HP + Galileo Partner to Accelerate Trustworthy AI
Understanding LLM Hallucinations Across Generative Tasks




Table of contents
LLM Hallucinations are a critical deterrent to enterprise adoption. Mitigating hallucinations comes down to ensuring we work with the suitable model, prompts, data, and context through a vector database.
Let’s dive deep into LLM hallucinations and understand them a bit better.
What are hallucinations in LLMs?
The creation of human-like text with Natural Language Generation (NLG) has improved recently because of advancements in Transformer-based language models. This has made the text produced by NLG helpful for creating summaries, generating dialogue, or transforming data into text. However, there is a problem: these deep learning systems sometimes make up or "hallucinate" text that was not intended, which can lead to worse performance and disappoint users in real-world situations.
Hallucination in AI means the AI makes up things that sound real, but are either wrong or not related to the context. This often happens because the AI has built-in biases, doesn't fully understand the real world, or its training data isn't complete. In these instances, the AI comes up with information it wasn't specifically taught, leading to responses that can be incorrect or misleading.
There are also a few terms that often cause confusion.
- Faithfulness: The opposite of hallucination, this means the output stays true to what the source says.
- Factuality: This means the output is true or based on facts. But what we consider "fact" might be different - some people say it's world knowledge, while others say it's what the source says. Because of this, factuality might or might not be the same as faithfulness.
Hallucinations can affect important choices, such as court cases or when dealing with a company's reputation, like what happened with Google’s Bard. They can also expose private information the model saw during training, cause mistakes in medical diagnoses due to incorrect patient summaries, or simply lead to a frustrating chatbot experience that can't answer a basic question.
