarding users and promoting responsible AI deployment.
PII
The PII (Private Identifiable Information) metric identifies instances of PII within a model's responses, specifically flagging sensitive information such as addresses, credit card details, dates, emails, names, network information, personal identification (ID), passwords, phone numbers, social security numbers (SSN), and usernames.
This metric automatically detects and flags responses containing PII, enabling the implementation of guardrails or other preventative measures to protect user privacy and prevent potential security breaches.
Toxicity
The Toxicity metric flags whether a response contains hateful or toxic content. It provides a binary classification indicating whether a response is toxic or not.
By identifying responses with toxic comments, this metric facilitates the implementation of measures such as fine-tuning models or implementing guardrails to flag and mitigate toxic responses, ensuring a safer and more respectful user experience.
Tone
The Tone metric classifies the emotional tone of a response into nine different categories, including neutral, joy, love, fear, surprise, sadness, anger, annoyance, and confusion.
By categorizing the emotional tone of responses, this metric enables the alignment of responses with user preferences. It allows for optimization by discouraging undesirable tones and promoting preferred emotional responses, thereby enhancing user satisfaction.
Sexism
The Sexism metric flags whether a response contains sexist content. It provides a binary classification indicating whether a response is sexist or not.
This metric helps identify responses containing sexist comments, allowing for preventive measures such as fine-tuning models or implementing guardrails to flag and mitigate sexist responses, fostering a more inclusive and respectful environment.
Prompt Injection
The Prompt Injection metric identifies instances of prompt injection within a model's input, including attacks such as simple instruction attacks, few-shot attacks, impersonation, obfuscation, and context switching.
By automatically detecting and classifying user queries with prompt injection attacks, this metric enables the implementation of guardrails or other preventative measures to mitigate potential risks and ensure the model operates within intended parameters, enhancing safety and reliability.
Custom Evaluation Metrics
We acknowledge that the metrics listed above may not cover all scenarios comprehensively. For instance, LLMs can produce outputs with multiple predictions, necessitating custom metrics for evaluating various aspects of these outputs. Certain applications demand LLM-based chatbots to maintain a specific tone, as deviations can prompt user dissatisfaction. Additionally, developers may seek to identify specific words associated with errors within the outputs. These specialized requirements fall under the umbrella of custom metrics, addressing the diverse range of use cases beyond standard evaluation metrics.
Final thoughts
Over the span of three years, Galileo has been deeply immersed in the study of language model metrics. With Galileo Evaluate, harnessing these metrics for swift experimentation is effortless. You gain immediate access to a concise overview of all runs, facilitating the identification of your top-performing setup. Moreover, the option to craft custom metrics tailored to your precise requirements is at your fingertips for unique applications.

Galileo GenAI Studio is the leading platform for rapid evaluation, experimentation and observability for teams building LLM powered applications. It is powered by a suite of metrics to identify and mitigate hallucinations. Get started today!
Explore our research-backed evaluation metric for hallucination – read our paper on Chainpoll.
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
