HP + Galileo Partner to Accelerate Trustworthy AI
Mastering RAG: Improve RAG Performance With 4 Powerful RAG Metrics




Explore our research-backed evaluation metric for RAG – read our paper on Chainpoll.
Retrieval Augmented Generation (RAG) has become the technique of choice for domain-specific generative AI systems. But despite its popularity, the complexity of RAG systems poses challenges for evaluation and optimization, often requiring labor-intensive trial-and-error with limited visibility.
So, how can AI builders improve the performance of their RAG systems? Is there a better way? Before we dive into a powerful, new cutting-edge approach, let’s recap the core components of a RAG system and why teams choose RAG to begin with.
A Brief Intro To RAG

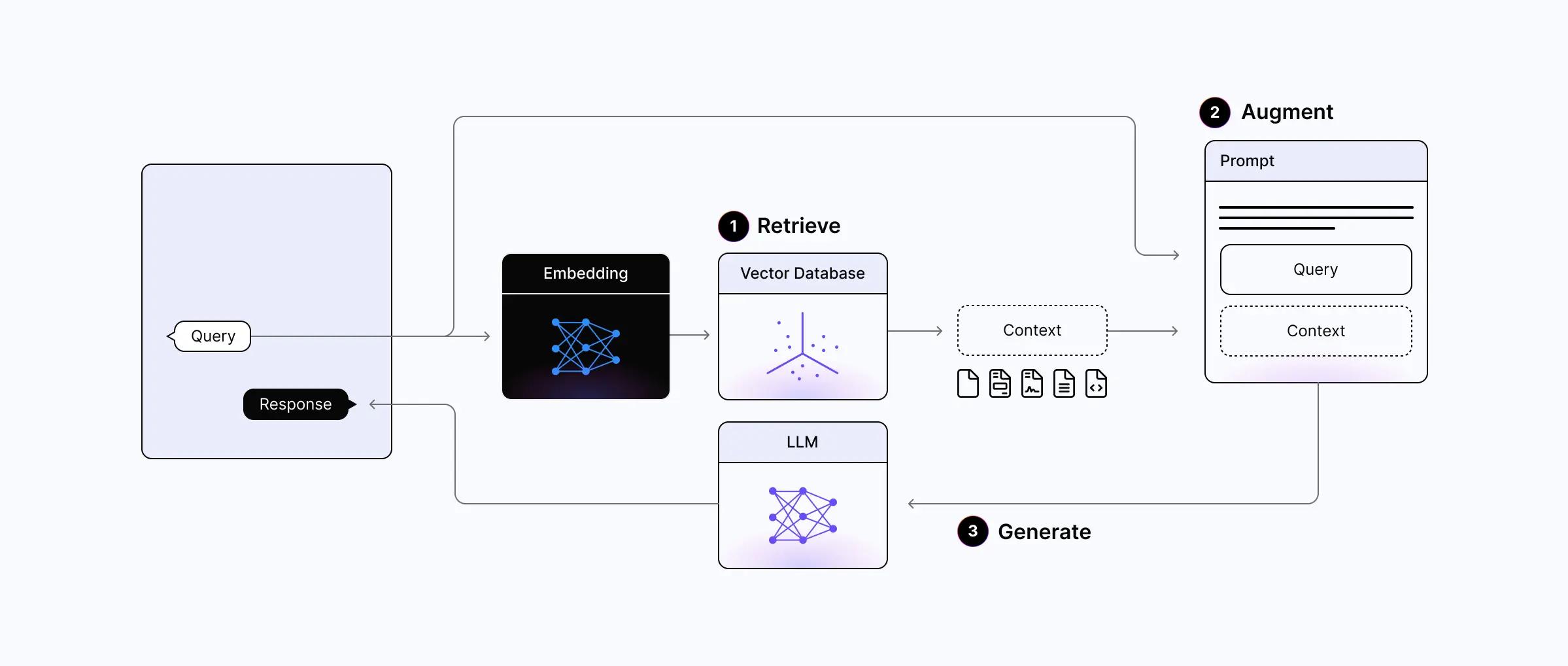
Let’s start with a basic understanding of how a RAG system works.
RAG works by dynamically retrieving relevant context from external sources, integrating it with user queries, and feeding the retrieval-augmented prompt to an LLM for generating responses.
To build the system, we must first set up the vector database with the external data by chunking the text, embedding the chunks, and loading them into the vector database. Once this is complete, we can orchestrate the following steps in real time to generate the answer for the user:
Retrieve: Embedding the user query into the vector space to retrieve relevant context from an external knowledge source.
Augment: Integrating the user query and the retrieved context into a prompt template.
Generate: Feeding the retrieval-augmented prompt to the LLM for the final response generation.
An enterprise RAG system consists of dozens of components like storage, orchestration and observability. Each component is a large topic in itself which requires its own comprehensive blog. Thankfully, we’ve written just that earlier in our Mastering RAG series.