This is why understanding and mitigation of hallucination is important.
Types of hallucinations
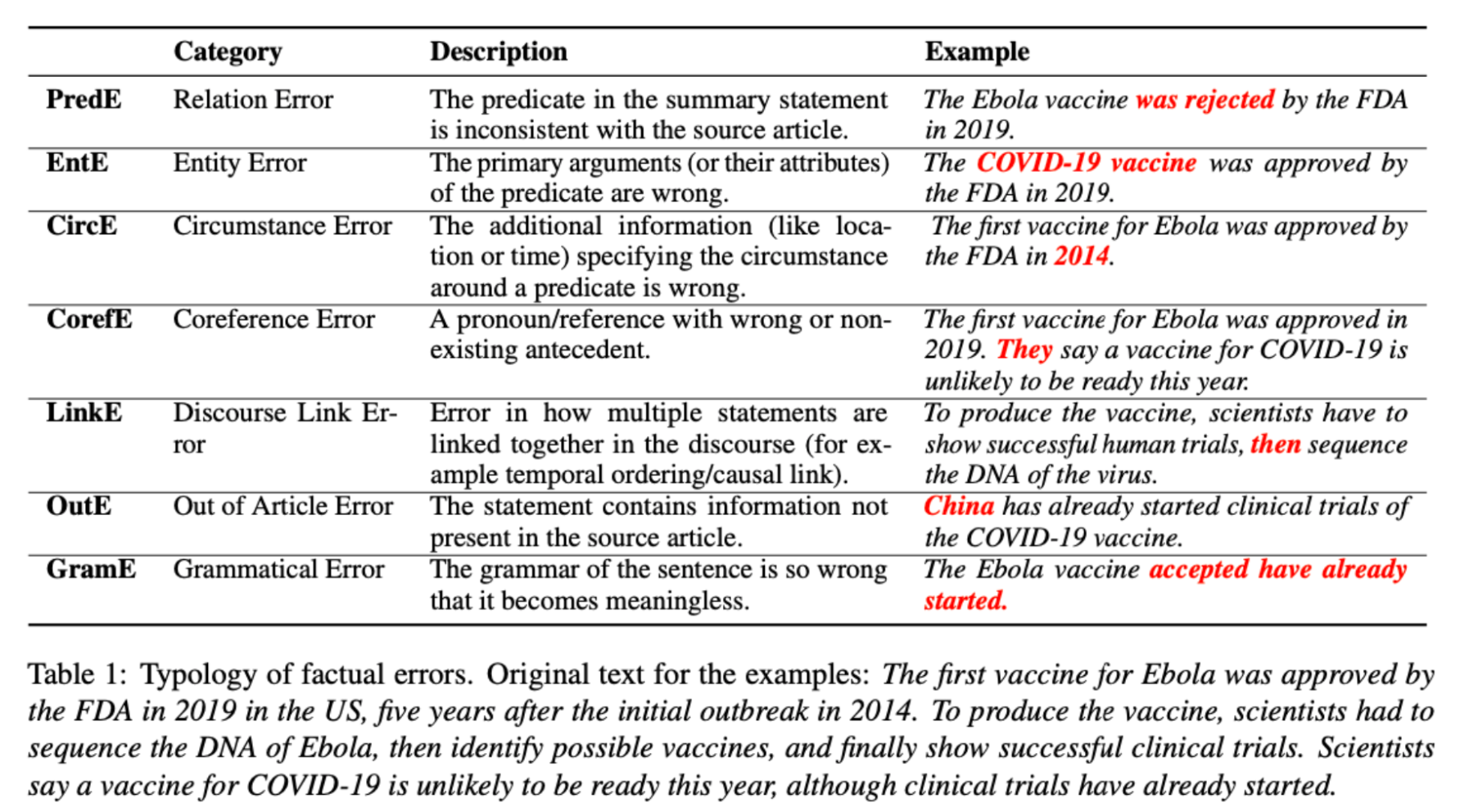
- "Intrinsic Hallucinations:" These are made-up details that directly conflict with the original information. For example, if the original content says "The first Ebola vaccine was approved by the FDA in 2019," but the summarized version says "The first Ebola vaccine was approved in 2021," then that's an intrinsic hallucination.
- "Extrinsic Hallucinations:" These are details added to the summarized version that can't be confirmed or denied by the original content. For instance, if the summary includes "China has already started clinical trials of the COVID-19 vaccine," but the original content doesn't mention this, it's an extrinsic hallucination. Even though it may be true and add useful context, it's seen as risky as it's not verifiable from the original information.
Let's have a look at hallucinations in different generative tasks:

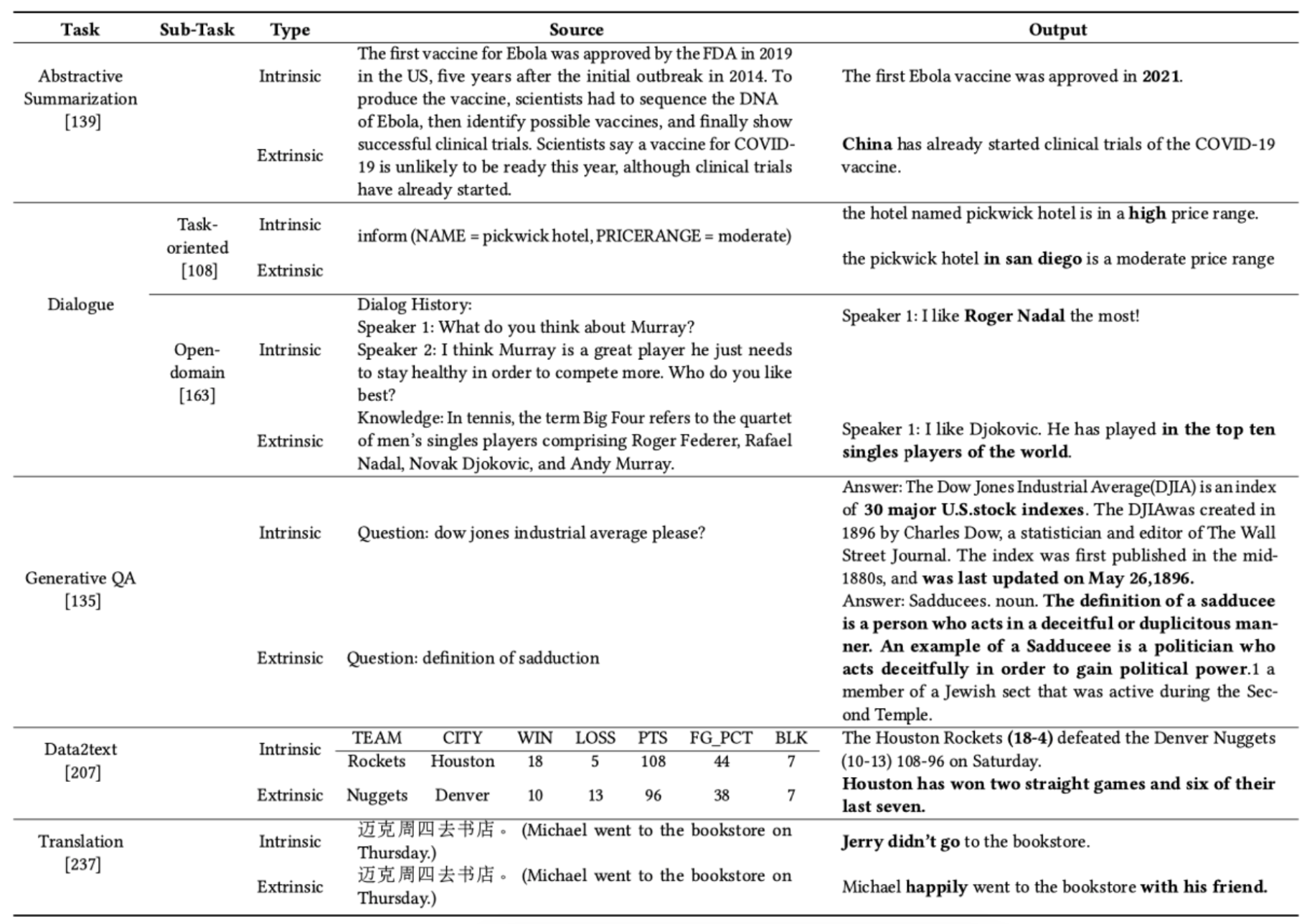
Generative task 1: Abstractive summarisation
Abstractive summarization is a method used to pick out important details from documents and create short, clear, and easy-to-read summaries. These have seen impressive results when done with neural networks. However, studies have found issues, such as these models often producing misleading content that doesn't match the original document. It's shown that 25% of the summaries from the best current models have this problem [Falke et al.]. Summaries with a lot of misleading content can still get a higher ROUGE score [Lin et al.].
There are two types of hallucination in summarization -- intrinsic, where the summary says something opposite to the original text, and extrinsic, where the summary includes something not mentioned in the original at all. For example, if an article says the FDA approved the first Ebola vaccine in 2019, an intrinsic hallucination would be to say the FDA rejected it. An extrinsic hallucination example might be to claim that China has started testing a COVID-19 vaccine when the original article doesn't mention that at all.
