All New: Evaluations for RAG & Chain applications
Announcing LLM Studio: A Smarter Way to Build LLM Applications




Join us on October 4th for a closer look at LLM Studio. Register here!
Since Day 1, Galileo has been focused on helping teams unlock the power of unstructured data. Through our experience creating the earliest versions of Siri at Apple, building language models with billions of parameters at Google Speech, and making the first NLP-powered products at Google AI, Atin, Yash, and I experienced the rise of language models first-hand. Through these experiences, we realized the need for an ML developer platform like Galileo.
Until recently, Galileo was focused on NLP and CV. However, as language models became “large language models,” we found understanding what happens inside the LLM black box was becoming increasingly difficult. From small startups to Fortune 50 brands, we saw teams struggling to evaluate and manage the large amounts of data, prompts, and context needed to train and maintain LLMs.
The Challenges of Handling Really Large Language Models
And now, with large language models (LLMs) increasing in size and popularity, we’ve seen new needs emerge. LLM-powered apps have a different development lifecycle than traditional NLP-powered apps – prompt experimentation, testing multiple LLM APIs, RAG and LLM fine-tuning. In speaking with customers across financial services, healthcare, and AI-native companies, it became clear LLMs require a new development toolchain.
Namely, we found the three biggest challenges facing LLM developers today were:
- The need for holistic evaluation – Traditional NLP metrics no longer apply, making manual, painstaking, and error-prone human analysis the norm.
- The need for rapid experimentation – Making LLMs production-ready requires trying a dozen variations of prompts, LLMs, and parameters. Managing hundreds of permutations in notebooks or sheets makes experimentation ineffective and untenable.