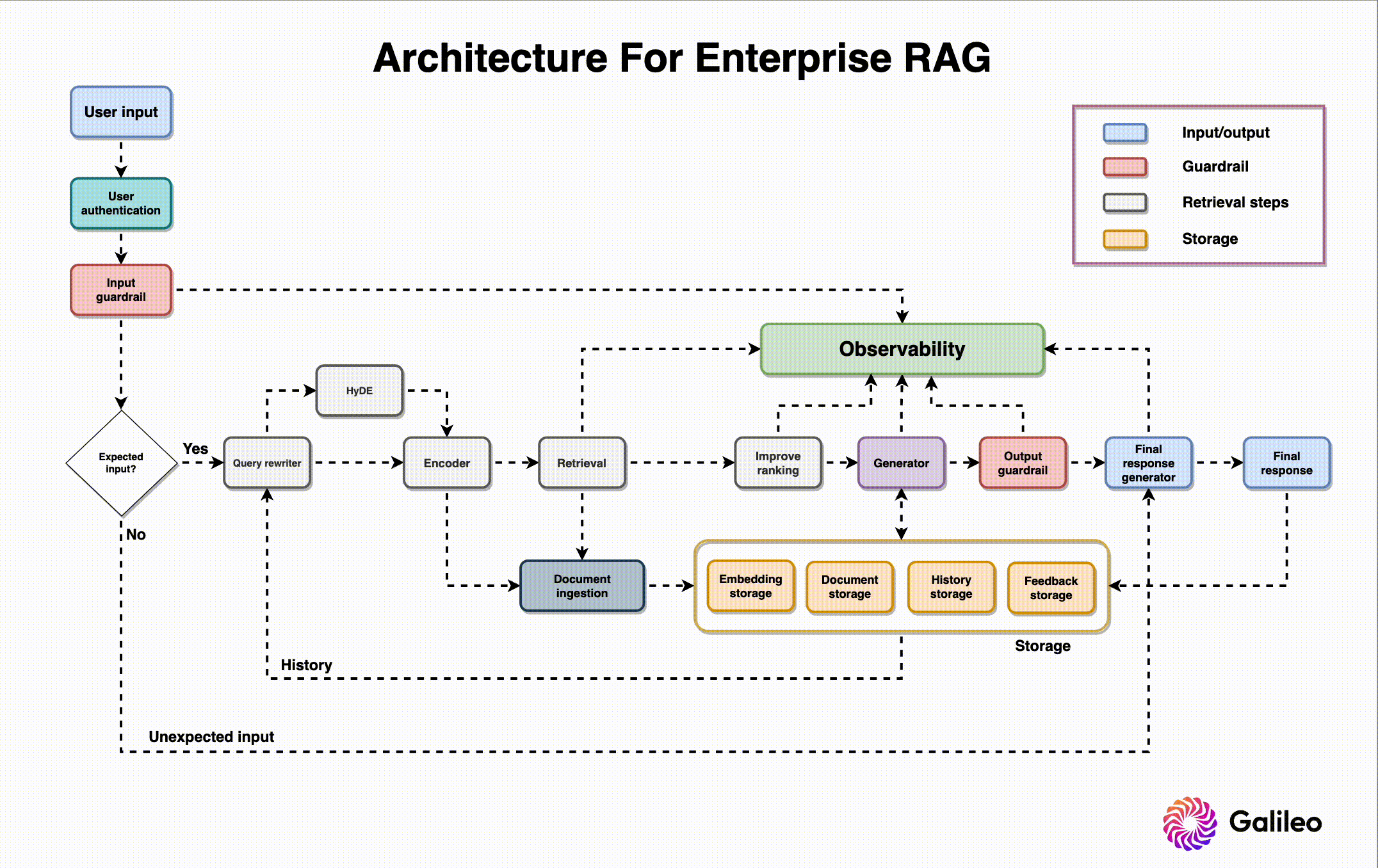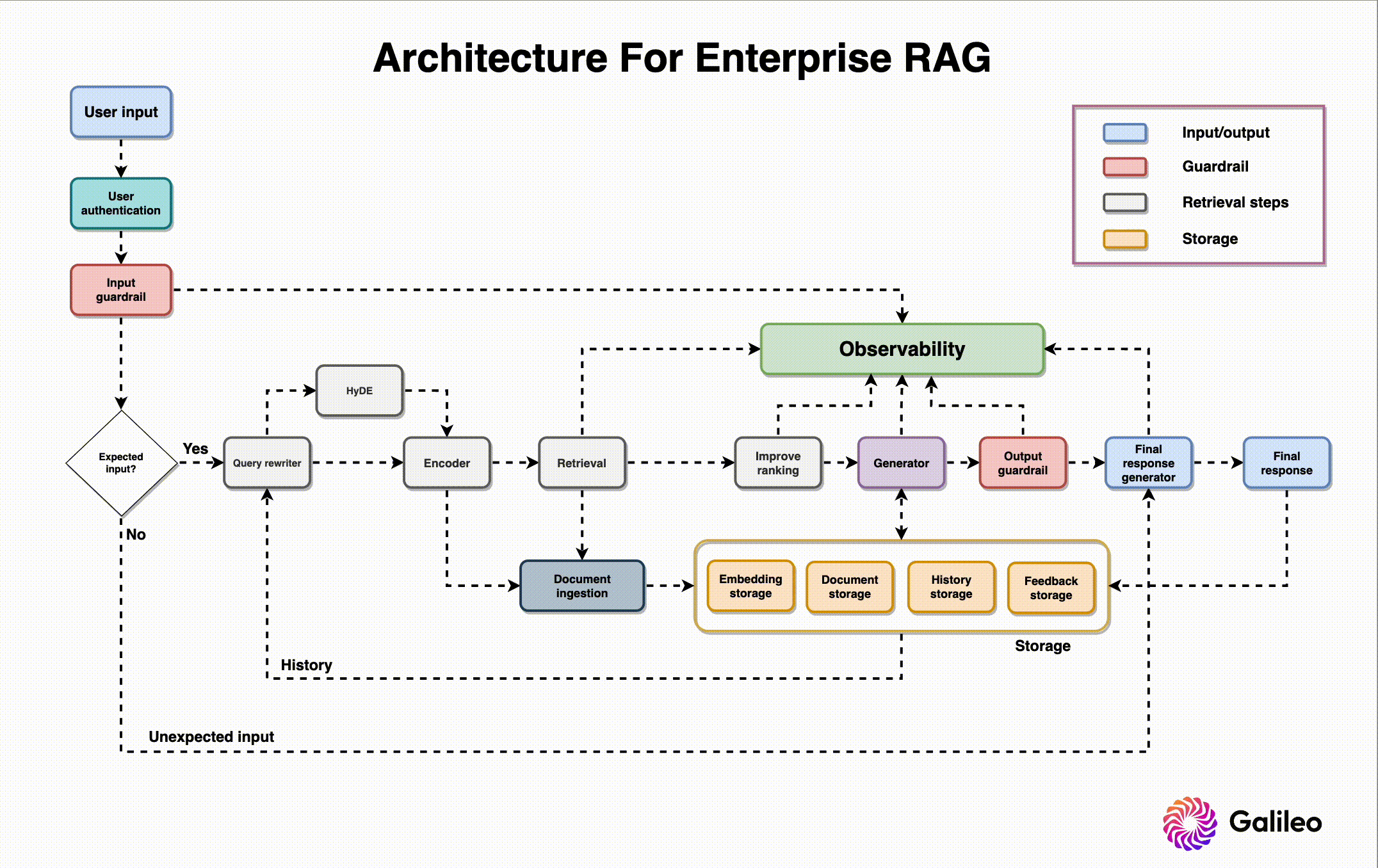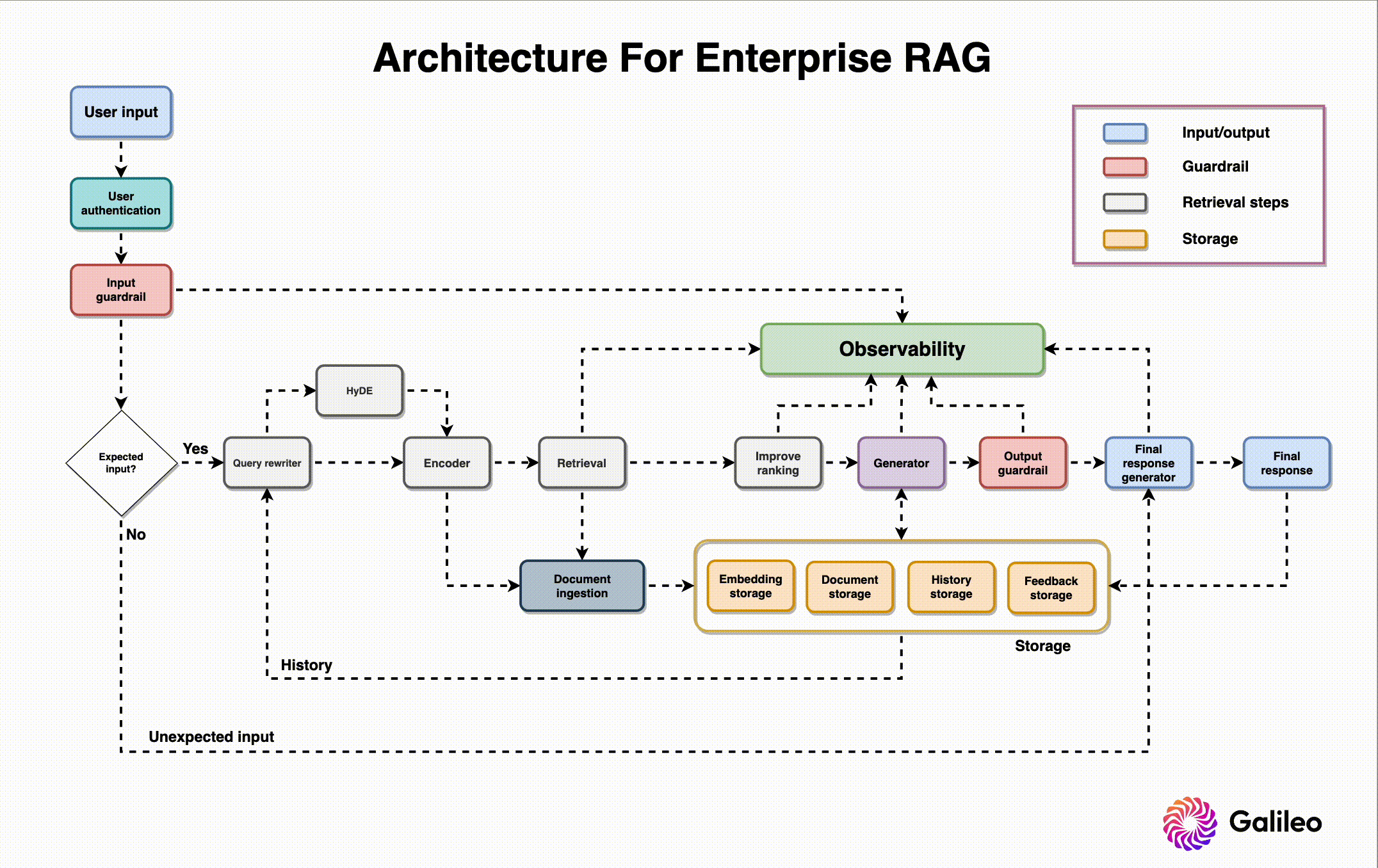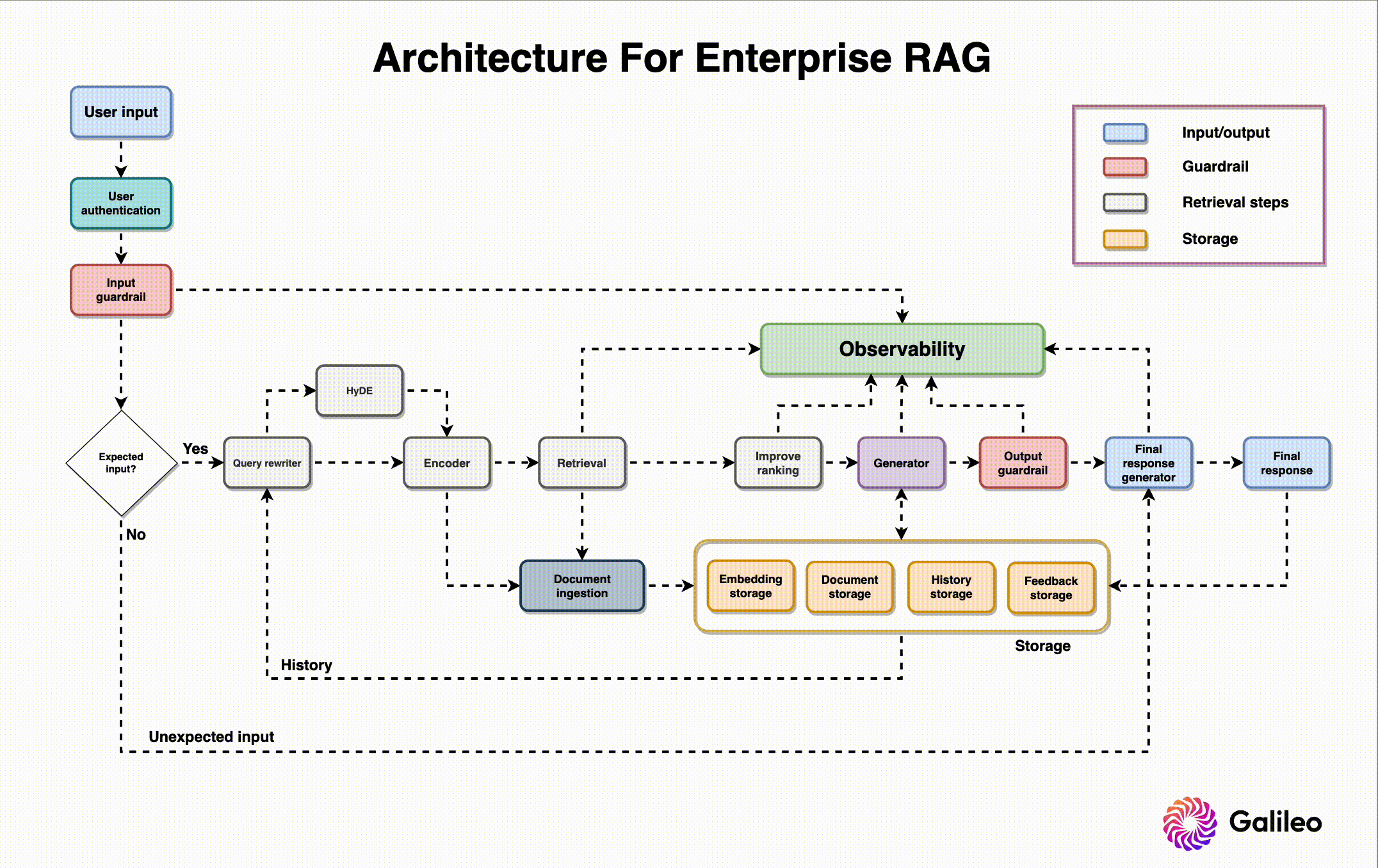
But you can build a basic RAG system with only a vector database, LLM, embedding model, and orchestration tool.
Vector database: A Vector DB, like Pinecone or Weaviate, stores vector embeddings of our external source documents.
LLM: Language models such as OpenAI or LLama serve as the foundation for generating responses.
Embedding model: Often derived from the LLM, the embedding model plays a crucial role in creating meaningful text representation.
Orchestration tool: An orchestration tool like Langchain/Llamaindex/DSPy is used to manage the workflow and interactions between components.
Advantages of RAG
Why go with RAG to begin with? To understand RAG better we recently broke down the pros and cons of RAG vs fine-tuning. Here are some of the top benefits of choosing RAG.
Dynamic data environments
RAG excels in dynamic data environments by continuously querying external sources, ensuring the information used for responses remains current without the need for frequent model retraining.
Hallucination resistance
RAG significantly reduces the likelihood of hallucinations, grounding each response in retrieved evidence. This feature enhances the reliability and accuracy of generated responses, especially in contexts where misinformation is detrimental.
Transparency and trust
RAG systems offer transparency by breaking down the response generation into distinct stages. This transparency provides users with insights into data retrieval processes, fostering trust in the generated outputs.
