HP + Galileo Partner to Accelerate Trustworthy AI
Building High-Quality Models Using High Quality Data at Scale




The goal of any person practicing machine learning (ML) in the industry today is very simple: produce high-quality models and do it fast. But the reality is that each ML project takes months, from identifying the problem and the use case to deploying the model in production. Some ML teams focus on deploying just one model for the whole quarter. Even though we've made progress in model frameworks and platforms that let us train and deploy models with the click of a button, this is still the sad reality.
This article will teach you some high-level guiding principles that frame the building of a platform that helps curate high-quality models through high-quality datasets.
High-Quality Models Depends On High-Quality Data
One neglected aspect of building high-quality models is that it depends on one crucial entity: high-quality data. Good quality data in ML is the most significant impediment to seamless ML adoption across the enterprise. The difference between productionizing one model every quarter and the pipe dream of productionizing models on a daily or even hourly basis is high-quality data.

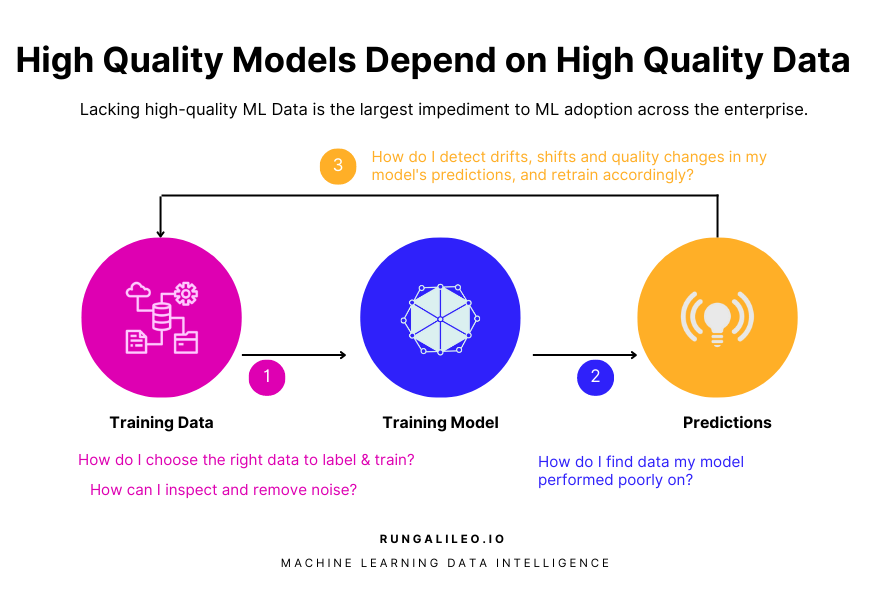
High Quality Data Is the Largest Impediment To ML Adoption Across the Enterprise
There's some key questions an ML practitioner typically asks at different stages of the ML workflow. Here's some of those questions listed below:
- [Pre-training] How do I select what data and features to train and what data to label? And once selected, how do I inspect and remove unneeded or noisy data from it?
- [Post-training] How do I find data my model performed poorly on?
- [Post-production] How do I detect drifts, shifts, and quality changes in my model’s predictions and assert signals for retraining?
Challenges in the Modern-day ML Workflow
The first step in answering the above questions is to figure out what problems are happening with the modern ML workflow.


Challenge 1: Dataset Curation during pre-training
The first two phases revolve around identifying the use case and the problem, and selecting the data you want to train the model on and label. The overarching umbrella of issues in this phase of ML are essentially "data curation" issues. In this phase, the goal is to construct an ideal dataset for training and evaluating your model.

Most real-world data sets have problems with annotation errors, class imbalance, noisy data, and redundant features. Redundant features add the same amount of information to both the label and the model. Sometimes, you'd cherry-pick and remove 80% or more features from your data, and the model would still perform the same.
Challenge 2: Dataset Fixing during Training & Evaluation
This is part of the training phase, where you do custom feature engineering to fit the data to the model. Over the years, the amount of model tuning code has been reduced to a minimum because of advancements in hyperparameter optimization and tuning techniques. The amount of code you write depends on whether you are doing custom feature engineering in the prefix phase of your model.

In this phase, the issues relate to identifying the low-performing regions in your data—the data that degrades your model's performance. Some of the issues include low-performing segments of the data, class boundary overlaps that are close to your decision boundaries and confuse the model, uncertain (or mislabeled) samples, and biases in the data.
In this phase, the goal is to find these issues and fix the data set in as few steps as possible. You want to do it in a few steps so that they are easy to replicate for production or new data.
Challenge 3: Model Freshness in Production
Once the model is deployed and meets the real world, there's a shift in traffic patterns. You can categorize issues in this phase as "model freshness issues." Some of the critical observations I've made in my many years of building these kinds of platforms are that there are frequently very interesting correlations between some of the model metrics and some system metrics.
For example, there could be interesting correlations you would find when you look at high latency model predictions and compare them to low latency predictions. The goal here is to detect and fix issues that would degrade the model’s performance in production.