- The need for actionable observability – When models meet the world, constant attention is mandatory. LLMs hallucinate and the need to monitor this unwanted behaviour via scientific metrics and guardrails is critical.
To help teams overcome these challenges, we’re excited to announce our latest product, LLM Studio.
Introducing Galileo LLM Studio
LLM Studio helps you develop and evaluate LLM apps in hours instead of days. It’s designed to help teams across the application development lifecycle, from evaluation and experimentation during development to observability and monitoring once in production.
LLM Studio offers three modules - Prompt, Fine-Tune, and Monitor - so whether you’re using RAG or fine-tuning, LLM Studio has you covered.
1. Prompt
Prompt engineering is all about experimentation and root-cause analysis. Teams need a way to experiment with multiple LLMs, their parameters, prompt templates, and context from vector databases.

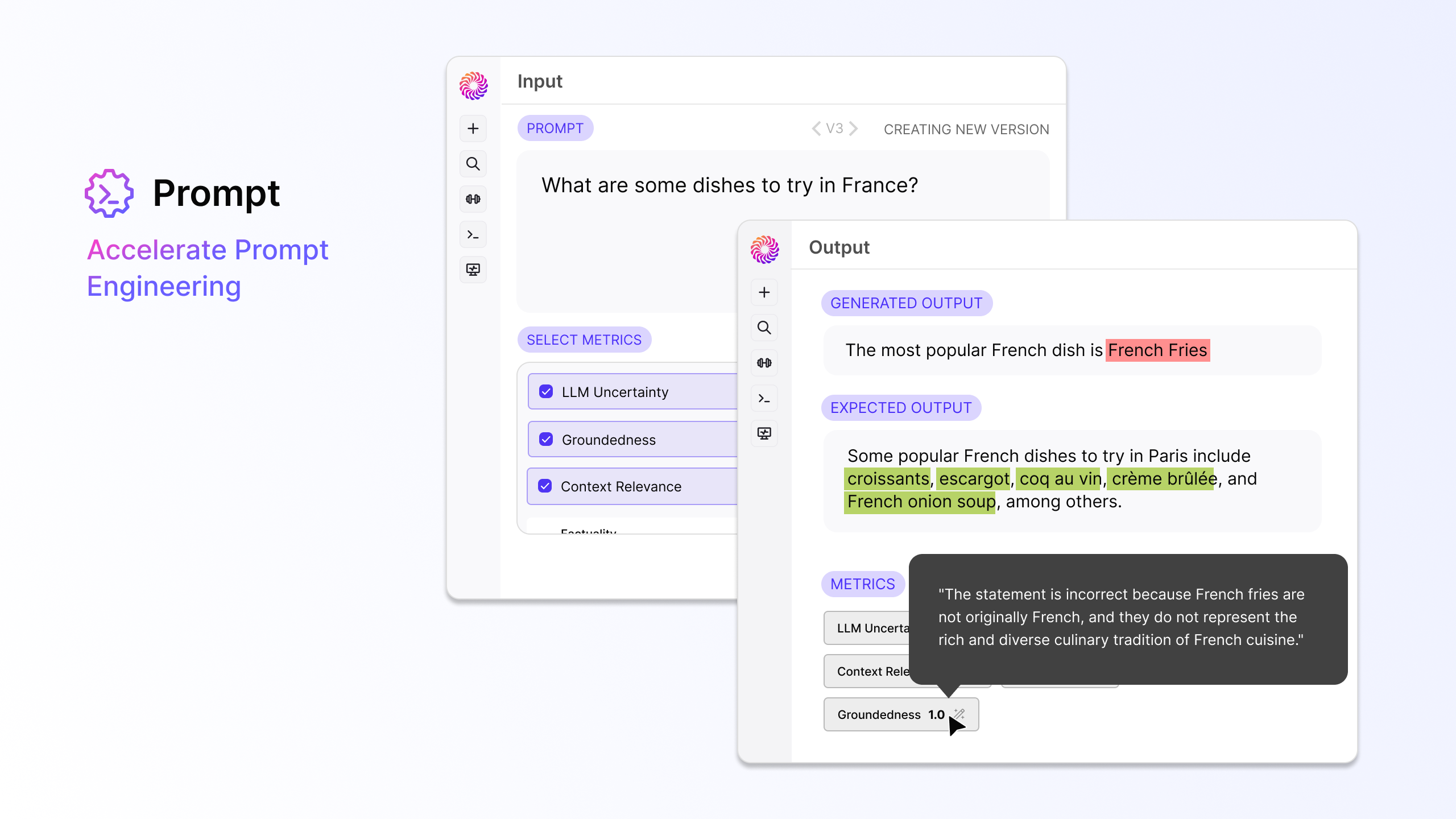
Our Prompt module helps you systematically experiment with prompts in order to find the best combination of prompt template, model, and parameters for your generative AI application. We know prompting is a team sport, so we’ve built features to enable collaboration with automatic version controls. Teams can use Galileo’s powerful suite of evaluation metrics to evaluate outcomes and detect hallucinations.
2. Fine-Tune
When fine-tuning an LLM, it is critical to leverage high-quality data. However, data debugging is painstaking, manual, and needs a bunch of iterations – moreover, leveraging labeling tools here balloons cost and time.
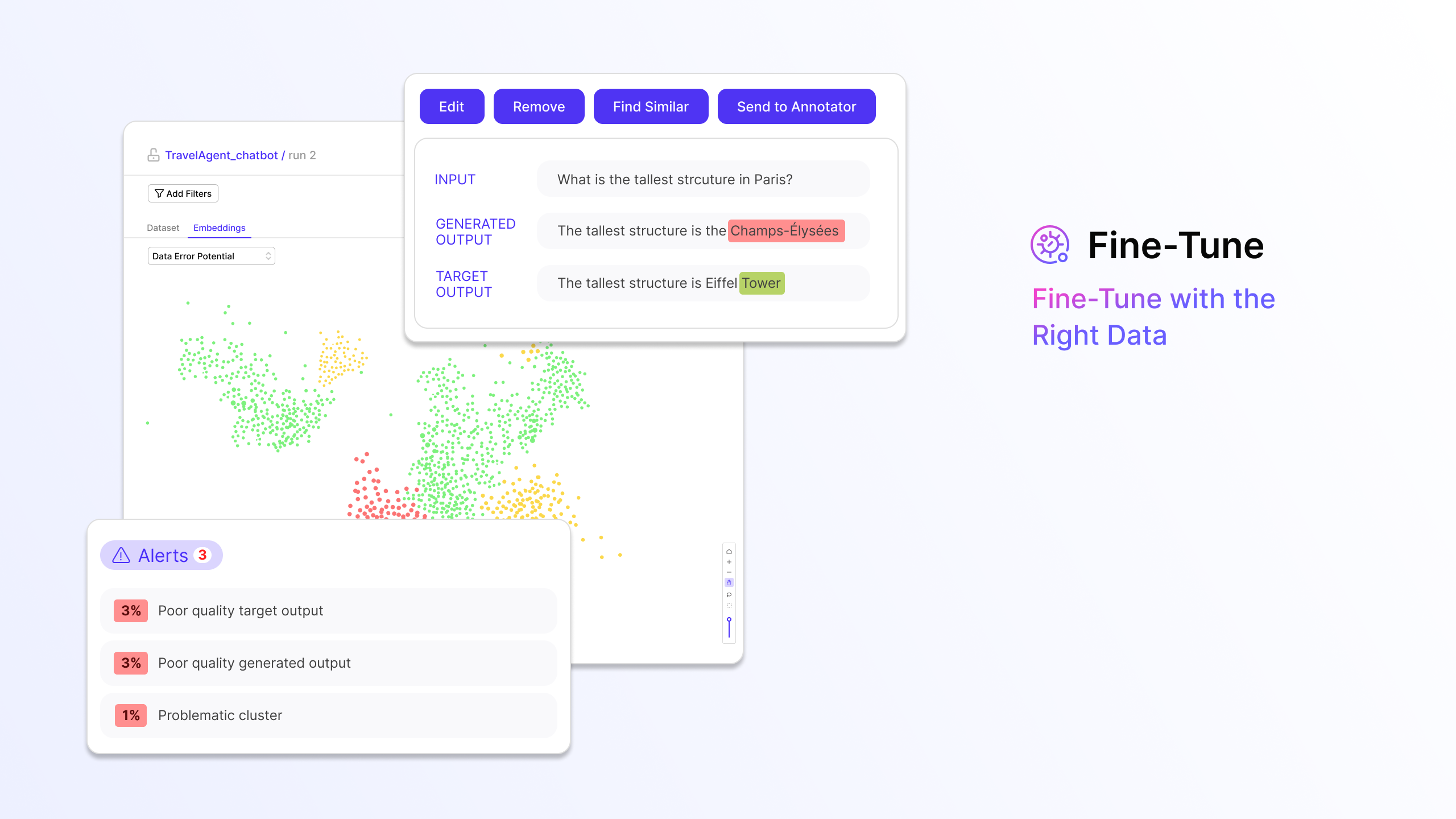