Implementation challenges
Implementing RAG requires much less expertise than fine-tuning. While setting up retrieval mechanisms, integrating external data sources, and ensuring data freshness can be complex, various pre-built RAG frameworks and tools simplify the process significantly.
Challenges in RAG Systems
Despite its advantages, RAG evaluation, experimentation, and observability are notably manual and labor-intensive. The inherent complexity of RAG systems, with numerous moving parts, makes optimization and debugging challenging, especially within intricate operational chains.
Limited chunking evaluation
It’s difficult to assess the impact of chunking on RAG system outputs, hindering efforts to enhance overall performance.
Embedding model evaluation
Opaque downstream effects make evaluating the effectiveness of the embedding model particularly challenging.
LLM evaluation - contextual ambiguity
Balancing the role of context in RAG systems presents a unique tradeoff between the risk of hallucinations or insufficient context for user queries.
LLM evaluation - prompt optimization
Various prompting techniques have been developed to enhance RAG performance, but determining the most effective one for the data remains challenging.
Inconsistent evaluation metrics
The absence of standardized metrics makes it tough to comprehensively assess all components of RAG systems, impeding a holistic understanding of the system’s performance.
RAG Evaluation

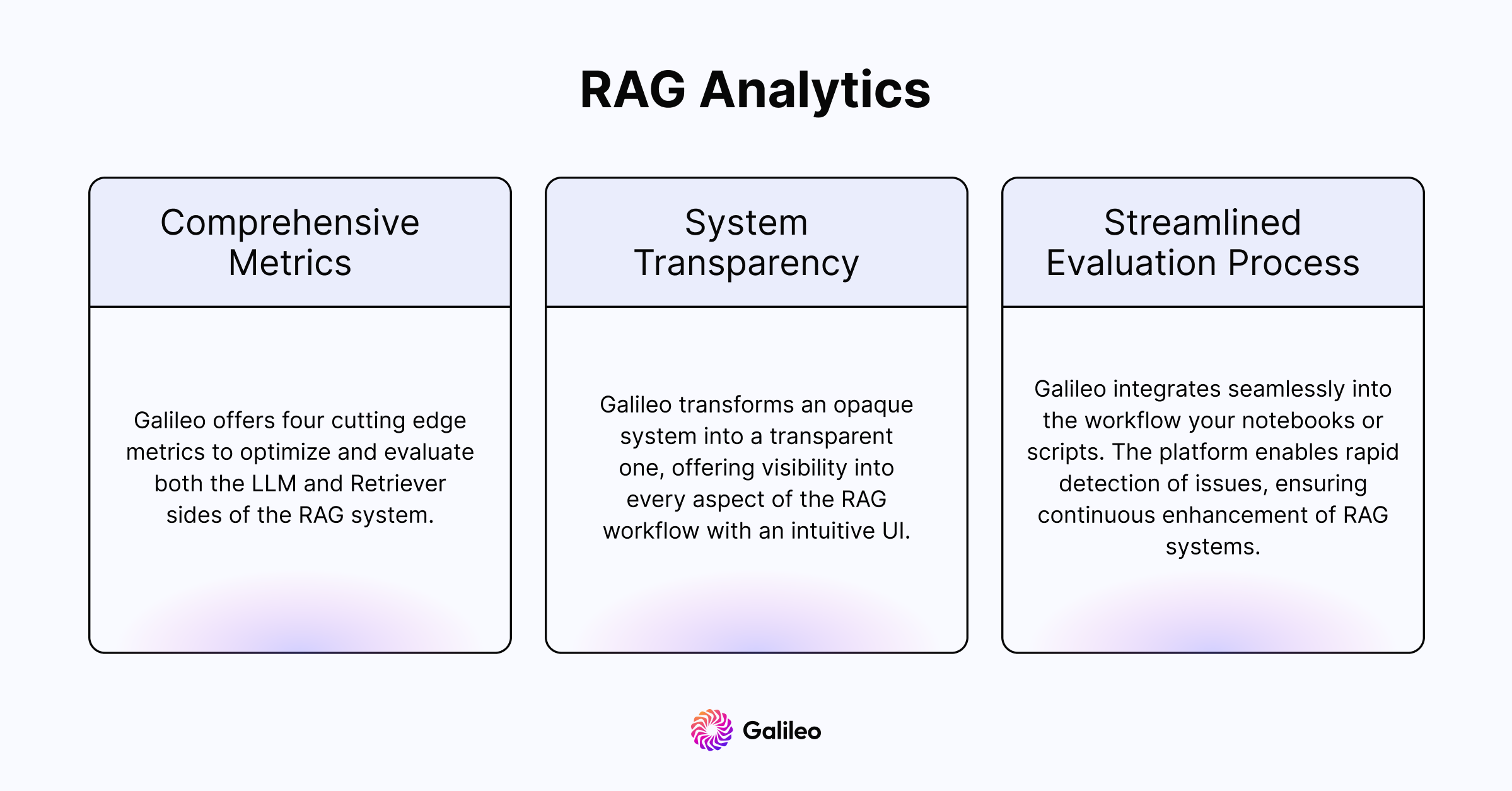
To solve these problems, Galileo’s RAG analytics facilitate faster and smarter development by providing detailed RAG evaluation metrics with unmatched visibility. Our four cutting edge metrics help AI builders optimize and evaluate both the LLM and Retriever sides of their RAG systems.
Chunk Attribution: A chunk-level boolean metric that measures whether a ‘chunk’ was used to compose the response.
Chunk Utilization: A chunk-level float metric that measures how much of the chunk text that was used to compose the response.
Completeness: A response-level metric measuring how much of the context provided was used to generate a response
Context Adherence: A response-level metric that measures whether the output of the LLM adheres to (or is grounded in) the provided context.
Without further ado let's see things in action!
Example: Q&A RAG System


Let's put it all together by building our own RAG system. We’ll use an example of a question-answering system for beauty products. We’ll start by extracting questions from the product descriptions using GPT-3.5-turbo, and subsequently utilize these questions in our RAG system to generate answers. We’ll evaluate the RAG system performance using GenAI Studio and our previously mentioned RAG analytics metrics – Context Adherence, Completeness, Chunk Attribution, and Chunk Utilization.
Here's a breakdown of the steps we’ll take to build our Q&A system:
1. Prepare the Vector Database
2. Generate Questions with GPT
3. Define our QA Chain
4. Choose Galileo Scorers
5. Evaluate RAG Chain
6. RAG Experimentation
Prepare The Vector Database
First we have to prepare our vector database. Let’s install the dependencies required for the RAG evaluation.
1langchain==0.1.4
2langchain-community==0.0.15
3langchain-openai==0.0.5
4promptquality[arrow]==0.28.1
5openai==1.10.0
6pinecone-client==3.0.1
7datasets==2.16.1
8spacy==3.7.2
9sentence-transformersDataset
We obtained a subset of data from Kaggle, specifically sourced from the BigBasket (e-commerce) website. This dataset encompasses details about various consumer goods, and we narrowed it down by selecting only 500 products for analysis.
1import pandas as pd
2
3# BigBasket dataset
4# https://www.kaggle.com/datasets/surajjha101/bigbasket-entire-product-list-28k-datapoints
5df = pd.read_csv("../data/bigbasket.csv")
6df = df[df['brand'].isin(["BIOTIQUE", "Himalaya", "Loreal Paris", "Nivea", "Nivea Men", "Kaya Clinic", "Mamaearth", "Lakme", "Schwarzkopf", "Garnier", "Fiama"])]
7df = df.drop_duplicates(subset=["product"])
8rows = 500
9df.iloc[:rows].to_csv("../data/bigbasket_beauty.csv", index=False)Chunking
For chunking we leverage the RecursiveCharacterTextSplitter with a default settings chunk_size of 4,000 and chunk_overlap of 200. Because our descriptions are less than 4,000 characters, chunking does not happen leading to 50 chunks; we’re using these settings to illustrate problems that can occur with default settings.
We define some common utils for the experiments.
1from langchain_community.embeddings import HuggingFaceEmbeddings
2from langchain_core.documents import Document
3from langchain_openai import OpenAIEmbeddings
4from langchain.text_splitter import RecursiveCharacterTextSplitter
5import spacy
6
7class SpacySentenceTokenizer():
8 def __init__(self, spacy_model="en_core_web_sm"):
9 self.nlp = spacy.load(spacy_model)
10 self._chunk_size = None
11 self._chunk_overlap = None
12
13 def create_documents(self, documents, metadatas=None):
14 chunks = []
15 for doc, metadata in zip(documents, metadatas):
16 for sent in self.nlp(doc).sents:
17 chunks.append(Document(page_content=sent.text, metadata=metadata))
18 return chunks
19
20def get_indexing_configuration(config):
21 if config == 1:
22 text_splitter = SpacySentenceTokenizer()
23 text_splitter_identifier = "sst"
24 emb_model_name, dimension, emb_model_identifier = "text-embedding-3-small", 1536, "openai-small"
25 embeddings = OpenAIEmbeddings(model=emb_model_name, tiktoken_model_name="cl100k_base")
26 index_name = f"beauty-{text_splitter_identifier}-{emb_model_identifier}"
27
28 elif config == 2:
29 text_splitter = SpacySentenceTokenizer()
30 text_splitter_identifier = "sst"
31 emb_model_name, dimension, emb_model_identifier = "text-embedding-3-large", 1536*2, "openai-large"
32 embeddings = OpenAIEmbeddings(model=emb_model_name, tiktoken_model_name="cl100k_base")
33 index_name = f"beauty-{text_splitter_identifier}-{emb_model_identifier}"
34
35 elif config == 3:
36 text_splitter = SpacySentenceTokenizer()
37 text_splitter_identifier = "sst"
38 emb_model_name, dimension, emb_model_identifier = "all-MiniLM-L6-v2", 384, "all-minilm-l6"
39 embeddings = HuggingFaceEmbeddings(model_name=emb_model_name, encode_kwargs = {'normalize_embeddings': True, 'show_progress_bar': False})
40 index_name = f"beauty-{text_splitter_identifier}-{emb_model_identifier}"
41
42 elif config == 4:
43 text_splitter = SpacySentenceTokenizer()
44 text_splitter_identifier = "sst"
45 emb_model_name, dimension, emb_model_identifier = "all-mpnet-base-v2", 768, "all-mpnet"
46 embeddings = HuggingFaceEmbeddings(model_name=emb_model_name, encode_kwargs = {'normalize_embeddings': True, 'show_progress_bar': False})
47 index_name = f"beauty-{text_splitter_identifier}-{emb_model_identifier}"
48
49 elif config == 5:
50 text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=50)
51 text_splitter_identifier = "rc"
52 emb_model_name, dimension, emb_model_identifier = "text-embedding-3-small", 1536, "openai-small"
53 embeddings = OpenAIEmbeddings(model=emb_model_name, tiktoken_model_name="cl100k_base")
54 index_name = f"beauty-{text_splitter_identifier}-cs{text_splitter._chunk_size}-co{text_splitter._chunk_overlap}-{emb_model_identifier}"
55
56 return text_splitter, embeddings, emb_model_name, dimension, index_nameLet's chunk the data using config 1. We ensure that queries containing the product name align with the description chunks by appending the product name at the beginning of each chunk.