Principles of Building High Quality ML Datasets
We have established five principles for curating high-quality ML datasets:
- Understand your data is key.
- With data, less is more.
- Evauate your models on a hybrid set of performance metrics.
- Understand the limitations of your models.
- Actionability is key.
Principle 1: Understand your data is key
Before you stitch together a DataFrame of features and labels that you want to fit to the model, it's very important to understand how your data is distributed. From an unstructured data perspective, it essentially means getting a good sense of the semantic coverage of the data. This includes the key semantic topics covered in your data set, how many of those are outliers, how much noise exists in the data, and how much data is semantically confusing to the model, because they can degrade the model’s performance.
Here’s a table showing some important considerations to make in understanding both structured and unstructured datasets:

If you work with unstructured data, particularly NLP data, you can use embeddings, which are vector representations of data that can be reduced to a 2D space for visualization. To generate a key understanding of the data you are working with, it helps to investigate and identify erroneous clusters through the visualization, zeroing in on them, and then removing them from the data set.
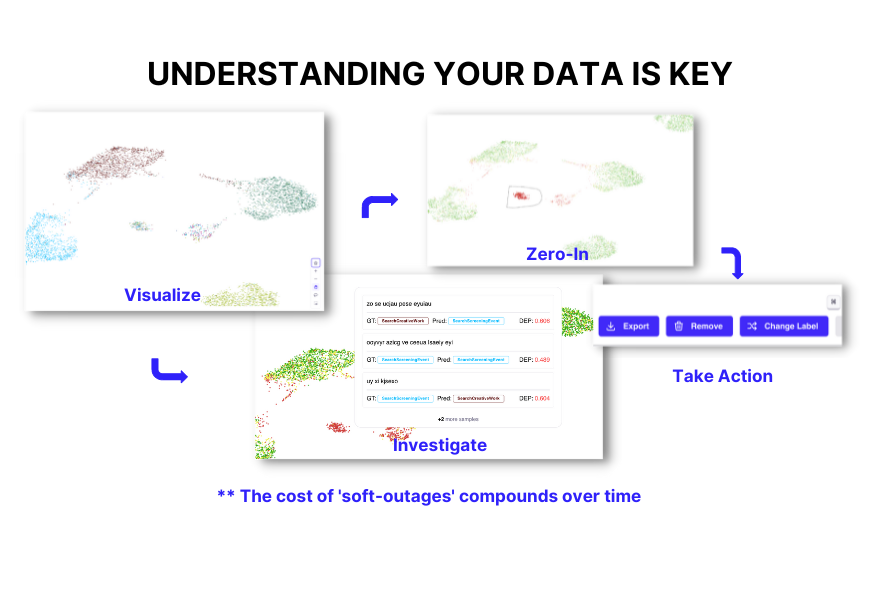
One term I have used in my many years of building these machine learning platforms is "soft outage." A soft outage is an error that happens because your data has biases and other problems that you don't know about. They compound over time and are very challenging to find because they are so hidden in the data. Once they are part of your model after training and testing, they are so subtle and hard to see that not even software can detect them, let alone the modeler.
The outcome of soft outages is bad predictions that bring down your downstream consumer systems, and eventually, they affect your business. It's critical to identify these issues early on in the workflow so that they don't compound downstream.
Principle 2: With data, less is more
There needs to be a focus on quality over quantity. One of the reasons for soft outages is also too much data. The problem with large quantities of data is that the more data there is, the greater the likelihood of errors and biases in the data, the higher your labeling costs, and the greater the proclivity to have multiple large numbers of classes, which would lead to class confusion. With unstructured data, for example, it's better to focus on semantic representation and optimal class coverage than just piling up tons of them.