The Fine-Tune module is an industry-first product built to automatically identify the most problematic training data for the LLM – incorrect ground truth, regions of low data coverage, low-quality data, and more. Coupled with collaborative experiment tracking and 1-click similarity search, Fine-Tune is perfect for data science teams and subject matter experts to work together towards building high-quality custom LLMs.
3. Monitor
Prompt engineering and fine-tuning are half the journey. Once an application is in production and in end-customers’ hands, the real work begins. Generative AI builders need governance frameworks in place to minimize the risk of LLM hallucinations in a scalable and efficient manner. This is especially important as generative AI is still in the early innings of winning end-user trust.
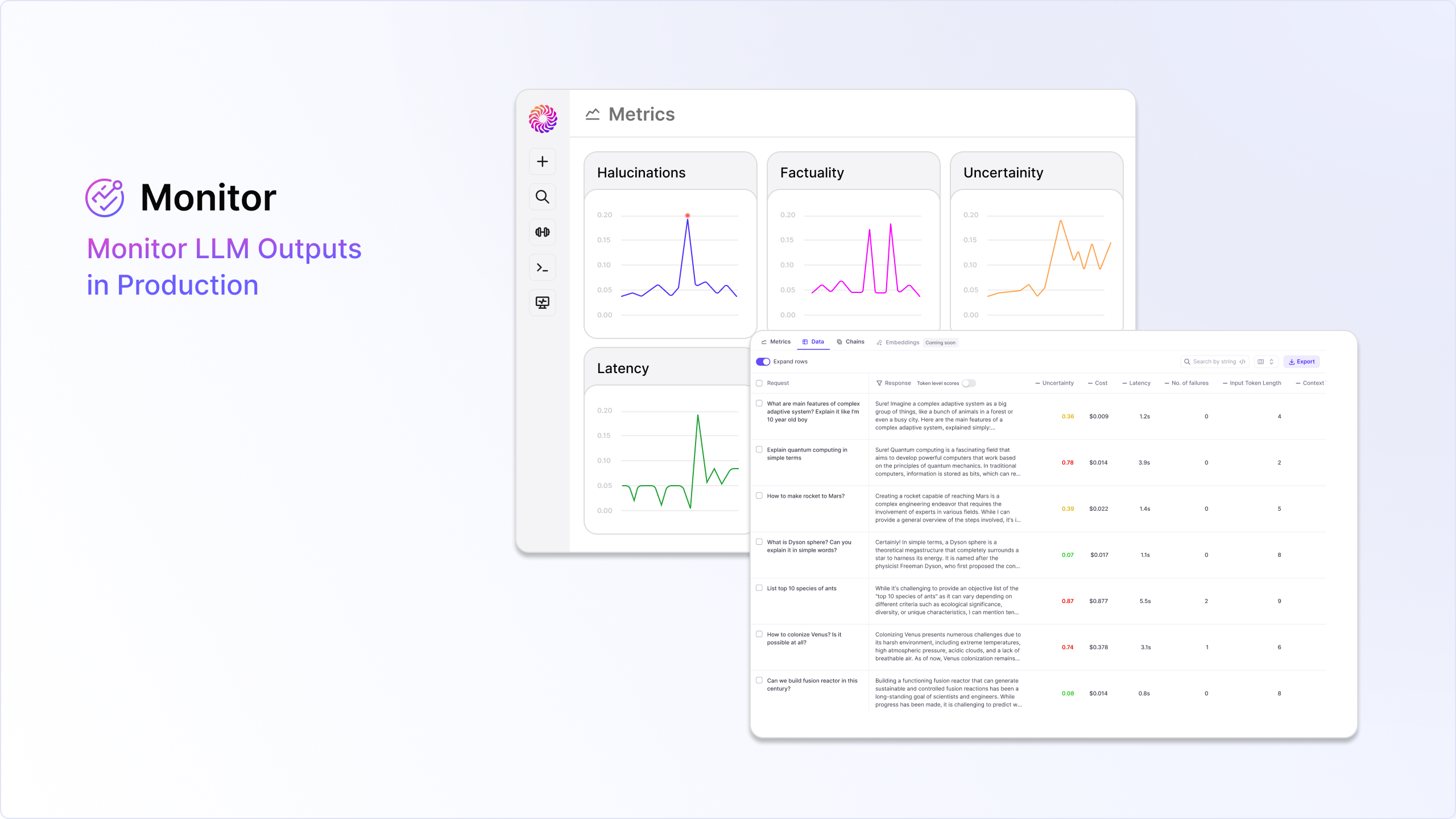
To help with this, we’ve built Monitor, an all-new module that gives teams a common set of observability tools and evaluation metrics for real-time production monitoring. Apart from the usual tracing available, Monitor ties application metrics like user engagement, cost, and latency to ML metrics used to evaluate models and prompts during training, like Uncertainty, Factuality, and Groundedness. Teams can set up alerts so they can be notified and conduct root-cause analysis the second something seems off.
A Common Platform to Drive Continuous Improvement
While each of these modules provides value in its own right, the greatest value-unlock comes from these modules operating on a single fully integrated platform.
A core principle here at Galileo is ‘Evaluation First’ - everything starts and ends with the ability to evaluate and inspect your application. Since Day 1, our goal has been to give teams simple and powerful governance frameworks to improve application performance and minimize risk. This is why we’ve developed a Guardrail Metrics Store - equipped with a common set of research-backed evaluation metrics that users can use across Prompt, Fine-Tune, and Monitor.