In addition to this, Pagnoni and his colleagues describe more detailed types of factual errors in summaries.

Generative task 2: Dialogue generation
In open domain dialogue generation, a chatbot either gives the user necessary details or keeps them interested with new replies without rehashing previous conversation. A little bit of hallucination might be acceptable in this context.
Intrinsic hallucination is when the chatbot's response contradicts the previous conversation or external knowledge. As shown in table 1, the bot might incorrectly interpret a moderate price range as high, or mix up names like 'Roger Federer' and 'Rafael Nadal.'
Extrinsic hallucination happens when we can't cross-check the chatbot's response with previous dialogue or outside knowledge. For instance, as shown in table 1, the bot might claim something about the Pickwick hotel being in San Diego or Djokovic being in the top ten singles players, but without enough information to confirm or deny this.
Now, let's talk about open-domain dialogue creation. Inconsistency within the bot's responses is a type of intrinsic hallucination, while inconsistency with outside sources can be either intrinsic or extrinsic hallucination.
In open-domain conversation, a little hallucination may be fine as long as it doesn't include serious factual errors. But it's usually hard to verify the facts because the system doesn't usually have access to outside resources. In these systems, inconsistencies in the bot's replies are often seen as the main problem. You can see this when a bot gives different answers to similar questions, like “What's your name?” and “May I ask your name?” A focus here is the bot's persona consistency - its identity and interaction style - and making sure it doesn't contradict itself. Aside from this, a chatbot in the open domain should provide consistent and informative responses that align with the user's speech to keep the conversation engaging. External resources with specific persona information or general knowledge can help the chatbot create responses.