1import sys, os, time
2
3from pinecone import Pinecone, ServerlessSpec
4from dotenv import load_dotenv
5from datasets import load_dataset
6import pandas as pd
7
8from langchain_community.vectorstores import Pinecone as langchain_pinecone
9from common import SpacySentenceTokenizer, get_indexing_configuration
10
11load_dotenv("../.env")
12
13df = pd.read_csv("../data/bigbasket_beauty.csv")
14
15indexing_config = 1
16text_splitter, embeddings, emb_model_name, dimension, index_name = get_indexing_configuration(indexing_config)
17
18chunks = text_splitter.create_documents(df.description.values, metadatas=[{"product_name": i} for i in df["product"].values] )
19def add_product_name_to_page_content(chunk):
20 chunk.page_content = f"Product name: {chunk.metadata['product_name']}\n{chunk.page_content}"
21 chunk.metadata = {}
22
23for chunk in chunks:
24 add_product_name_to_page_content(chunk)
25
26print(chunks[0].page_content)We leverage Pinecone’s Serverless vector database, employing the cosine similarity metric. Utilizing the Pinecone Python client, we actively add documents to the index.
1# instantiate a Pinecone client
2pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY"))
3
4# First, check if our index already exists and delete stale index
5if index_name in [index_info['name'] for index_info in pc.list_indexes()]:
6 pc.delete_index(index_name)
7
8# we create a new index
9pc.create_index(name=index_name, metric="cosine", dimension=dimension, # The OpenAI embedding model uses 1536 dimensions`
10 spec=ServerlessSpec(
11 cloud="aws",
12 region="us-west-2"
13 ) )
14time.sleep(10)
15
16# index the docs in the database
17docsearch = langchain_pinecone.from_documents(chunks, embeddings, index_name=index_name)This completes our vector DB setup!
Generate Questions With GPT
We require questions to conduct the evaluation, but our dataset consists of only product descriptions. To obtain test questions for the chatbot, either we can manually create test questions for our chatbot or leverage an LLM to generate them. To make our lives easier, we harness the power of GPT-3.5-turbo by employing a specific prompt.
Let's load the dataset again.
1import sys, os
2
3from tqdm import tqdm
4tqdm.pandas()
5
6from dotenv import load_dotenv
7from langchain_openai import ChatOpenAI
8from langchain_core.messages import HumanMessage
9import pandas as pd
10
11load_dotenv("../.env")
12
13
14df = pd.read_csv("big_basket_beauty.csv")
15chat = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=1.0)We employ a few-shot approach to create synthetic questions, directing the model to generate five distinct and perplexing questions by utilizing the product description. The model is instructed to incorporate the exact product name from the description into each question.
1def get_questions(product_name, product_description):
2 questions = chat.invoke(
3 [
4 HumanMessage(
5 content=f"""Your job is to generate questions for the product descriptions such that it is hard to answer the question.
6
7
8Example 1
9Product name: Fructis Serum - Long & Strong
10Product description: Garnier Fruits Long & Strong Strengthening Serum detangles unruly hair, softens hair without heaviness and helps stop split and breakage ends. It is enriched with the goodness of Grape seed and avocado oil that result in smoother, shinier and longer hair.
11Questions:
12- Does Garnier Fruits Long & Strong Strengthening Serum help in hair growth?
13- Which products contain avocado oil?
14
15Example 2
16Product name: Color Naturals Creme Riche Ultra Hair Color - Raspberry Red
17Product description: Garnier Color Naturals is creme hair colour which gives 100% Grey Coverage and ultra visible colour with 50% more shine. It has a superior Colour Lock technology which gives you a rich long-lasting colour that lasts up to 8 weeks. Color Naturals comes in a range of 8 gorgeous shades especially suited for Indian skin tones. It is available in an easy to use kit which can be used at your convenience in the comfort of your house! It is enriched with the goodness of 3 oils - Almond, Olive and Avocado which nourishes hair and provides shiny, long-lasting colour. Your hair will love the nourishment and you will love the colour!
18Questions:
19- How long does Color Naturals Creme Riche Ultra Hair Color last?
20- Which product for hair color is suited for indian skin?
21- How many colors are available in Color Naturals Hair Color?
22
23Product name: Black Naturals Hair Colour Shade 1-Deep Black 20 ml + 20 gm
24Product description: It is an oil-enriched cream colour which gives natural-looking black hair. Works in 15 minutes, non-drip cream. Maintains softness, smoothness, and shine. No ammonia hair colour. Lasts for 6 weeks.
25Questions:
26- Does Black Naturals Hair Colour contain ammonia?
27- How muct time do you have to keep Grey Naturals Hair Colour on your hair?
28
29Now generate 5 confusing questions which can be answered for this product based on description. Use the exact product name in the questions as mentioned in the description. There should not be duplicates in the 5 questions. Return questions starting with - instead of numbers.
30
31Product name: {product_name}
32Product description: {product_description}
33Questions: """
34 )
35 ]
36)
37 questions = questions.content.replace("- ", "").split("\n")
38 questions = list(filter(None, questions))
39 return questions
40
41sample["questions"] = sample.progress_apply(lambda x: get_questions(x["product"], x["description"]), axis=1)
42
43sample.to_csv("questions.csv", index=False)Define Our QA Chain
We build a standard QA using the RAG chain, utilizing GPT-3.5-turbo as the LLM and the same vector DB for retrieval.
1import os
2
3from langchain_openai import ChatOpenAI
4from langchain.prompts import ChatPromptTemplate
5from langchain.schema.runnable import RunnablePassthrough
6from langchain.schema import StrOutputParser
7from langchain_community.vectorstores import Pinecone as langchain_pinecone
8from pinecone import Pinecone
9
10def get_qa_chain(embeddings, index_name, k, llm_model_name, temperature):
11 # setup retriever
12 pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY"))
13 index = pc.Index(index_name)
14 vectorstore = langchain_pinecone(index, embeddings.embed_query, "text")
15 retriever = vectorstore.as_retriever(search_kwargs={"k": k}) # https://github.com/langchain-ai/langchain/blob/master/libs/core/langchain_core/vectorstores.py#L553
16
17 # setup prompt
18 rag_prompt = ChatPromptTemplate.from_messages(
19 [
20 (
21 "system",
22 "Answer the question based only on the provided context."
23 ),
24 ("human", "Context: '{context}' \n\n Question: '{question}'"),
25 ]
26 )
27
28 # setup llm
29 llm = ChatOpenAI(model_name=llm_model_name, temperature=temperature)
30
31 # helper function to format docs
32 def format_docs(docs):
33 return "\n\n".join([d.page_content for d in docs])
34
35 # setup chain
36 rag_chain = (
37 {"context": retriever | format_docs, "question": RunnablePassthrough()}
38 | rag_prompt
39 | llm
40 | StrOutputParser()
41 )
42
43 return rag_chainChoose Galileo Scorers
In the promptquality library, Galileo employs numerous scorers. We’re going to choose evaluation metrics that help measure system performance, including latency and safety metrics like PII, toxicity, and tone, as well as the four RAG metrics.
1import promptquality as pq
2from promptquality import Scorers
3
4all_metrics = [
5 Scorers.latency,
6 Scorers.pii,
7 Scorers.toxicity,
8 Scorers.tone,
9 #rag metrics below
10 Scorers.context_adherence,
11 Scorers.completeness_gpt,
12 Scorers.chunk_attribution_utilization_gpt,
13]Custom scorer
In certain situations, the user may need a custom metric that better aligns with business requirements. In these instances, adding a custom scorer to the existing scorers is a straightforward solution.
1from typing import Optional
2
3#Custom scorer for response length
4def executor(row) -> Optional[float]:
5 if row.response:
6 return len(row.response)
7 else:
8 return 0
9
10def aggregator(scores, indices) -> dict:
11 return {'Response Length': sum(scores)/len(scores)}
12
13length_scorer = pq.CustomScorer(name='Response Length', executor=executor, aggregator=aggregator)
14all_metrics.append(length_scorer)Now that we have everything ready let’s move on to evaluation.
Evaluate RAG Chain
To begin, load the modules and log in to the Galileo console through the console URL. A popup will appear, prompting you to copy the secret key and paste it into your IDE or terminal.
[ Contact us to get started with your Galileo setup ]
1import random
2from dotenv import load_dotenv
3
4import pandas as pd
5import promptquality as pq
6from tqdm import tqdm
7
8from common import get_indexing_configuration
9from metrics import all_metrics
10from qa_chain import get_qa_chain
11
12load_dotenv("../.env")
13
14# fixed values for the experiment
15project_name = "feb10-qa"
16temperature = 0.1
17
18# experiment config
19indexing_config = 1
20llm_model_name, llm_identifier, k = "gpt-3.5-turbo-1106", "3.5-1106", 20
21
22_, embeddings, emb_model_name, dimension, index_name = get_indexing_configuration(indexing_config)
23
24console_url = "console.exp.rungalileo.io"
25pq.login(console_url)Randomly select 100 questions for the evaluation by loading all questions.
1# Prepare questions for the conversation
2df = pd.read_csv("../data/bigbasket_beauty.csv")
3df["questions"] = df["questions"].apply(eval)
4questions = df.explode("questions")["questions"].tolist()
5random.Random(0).shuffle(questions)
6
7questions = questions[:100] # selecting only first 100 turnsLoad the chain and set up the handler with tags as you experiment with prompts, tuning various parameters. You might conduct experiments using different models, model versions, vector stores, and embedding models. Utilize Run Tags to effortlessly log any run details you wish to review later in the Galileo Evaluation UI.
1run_name = f"{index_name}-{llm_identifier}-k{k}"
2
3index_name_tag = pq.RunTag(key="Index config", value=index_name, tag_type=pq.TagType.RAG)
4encoder_model_name_tag = pq.RunTag(key="Encoder", value=emb_model_name, tag_type=pq.TagType.RAG)
5llm_model_name_tag = pq.RunTag(key="LLM", value=llm_model_name, tag_type=pq.TagType.RAG)
6dimension_tag = pq.RunTag(key="Dimension", value=str(dimension), tag_type=pq.TagType.RAG)
7topk_tag = pq.RunTag(key="Top k", value=str(k), tag_type=pq.TagType.RAG)
8
9evaluate_handler = pq.GalileoPromptCallback(project_name=project_name, run_name=run_name, scorers=all_metrics, run_tags=[encoder_model_name_tag, llm_model_name_tag, index_name_tag, dimension_tag, topk_tag])Let's evaluate each question by generating answers and, ultimately, push the Langchain data to the Galileo console to initiate metric calculations.
