Introducing Galileo Protect: Real-Time Hallucination Firewall 🛡️
Generative AI and LLM Insights: April 2024


Table of contents
- The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
- Even LLMs need education – quality data makes LLMs over-perform
- How Do Language Models Put Attention Weights over Long Context?
- Supporting Diverse ML Systems at Netflix
- A Visual Guide to Mamba and State Space Models
- Building Meta’s GenAI Infrastructure
Smaller LLMs can be better (if they have a good education), but if you’re trying to build AGI you better go big on infrastructure! Check out our roundup of the top generative AI and LLM articles for April 2024.
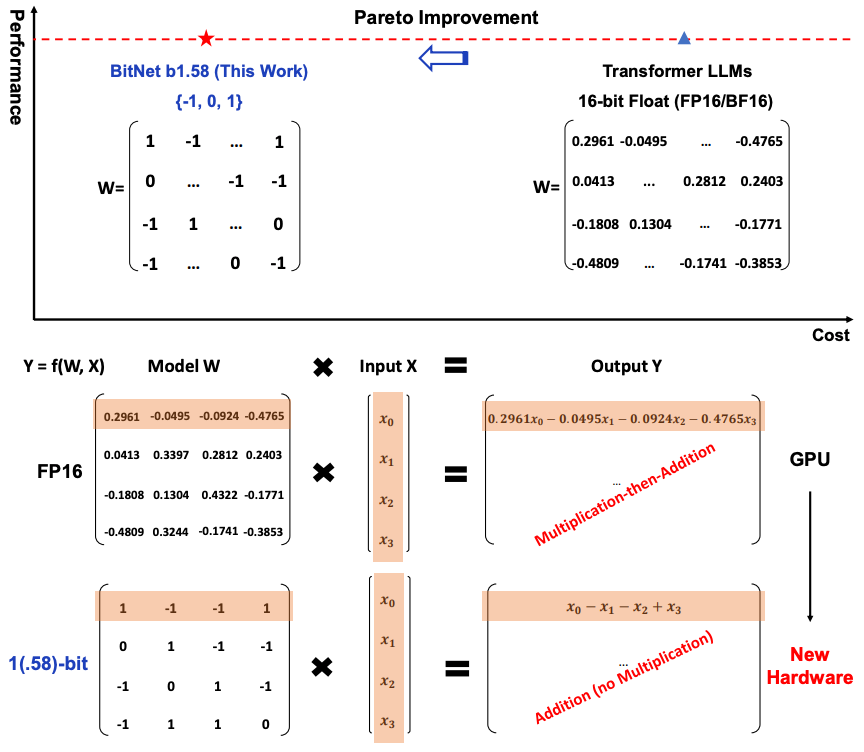
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Faster and cheaper! 1-bit LLMs have huge potential to reduce the carbon footprint and costs of generative AI. Read the full research paper to learn more about the latest in LLMs: https://arxiv.org/abs/2402.17764

Even LLMs need education – quality data makes LLMs over-perform
Smaller LLMs help dramatically save costs for AI teams. It only takes quality data to make these bite-size LLMs over-perform: https://stackoverflow.blog/2024/02/26/even-llms-need-education-quality-data-makes-llms-overperform/