Generative task 3: Retrieval Augmented Generation
Retrieval Augmented Generation(RAG) is a system that creates in-depth responses to questions instead of just pulling out answers from given texts. This is useful because many questions people ask on search engines need detailed explanations. These answers are typically long and can't be directly taken from specific phrases.
Usually, a GQA system looks for relevant information from different sources to answer a question. Then, it uses this information to come up with an answer. In many instances, no single document has the complete answer, so multiple documents are used. These documents might have repeating, supporting, or conflicting information. Because of this, the generated answers often contain hallucinations.
Table 1 shows two examples of hallucination for GQA. The information for both questions comes from Wikipedia. The first question asks about the "Dow Jones Industrial Average." The response given, "index of 30 major U.S. stock indexes," doesn't match with the Wikipedia explanation, "of 30 notable companies listed on U.S. stock exchanges." So we call this an "intrinsic hallucination." For the second question, the description of a Sadducee as someone who behaves dishonestly, particularly a politician seeking power through dishonesty, couldn't be confirmed from the original Wikipedia documents. As a result, we label it as an "extrinsic hallucination.


Source: Benchmarking Large Language Models in Retrieval-Augmented Generation
A recent paper describes 4 scenarios where the LLM needs to be robust to avoid hallucinations.
Noise Robustness: LLM extracts useful information from documents that are relevant but don't contain the answer.
Negative Rejection: LLM refuses to answer when the required information isn't in the retrieved documents.
Information Integration: LLM can answer complex questions requiring information from multiple documents.
Counterfactual Robustness: LLM can recognize factual errors in retrieved documents when warned about potential risks.
We covered other RAG hallucination scenarios in our in-depth evaluation guide for RAG.
Generative task 4: Neural machine translation


- Intrinsic errors occur when the translation includes incorrect details compared to the original text. For example, if the original text mentions "Mike" but the translation says "Jerry doesn’t go," that's an intrinsic error.
- Extrinsic errors happen when the translation adds new information that wasn't in the original text. For example, if the translation includes "happily" or "with his friend" but these details aren't in the original text, that's an extrinsic error.
There are also other ways to classify these errors. One group suggests splitting them into errors seen with altered test sets and natural errors. The first type can be seen when changing the test set drastically alters the translation. The second type, natural errors, is connected to errors in the original dataset. These can be split again into detached and oscillatory errors [Raunak et al.]. Detached errors happen when the translation doesn't match the meaning of the original text. Oscillatory errors happen when the translation repeats phrases that weren't in the original text.
Other errors include suddenly skipping to the end of the text or when the translation is mostly in the original language. These are all considered types of hallucination errors in machine translation.
Generative task 5: Data to text generation
Data-to-Text Generation is the process of creating written descriptions based on data like tables, database records, or knowledge graphs.
- Intrinsic Hallucinations is when the created text includes information that goes against the data provided. For instance, if a table lists a team's win-loss record as 18-5, but the generated text says 18-4, that's an Intrinsic Hallucination.
- Extrinsic Hallucinations is when the text includes extra information that isn't related to the provided data. An example would be if the text mentioned a team's recent wins, even though that information wasn't in the data.
Conclusion
The advancements in Transformer-based language models have greatly enhanced the capabilities of Natural Language Generation. However, the occurrence of 'hallucinations,' where the AI fabricates incorrect or out-of-context details, pose significant challenges. These inaccuracies can occur in various tasks such as abstractive summarization, dialogue generation, generative question answering, machine translation, data-to-text generation, and vision-language model generation.
Addressing the issue of hallucinations in AI is crucial to increase the reliability and usability of such systems in real-world applications. By continuing research and development in these areas, we can hope to mitigate these issues and leverage the full potential of AI in language understanding and generation tasks. We will look into ways to mitigate it in our next posts.
Galileo GenAI Studio is the leading platform for rapid evaluation, experimentation and observability for teams building LLM-powered applications. It is powered by a suite of metrics to identify and mitigate hallucinations. Get started today!
Explore our research-backed evaluation metric for hallucination – read our paper on Chainpoll.
References
Survey of Hallucination in Natural Language Generation [Ziwei et al.]
The Curious Case of Hallucinations in Neural Machine Translation [Raunak et al.]
Detecting Hallucinated Content in Conditional Neural Sequence Generation [Zhou et al.]
Table of contents
Subscribe to Newsletter
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