All we need to do is pass our evaluate handler callback to invoke.
1print("Ready to ask!")
2for i, q in enumerate(tqdm(questions)):
3 print(f"Question {i}: ", q)
4 print(qa.invoke(q, config=dict(callbacks=[evaluate_handler])))
5 print("\n\n")
6
7evaluate_handler.finish()This brings us to the most exciting part of the build… 🥁🥁🥁
RAG Experimentation
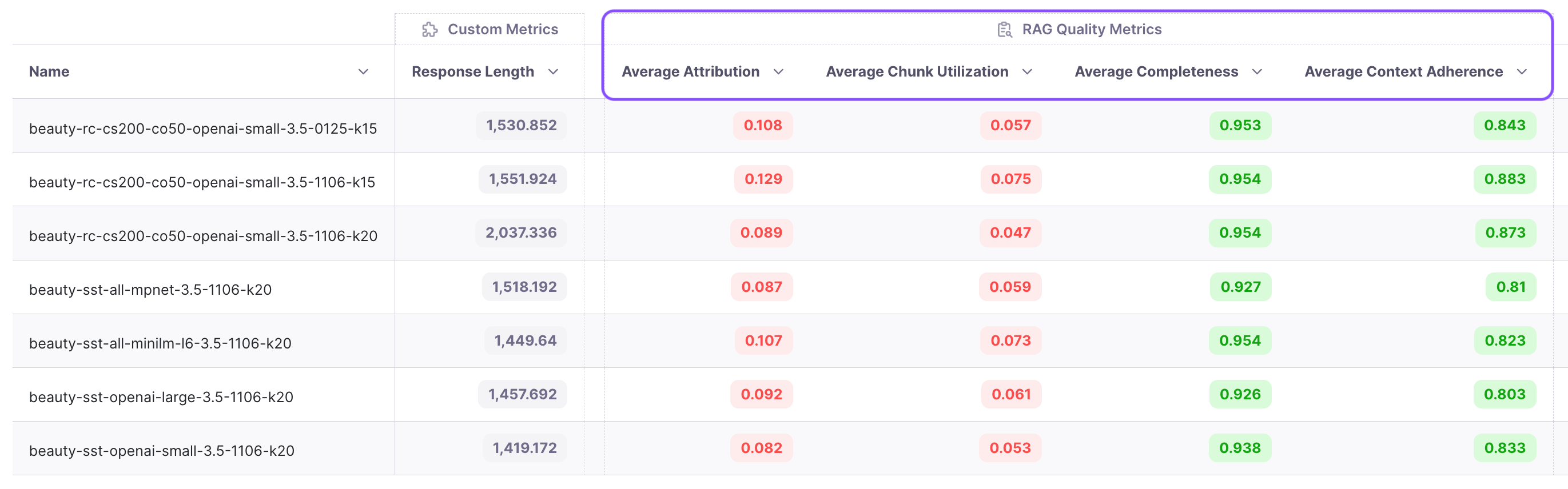
Now that we have built the system with many parameters let’s run some experiments to improve it. The project view below shows the four RAG metrics of all runs.

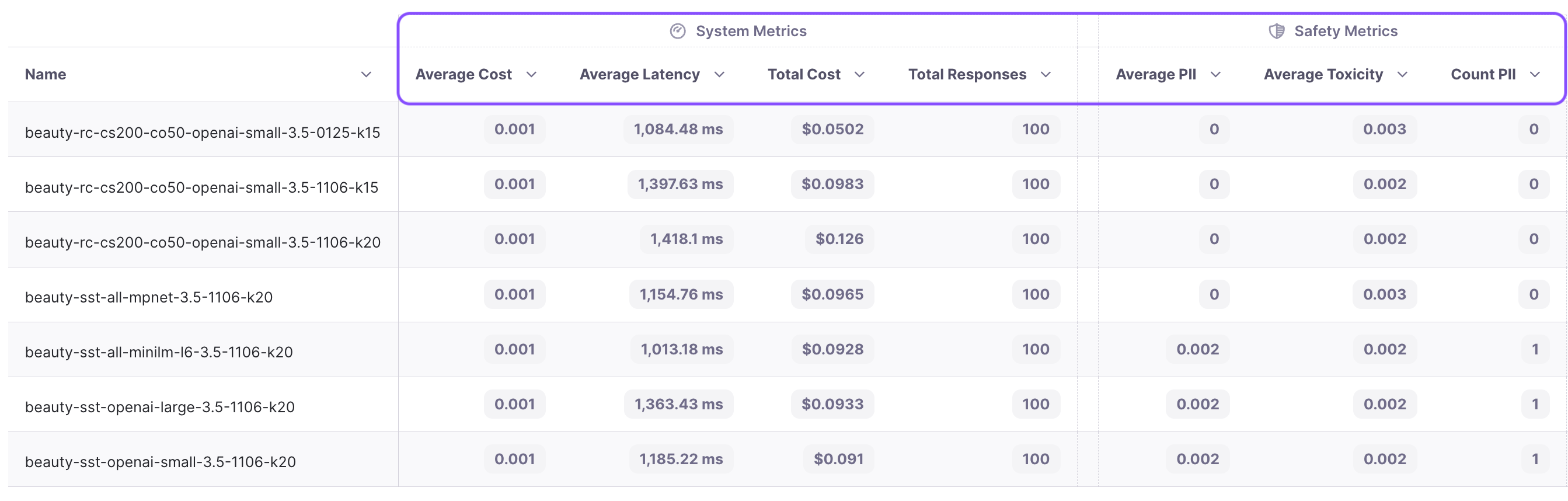
We can also analyze system metrics for each run, helping us improve cost and latency. Additionally, safety-related metrics like PII and toxicity help monitor possibly damaging outputs.

Finally, we can examine the tags to understand the particular configuration utilized for each experiment.

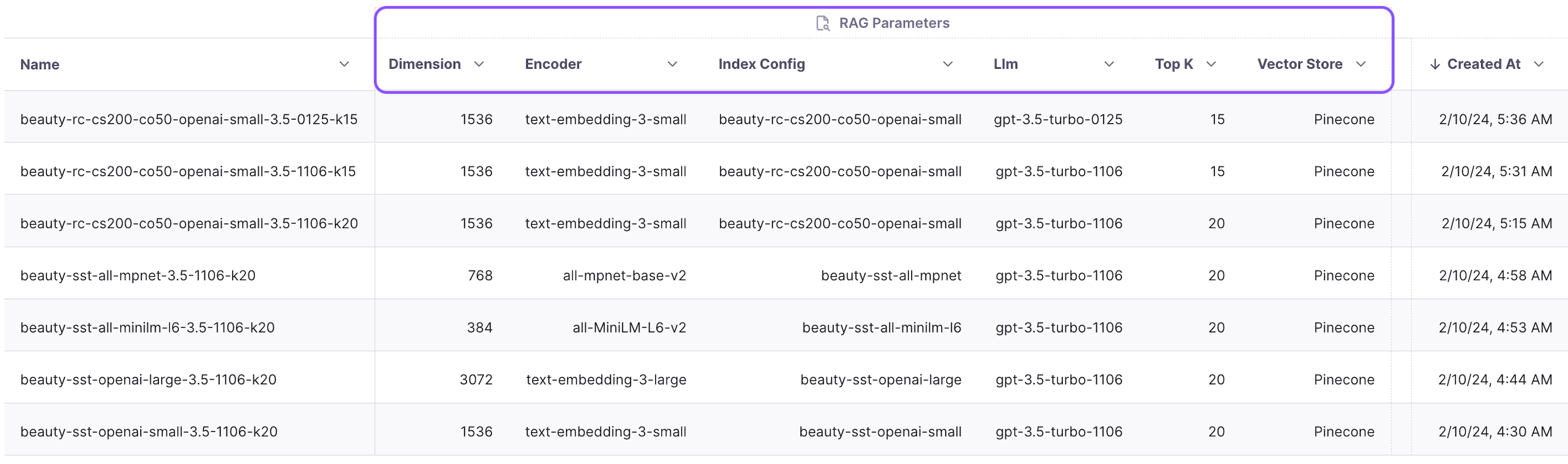
Now let’s look at the experiments we conducted to improve the performance of our RAG system.
Select the embedding model
Initially, we will conduct experiments to determine the optimal encoder. Keeping the sentence tokenizer, LLM (GPT-3.5-turbo), and k (20) constant, we assess four different encoders:
1. all-mpnet-base-v2 (dim 768)
2. all-MiniLM-L6-v2 (dim 384)
3. text-embedding-3-small (dim 1536)
4. text-embedding-3-large (dim 1536*2)
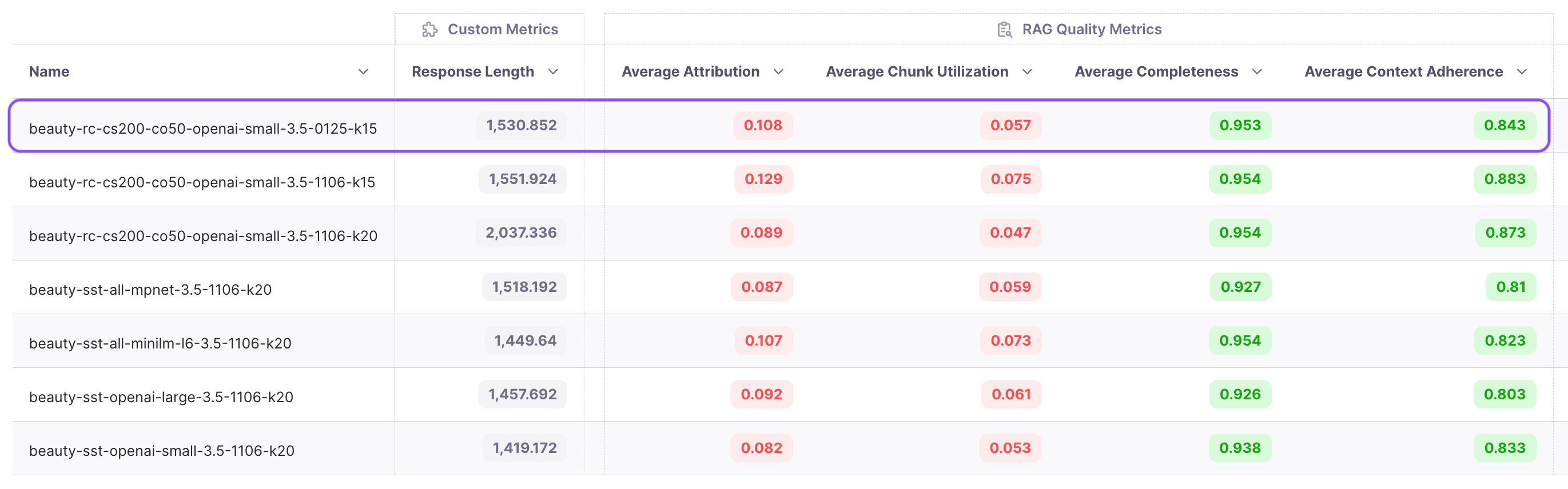
Our guiding metric is context adherence, which measures hallucinations. The metrics for these four experiments are presented in the last four rows of the table above. Among them, text-embedding-3-small achieves the highest context adherence score, making it the winner for further optimization.