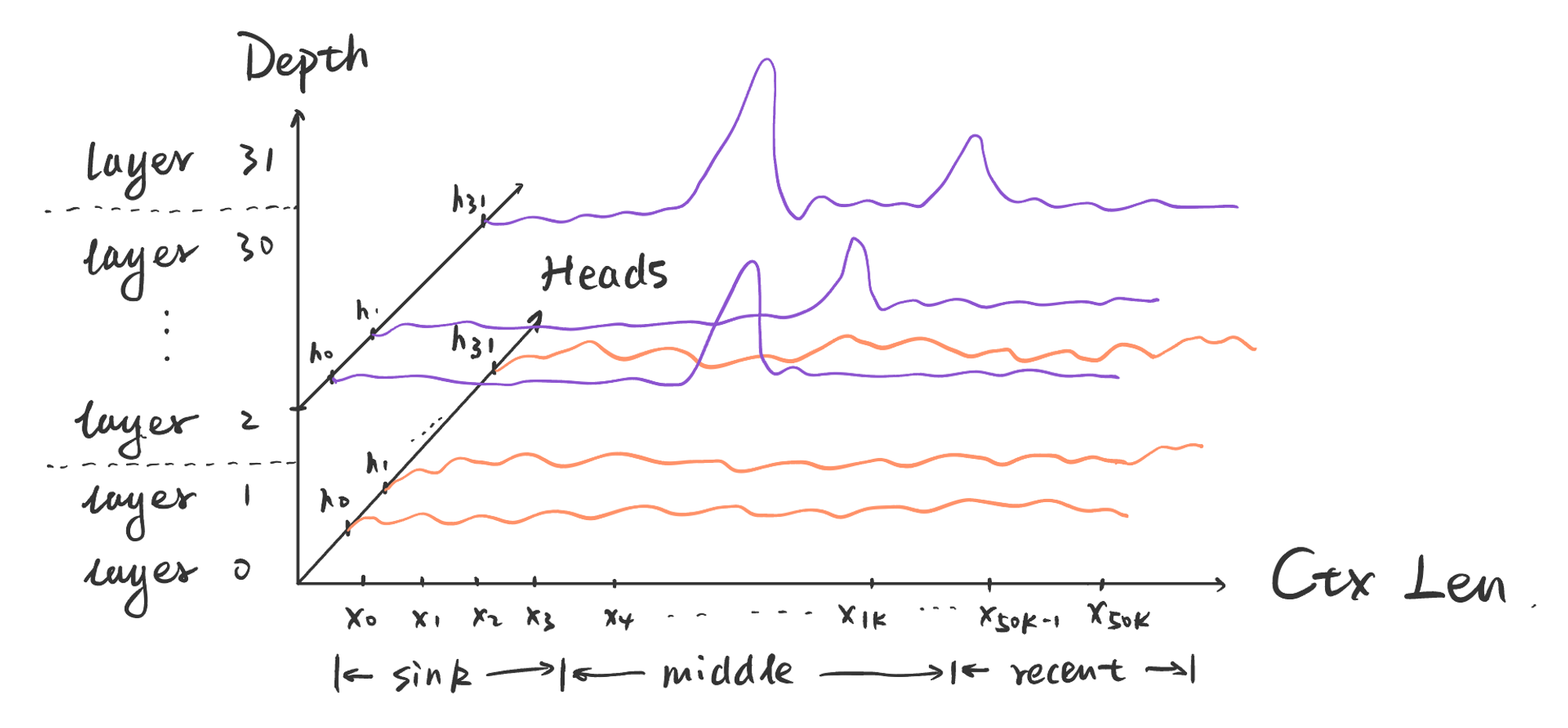
How Do Language Models Put Attention Weights over Long Context?
Attention please! How do LLMs pay attention to ever-growing 100k+ token context? Learn the six common attention patterns across all transformation layers and heads: https://yaofu.notion.site/How-Do-Language-Models-put-Attention-Weights-over-Long-Context-10250219d5ce42e8b465087c383a034e

Supporting Diverse ML Systems at Netflix
The ML Platform team at Netflix touches every part of the business, from internal infrastructure to demand modeling to media analysis. Explore their stack, layer by layer, including real-life projects: https://netflixtechblog.com/supporting-diverse-ml-systems-at-netflix-2d2e6b6d205d