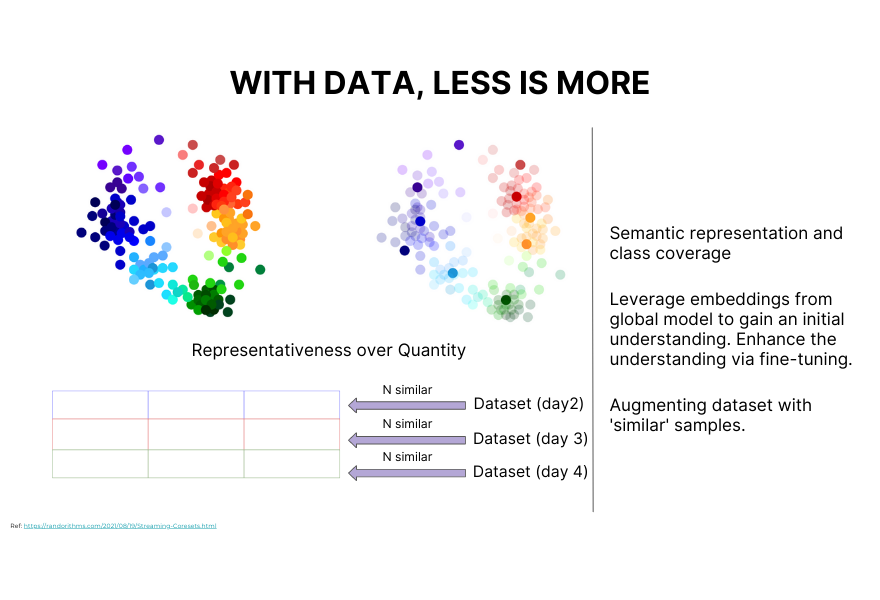
In practice, I've had good results when I use the power of pre-trained embeddings to get a general understanding of our data and then augment that in an active learning environment. The goal is to get a more accurate representation of your use case. With the active learning technique, you can systematically augment your data set by cherry-picking the data samples you need from different partitions of the data set.
To give a more practical example, say you have a data set for a single day of data. You can get similar examples in bulk from different partitions of that data, which can be from different days. That's how you systematically construct a minimal but high-value data set for your model.
Principle 3: Evaluate your models on a hybrid set of performance metrics
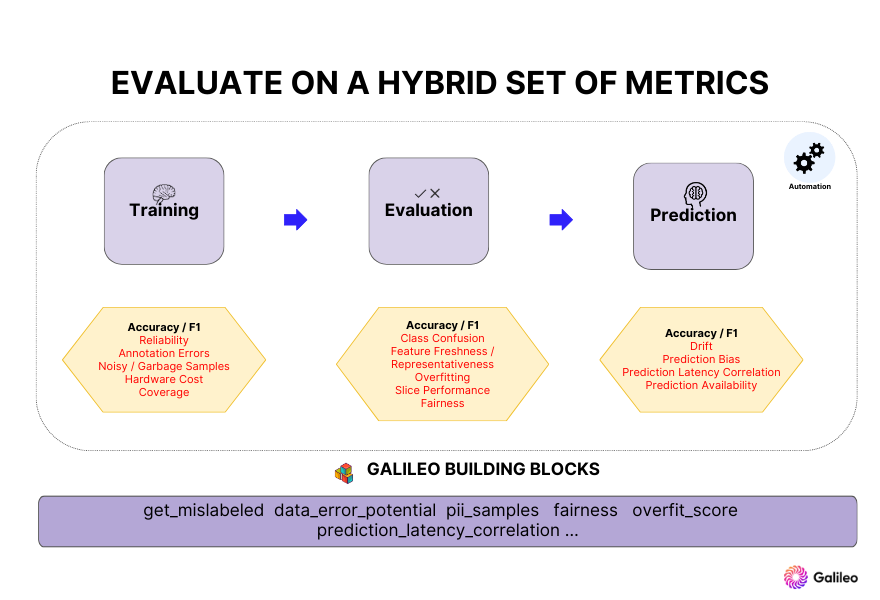
This is the most important feature of a good machine learning platform: being able to evaluate a model on a hybrid set of metrics. The health of a model is determined by metrics that go beyond the standard accuracy measures like Precision and F1 scores.
There are key metrics to keep an eye on depending on where you are in the ML workflow, and often these metrics are metrics that we measure for traditional software systems. For example, prediction latency, which is the end to end time it takes for a model to deliver a prediction to the caller. Correlations of prediction latency to a model's accuracy or the importance of a feature can showcase interesting trends and point you to specific features to focus more of your time on. The root observation from which this principle arises is the fact that an ML system is 10% mode code and 90% a software engineering system around it.
To enable a user to evaluate on a multitude of metrics, at Galileo, we've built the ability to measure these using what we call building block modules. These modules can be applied to a model at any phase of the model's life cycle. The system is designed in a modular way to allow a user to monitor and observe on a custom combination of key metrics that they can choose.
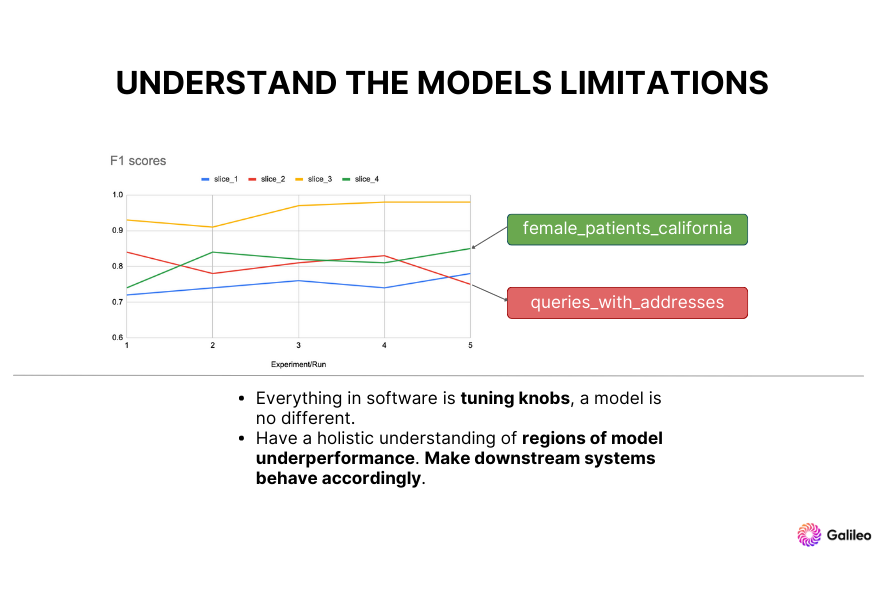
Principle 4: Understand the limitations of your models
A model is just like any other software artifact. In the same way that you can get balanced delivery of a software artifact like an API or a microservice by tuning different parameters to get the best performance, the same principles hold true for a model. For example, transformations in your machine learning data can improve the model’s accuracy for a slice of data but then regress the performance of a different cluster of data.