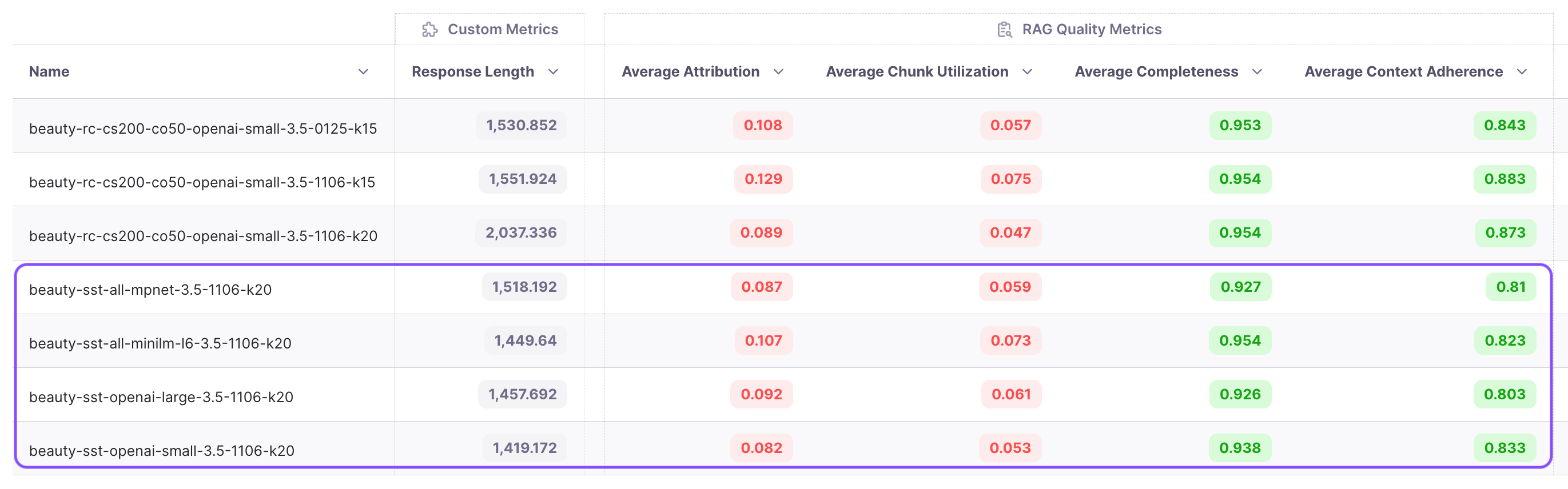
Within the run, it becomes evident that certain workflows (examples) exhibit low adherence scores.

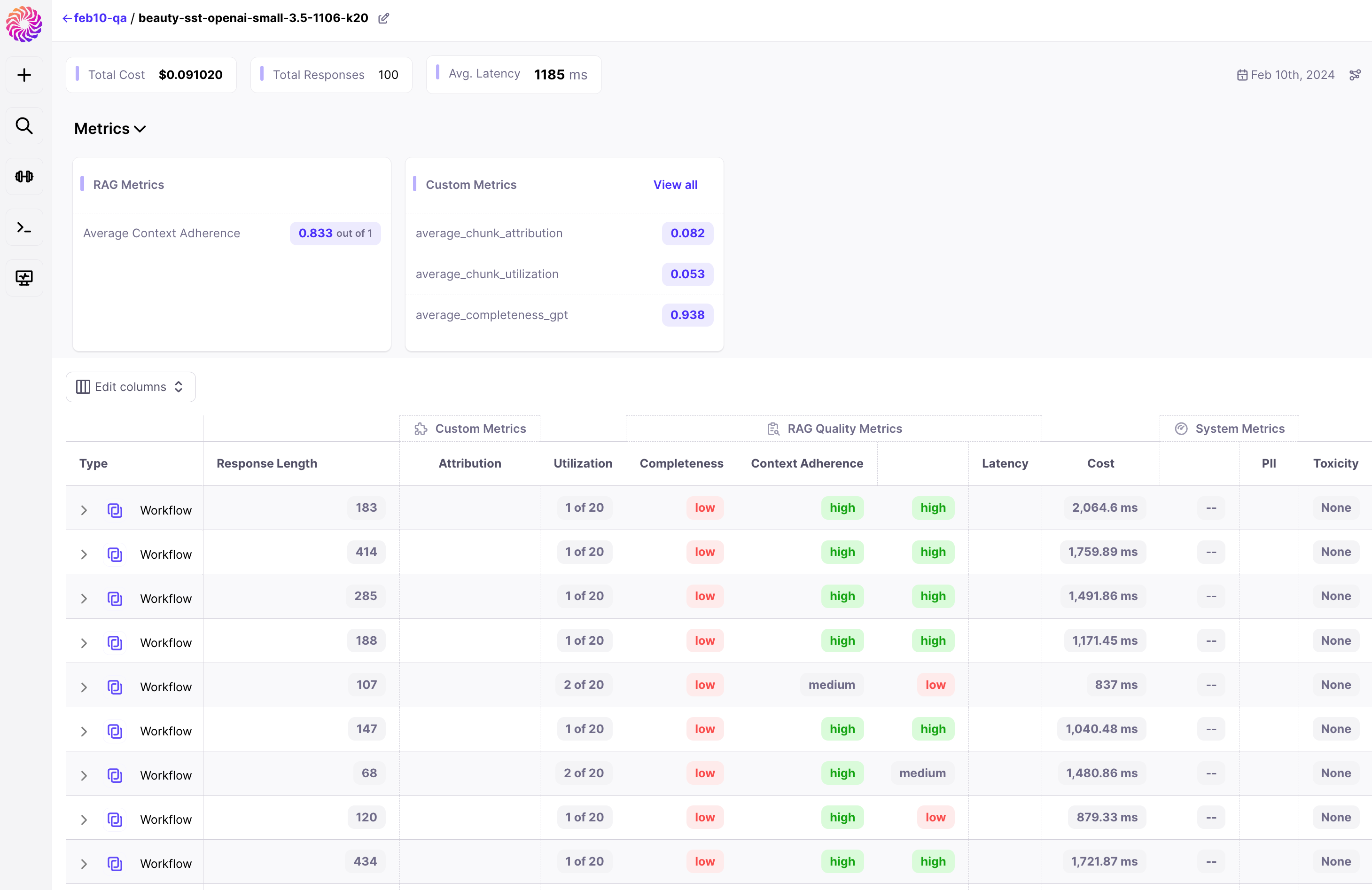
In order to troubleshoot the issue we can go inside the workflow. The below image shows the workflow info with the i/o of the chain. On the left we can see the hierarchy of chains, on the right we get the workflow metrics, and in the center the i/o for chains.

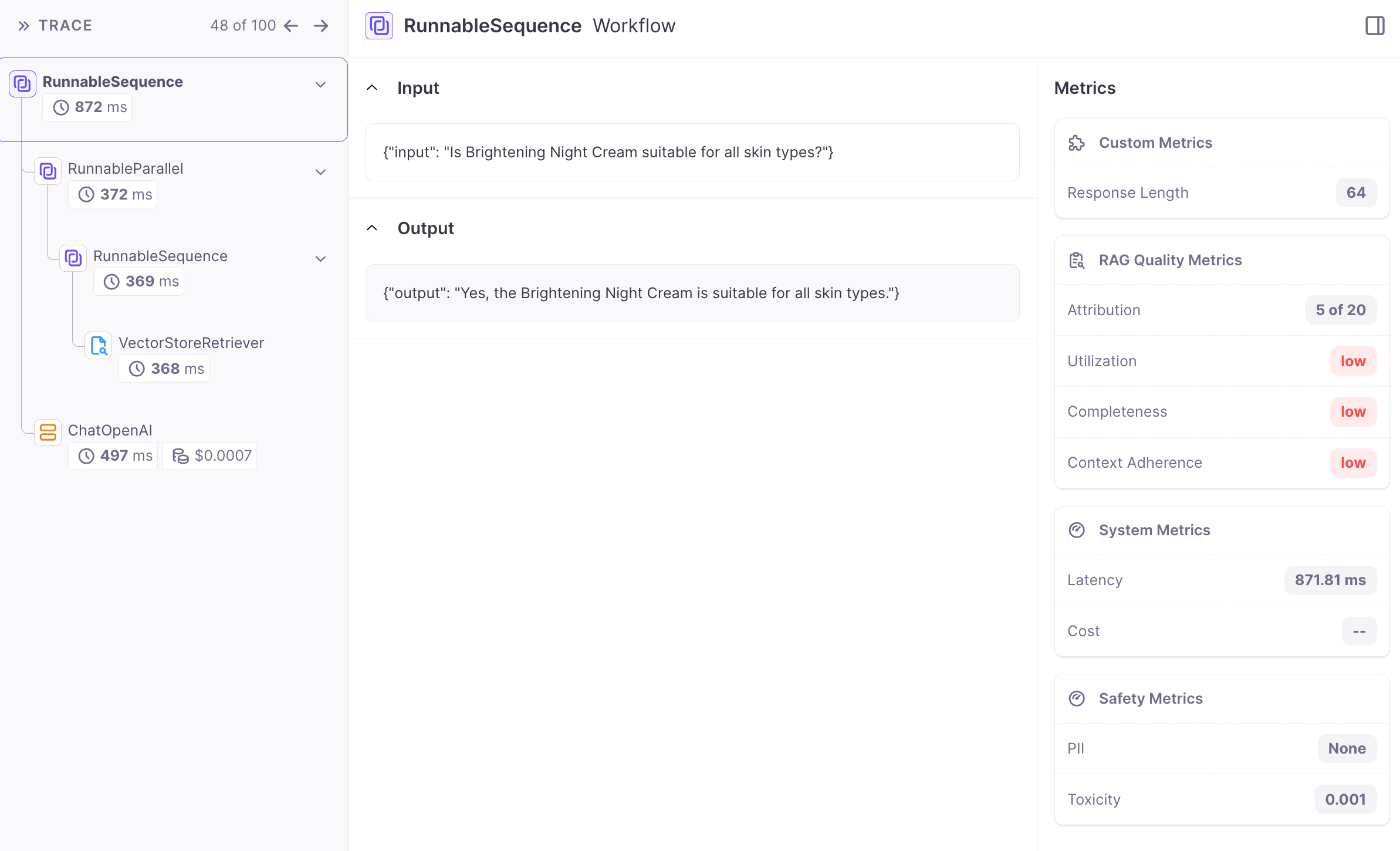
The generation's poor quality is frequently linked to inadequate retrieval. To know how to move forward, let’s analyze the quality of chunks obtained from retrieval. The attribute-to-output (see screenshot below) informs us whether the chunk was utilized in the generation process.