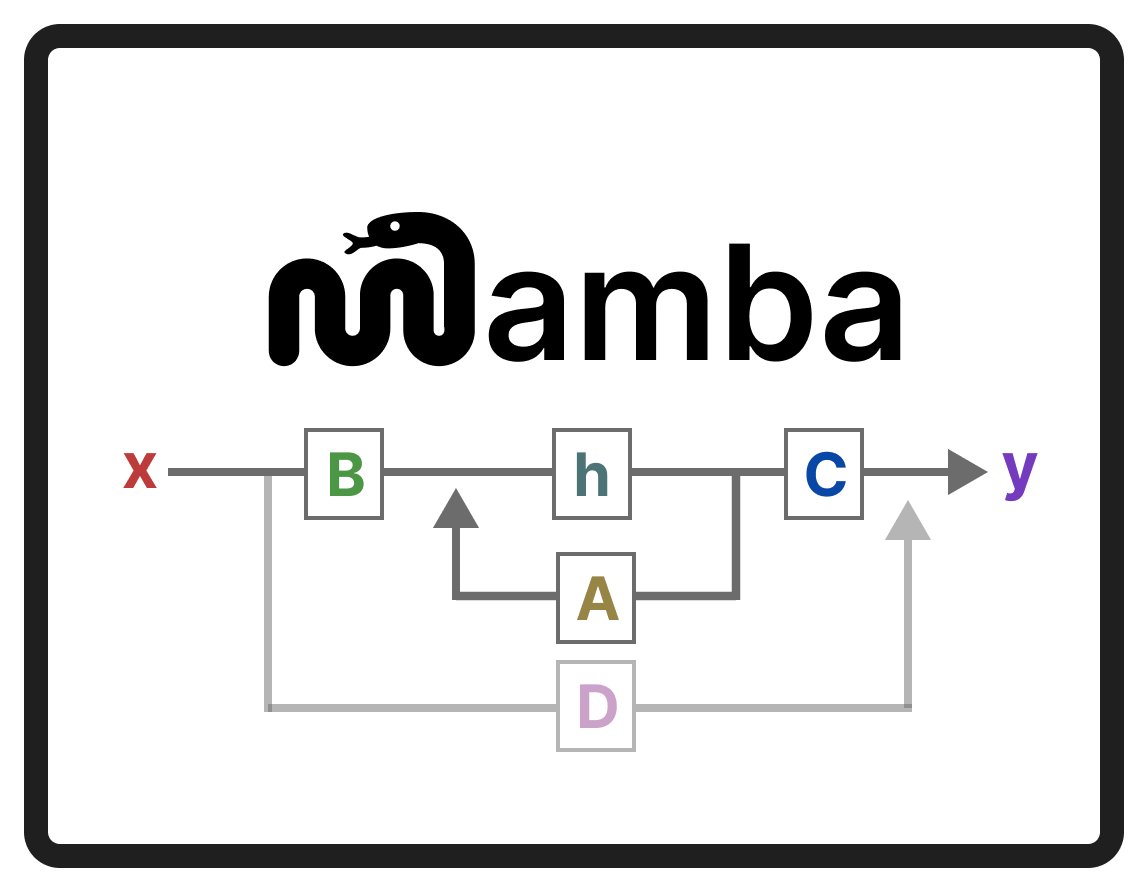
A Visual Guide to Mamba and State Space Models
Transformers are so 2023... State space models (like Mamba) offer unique advantages over transformer architecture. Check out this visual break down, covering the problem with transformers, an overview of state space models, and why Mamba in particular: https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mamba-and-state

Building Meta’s GenAI Infrastructure
Meta is building jaw-dropping GenAI infrastructure to power the development of AGI. Their AI superclusters are at the heart of this new endeavor: https://engineering.fb.com/2024/03/12/data-center-engineering/building-metas-genai-infrastructure/


Table of contents
- The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
- Even LLMs need education – quality data makes LLMs over-perform
- How Do Language Models Put Attention Weights over Long Context?
- Supporting Diverse ML Systems at Netflix
- A Visual Guide to Mamba and State Space Models
- Building Meta’s GenAI Infrastructure
Subscribe to Newsletter
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