It's crucial to have a holistic understanding of which segments of the data your model might perform well on and which it might not, so that you can set up your monitoring and downstream systems accordingly.
Principle 5: Actionability is critical
It's not enough to just have a system that monitors and observes key features or model prediction metrics; you also need to be able to pinpoint the segment of data that led to the particular issue and suggest the action that is to be taken upon it. That is the hallmark of a good observability system.
We've built out these building blocks, which play a crucial role in systematically pinning down the erroneous segments of your data. Through the Galileo SDK, one can easily declare predicates and conditions using code and define the actions that they want to take upon meeting those conditions.
This is an essential next step for every next-generation ML platform. Not only should they be able to move a model from development to deployment, but they should also be able to monitor the model's quality, detect issues, and fix them automatically.
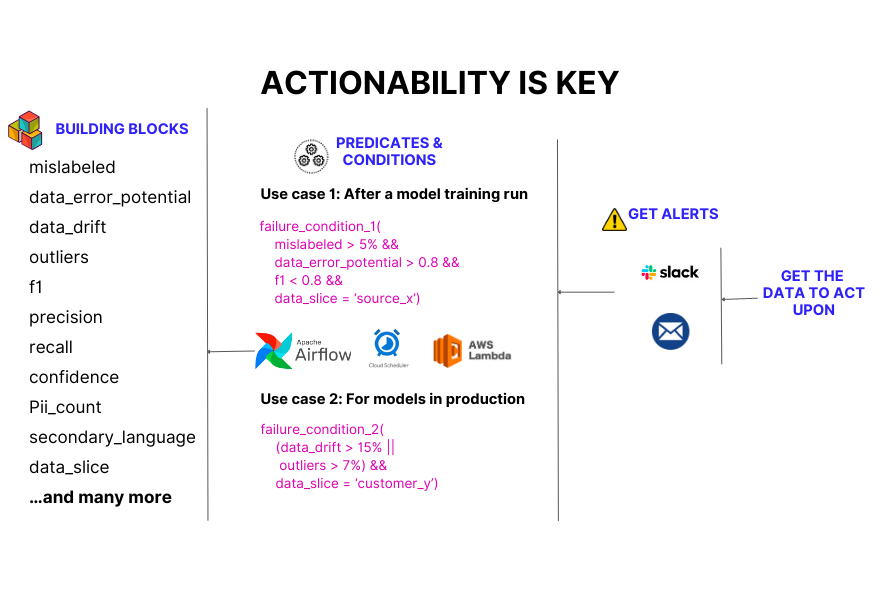
You should not just be able to detect issues but also be given actionable steps to fix them yourself or automatically with your stack.
Applying These Principles to One Platform: Galileo!
Many businesses of different sizes have used Galileo, and some of the results and improvements we've seen have been model performance improvements in the double-digit range. Here are some of the impact metrics we hear:
- 6-15% accuracy improvements in average model performance during training and evaluation,
- Detected and fixed 40% more data errors,
- 10 times faster model productionization with streamlined cross-team collaboration (across engineering, product teams, and other stakeholders). Also, providing automation APIs for automating ML workflows to help maintain models without constant debugging and manual efforts.
Galileo established rigor and efficiency in your team’s processes, so it’s a no-brainer that model productionization can go from many days to a couple of hours for teams leveraging it for ML data intelligence.
If you want to try out Galileo, sign up for free here.
This article is based on an excerpt from my talk at the DCAI Summit 2022 on building high-quality models with high-quality data at scale. Catch the entire talk on YouTube.
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