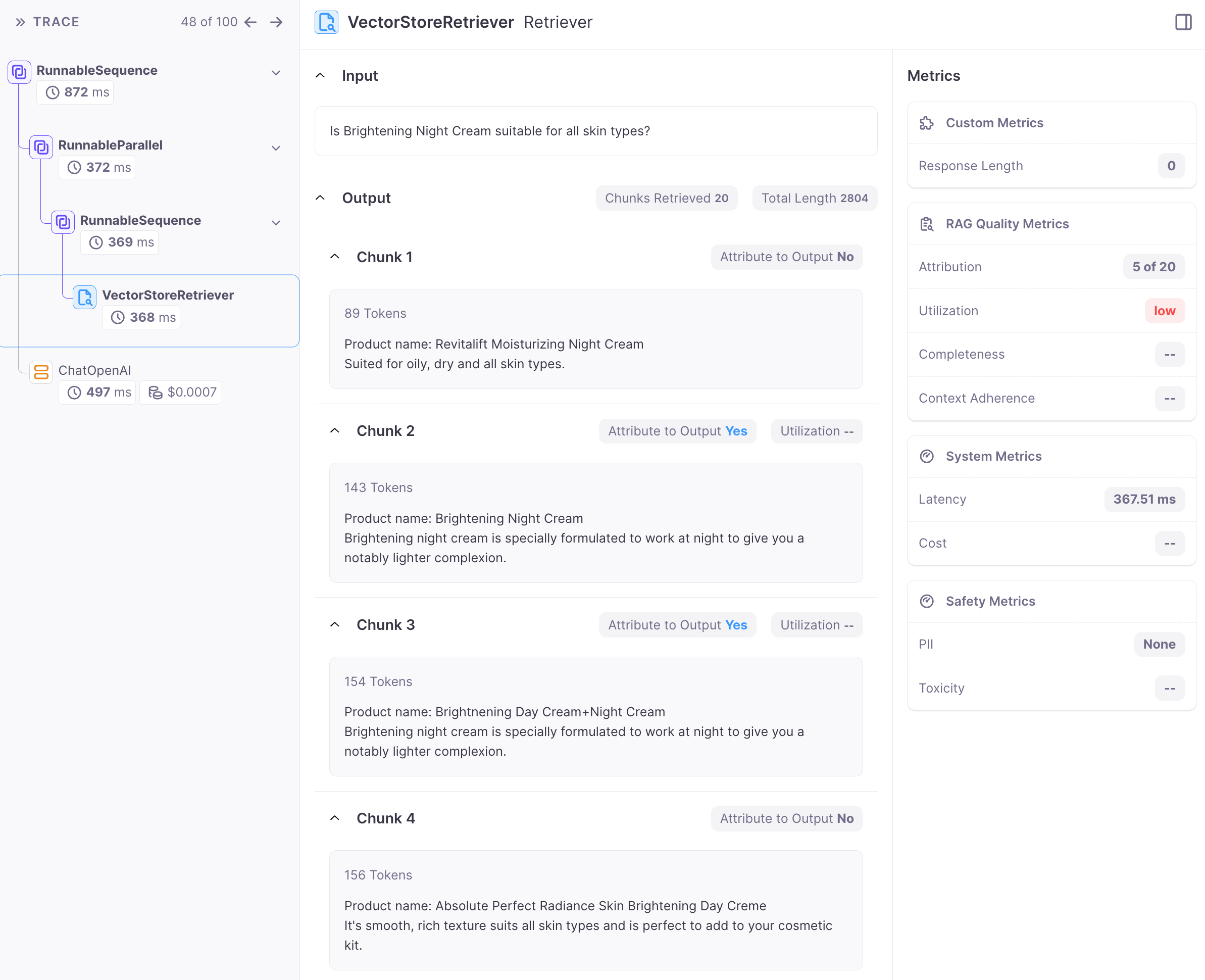
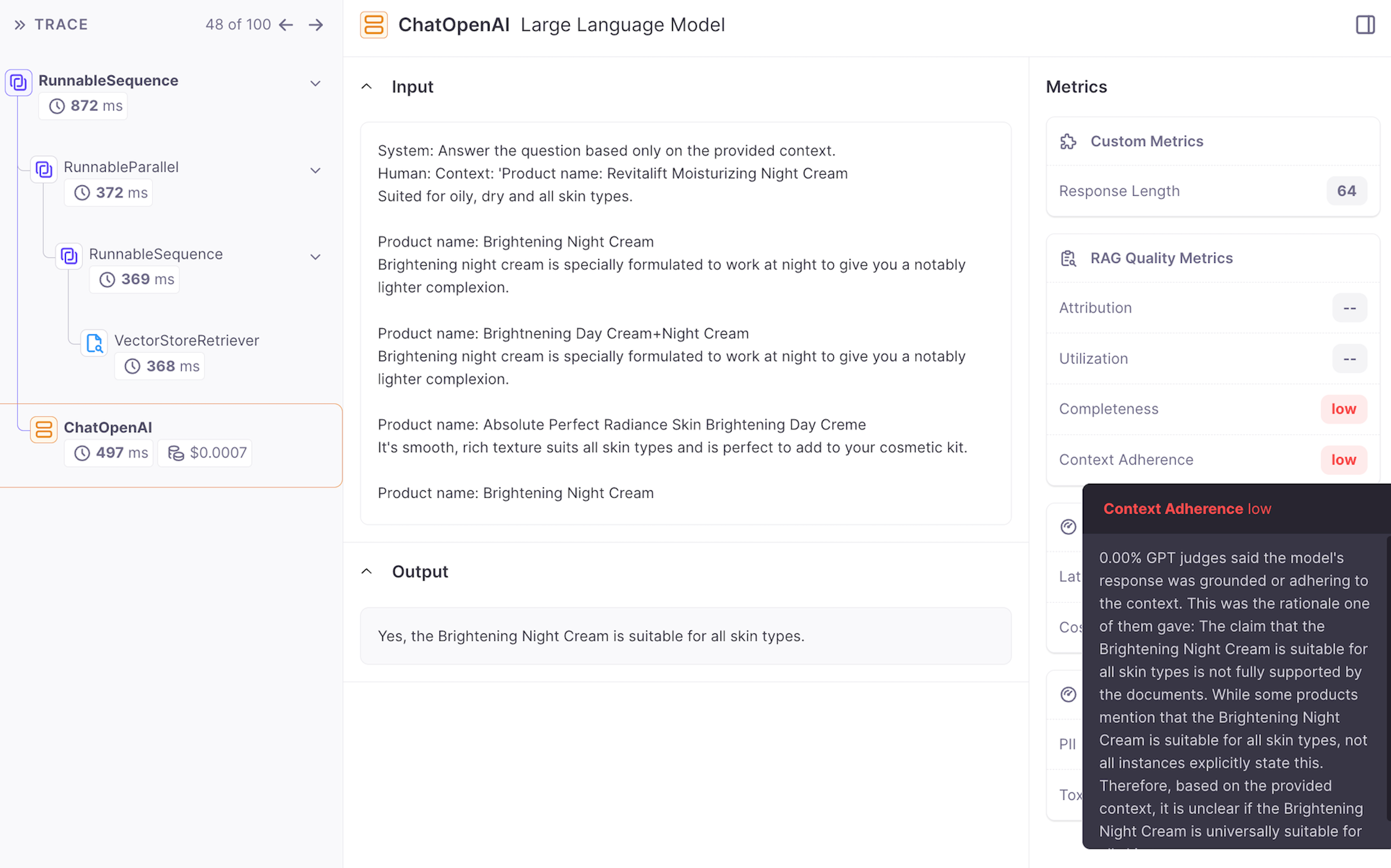
In our example, the question is "Is Brightening Night Cream suitable for all skin types?" Examining the chunks, none explicitly states that "Brightening Night Cream" is suitable for all skin types. This presents a classic case of hallucination resulting in low context adherence. The following provides a detailed explanation of why this generation received a low context adherence score.
“0.00% GPT judges said the model's response was grounded or adhering to the context. This was the rationale one of them gave: The claim that the Brightening Night Cream is suitable for all skin types is not fully supported by the documents. While some products mention that the Brightening Night Cream is suitable for all skin types, not all instances explicitly state this. Therefore, based on the provided context, it is unclear if the Brightening Night Cream is universally suitable for all skin types.”

Select the right chunker
Next we keep the same embedding model (text-embedding-3-small), LLM(gpt-3.5-turbo), k(20) and try recursive chunking with chunk size of 200 and chunk overlap of 50. This alone leads to a 4% improvement in adherence. Isn’t that amazing!