Our Guardrail Metrics include industry-standard metrics (e.g. BLEU, ROUGE-1, Perplexity) and powerful new metrics from Galileo's in-house ML Research Team (e.g. Uncertainty, Factuality, Groundedness). You can also define your own custom evaluation metrics. You can dig into these metrics in our latest blog.
Together, these metrics help teams minimize the risk of LLM hallucinations and bring more trustworthy applications to market.
Built for the Enterprise
Last but certainly not least, LLM Studio has been built with enterprise needs in mind.
Privacy first – Galileo is built for teams that want complete ownership and residency of their data. LLM Studio is SOC2 compliant, with HIPAA compliance on the way, and offers hybrid on-prem deployments, to ensure your data never leaves your cloud environment.
Highly customizable – The LLM landscape evolves fast, and LLM Studio is built to scale with the thriving ecosystem, via support for custom LLMs, custom metrics, and powerful APIs that work with all your tools.
Quick to get started – LLM Studio is built from the ground up with data science teams and human evaluation in mind. Get started in minutes with a few lines of Python code, or directly through our intuitive UI.
The best part? We’re just getting started! We are excited to finally have LLM Studio Generally Available and in the hands of our valued customers and we have plenty of exciting enhancements on the way.
If you are interested in learning more, reach out to try LLM Studio today and join us for our webinar on October 4 where we’ll dive deeper into the platform.
Thank you,
Vikram 👋
🍿 P.S. Be sure to check out our LLM Studio overview video!
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