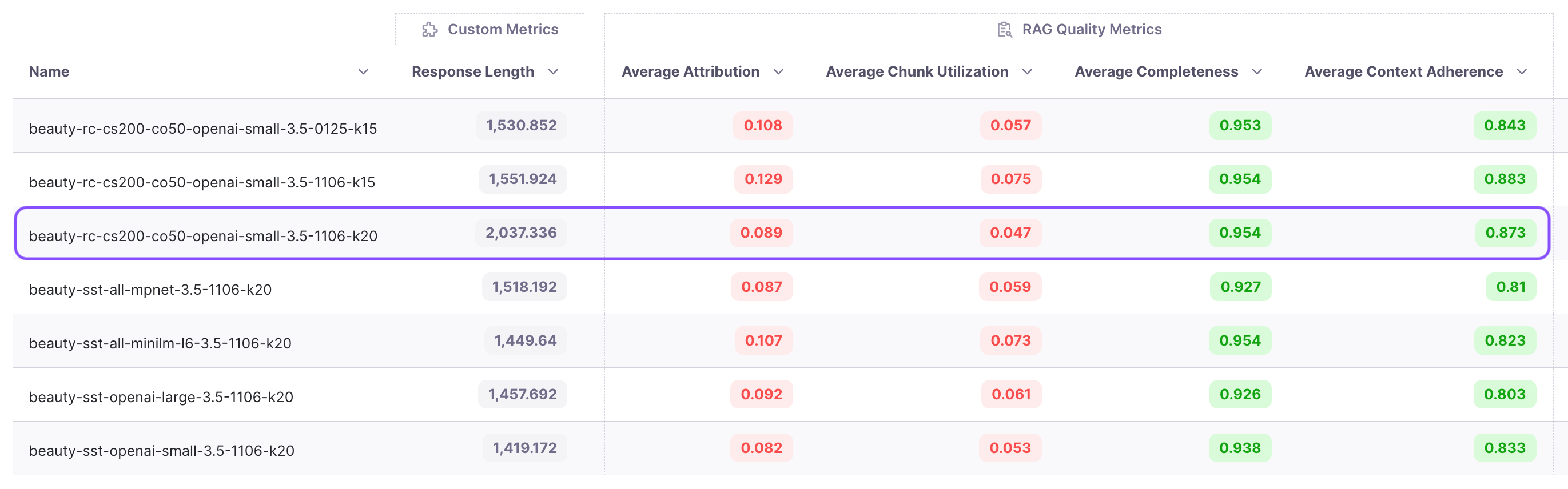
Improving top k
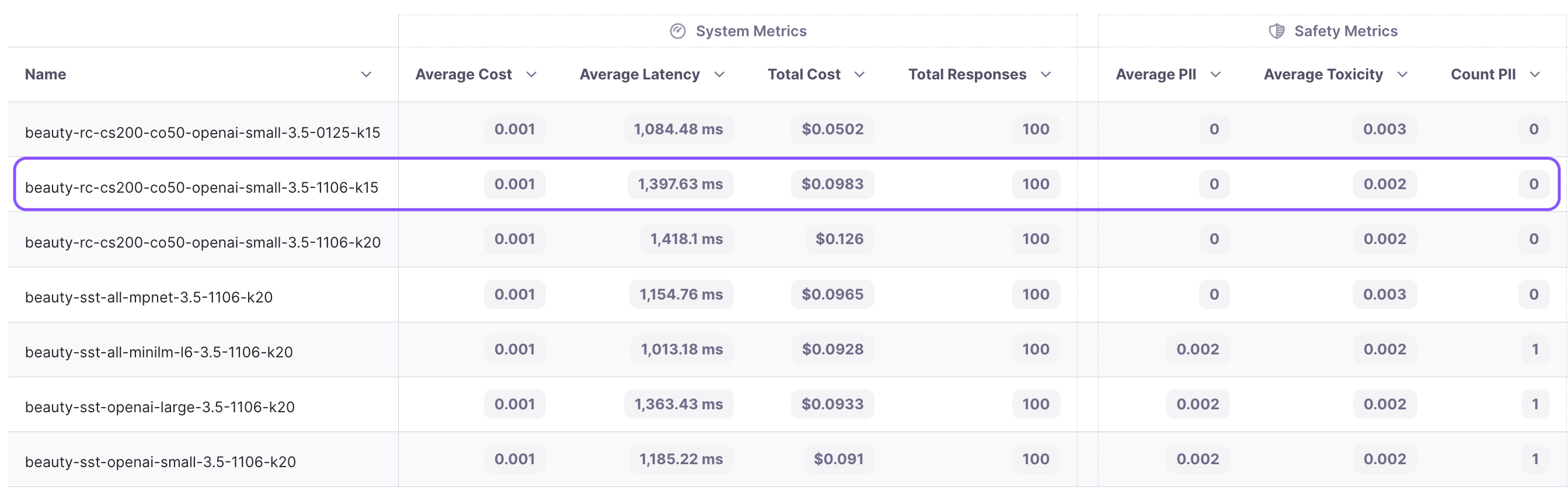
From the experiments, we observe that chunk attribution remains in the single digits, hovering around 8%. This indicates that less than 10% of the chunks are useful. Recognizing this opportunity, we decide to conduct an experiment with a reduced top k value. We choose to run the experiment with a k value of 15 instead of 20. The results show an increase in attribution from 8.9% to 12.9%, and adherence improves from 87.3% to 88.3%. We’ve now reduced costs while improving performance!
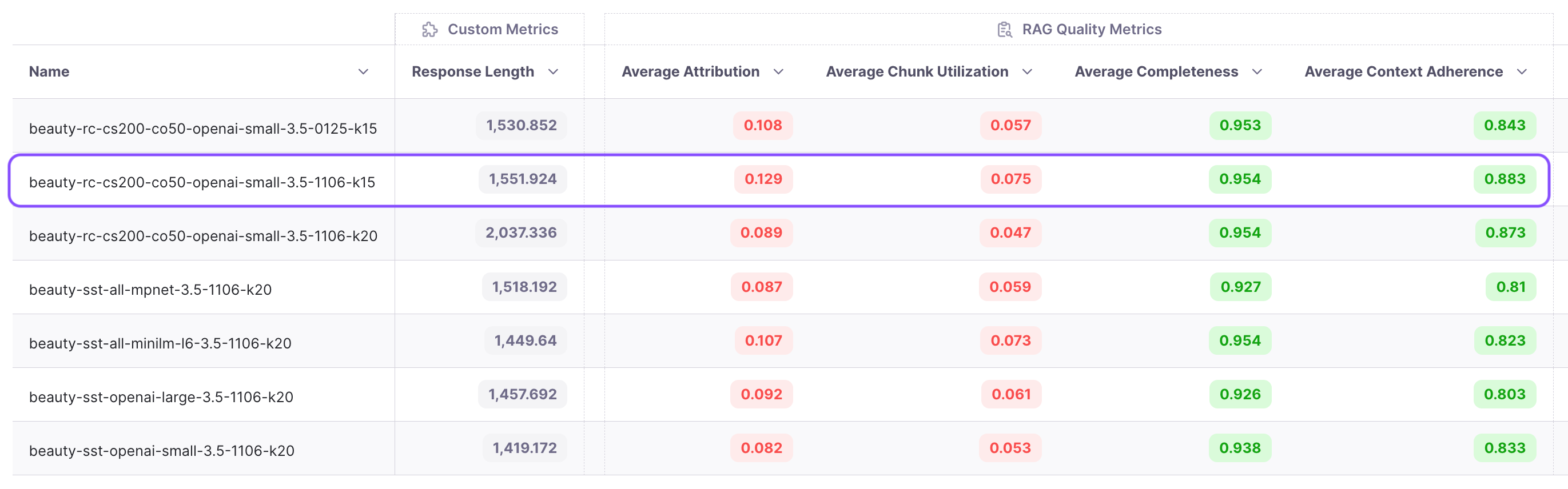
The cost significantly decreases from $0.126 to $0.098, marking a substantial 23% reduction!
Improve cost and latency
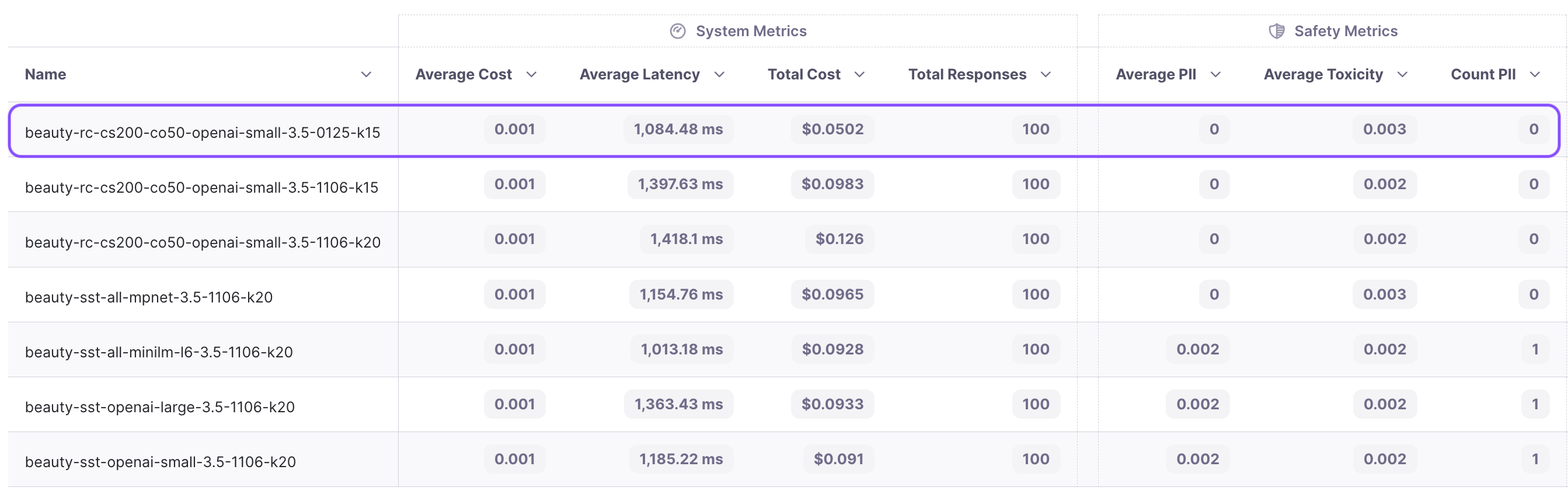
Now, let's embark on one final experiment to really push the envelope. We adopt our latest and best configuration, utilizing text-embedding-3-small, recursive chunking with a chunk size of 200 and a chunk overlap of 50. Additionally, we adjust the k value to 15 and switch the LLM to gpt-3.5-turbo-0125 (the latest release from OpenAI).
The results are quite surprising – there is a significant 22% reduction in latency and a substantial 50% decrease in cost. However, it comes with the tradeoff of a drop in adherence from 88.3 to 84.3.
Like many situations, users need to consider the tradeoff between performance, cost, and latency for their specific use case. They can opt for a high-performance system with a higher cost or choose a more economical solution with slightly reduced performance.
Recap
We’ve now demonstrated how Galileo’s GenAI Studio can give you unmatched visibility into your RAG workflows. As we saw, the RAG and system-level metrics streamline the selection of configurations and enable on-going experimentation to maximize performance while minimizing cost and latency.
In only an hour, we reduced hallucinations, increased retrieval speed, and cut costs in half!.
Watch a recording of this Q&A example to see GenAI Studio in action
Conclusion
The complexity of RAG demands innovative solutions for evaluation and optimization. While the benefits of RAG over fine-tuning make it an attractive choice, manual and time-consuming evaluation and experimentation limit its potential for AI teams.
Galileo's RAG analytics offer a transformative approach, providing unparalleled visibility into RAG systems and simplifying evaluation to improve RAG performance. Try GenAI Studio for yourself today!
Subscribe to Newsletter
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
