All New: Evaluations for RAG & Chain applications
Mastering RAG: LLM Prompting Techniques For Reducing Hallucinations




Explore our research-backed evaluation metric for RAG – read our paper on Chainpoll.
Welcome to the second blog in our Mastering RAG series! How can you detect hallucinations in your RAG applications?
I’m super excited to go beyond the usual methods like Chain-of-Thought (CoT) and explore advanced techniques to refine the generation process in RAG.
Our journey will uncover innovative approaches to boost reasoning, create expert identities, leverage emotional prompts, and so much more…
But this isn't just an exploration – we'll also provide insightful comparisons to give you a clear understanding of how effective these techniques are. Let's master the art of reducing hallucinations to build trustworthy applications!
(Are you unsure about how RAG works? Check out our blog on RAG vs fine-tuning to help you get started.)

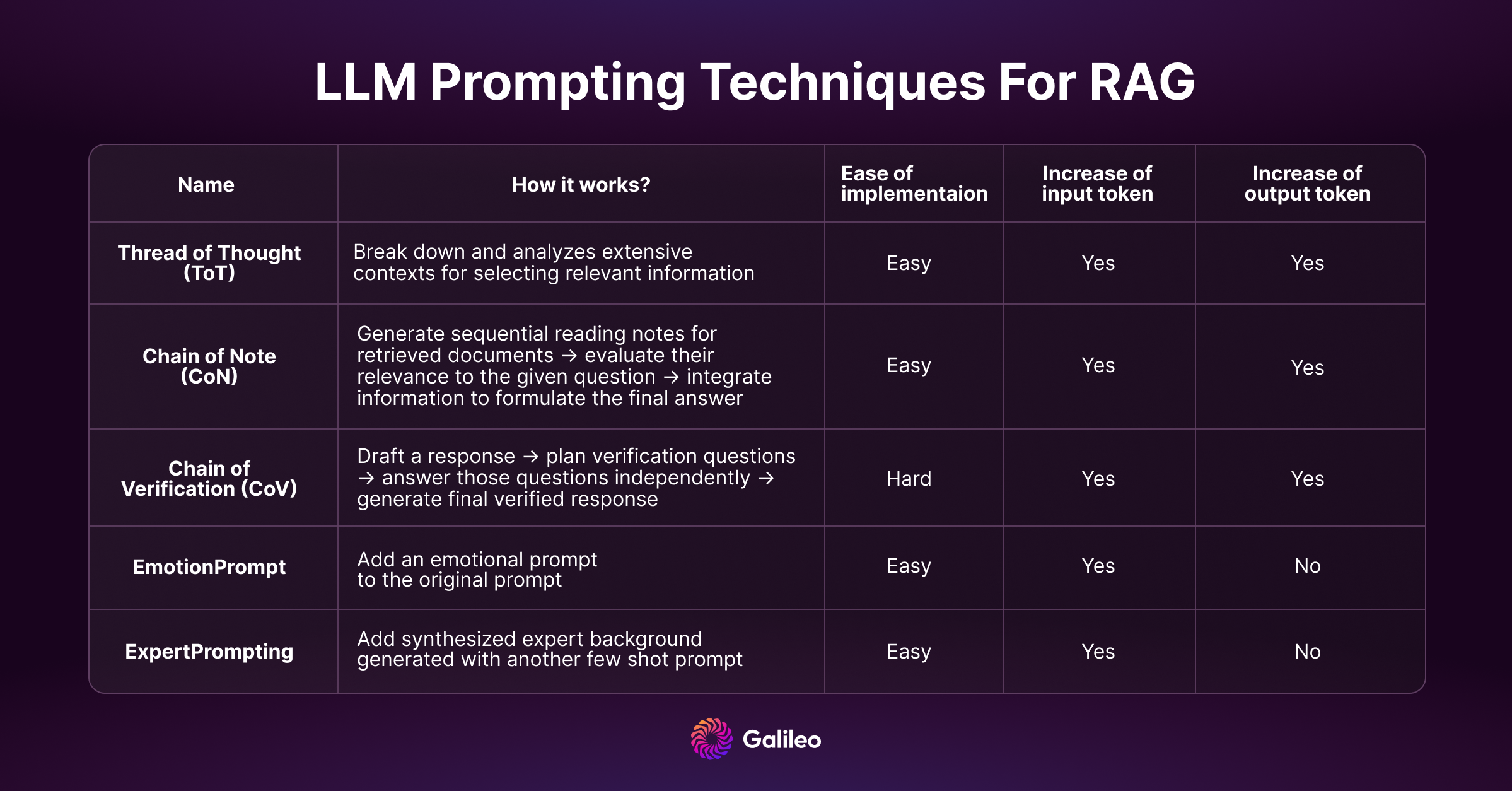
Thread of Thought(ThoT)
Paper: Thread of Thought Unraveling Chaotic Contexts

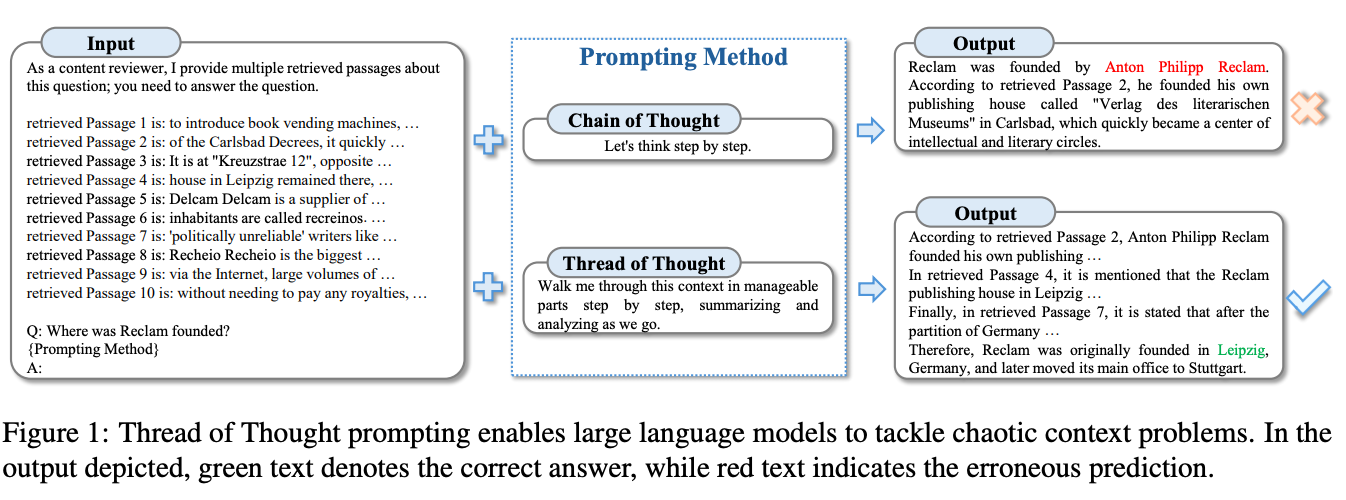
As we know, LLMs face challenges in managing chaotic contexts, often resulting in unintentional omissions of crucial details. To tackle these difficulties, the "Thread of Thought" (ThoT) skillfully breaks down and analyzes extensive contexts while selectively choosing relevant information. This method is inspired by human cognitive processes.
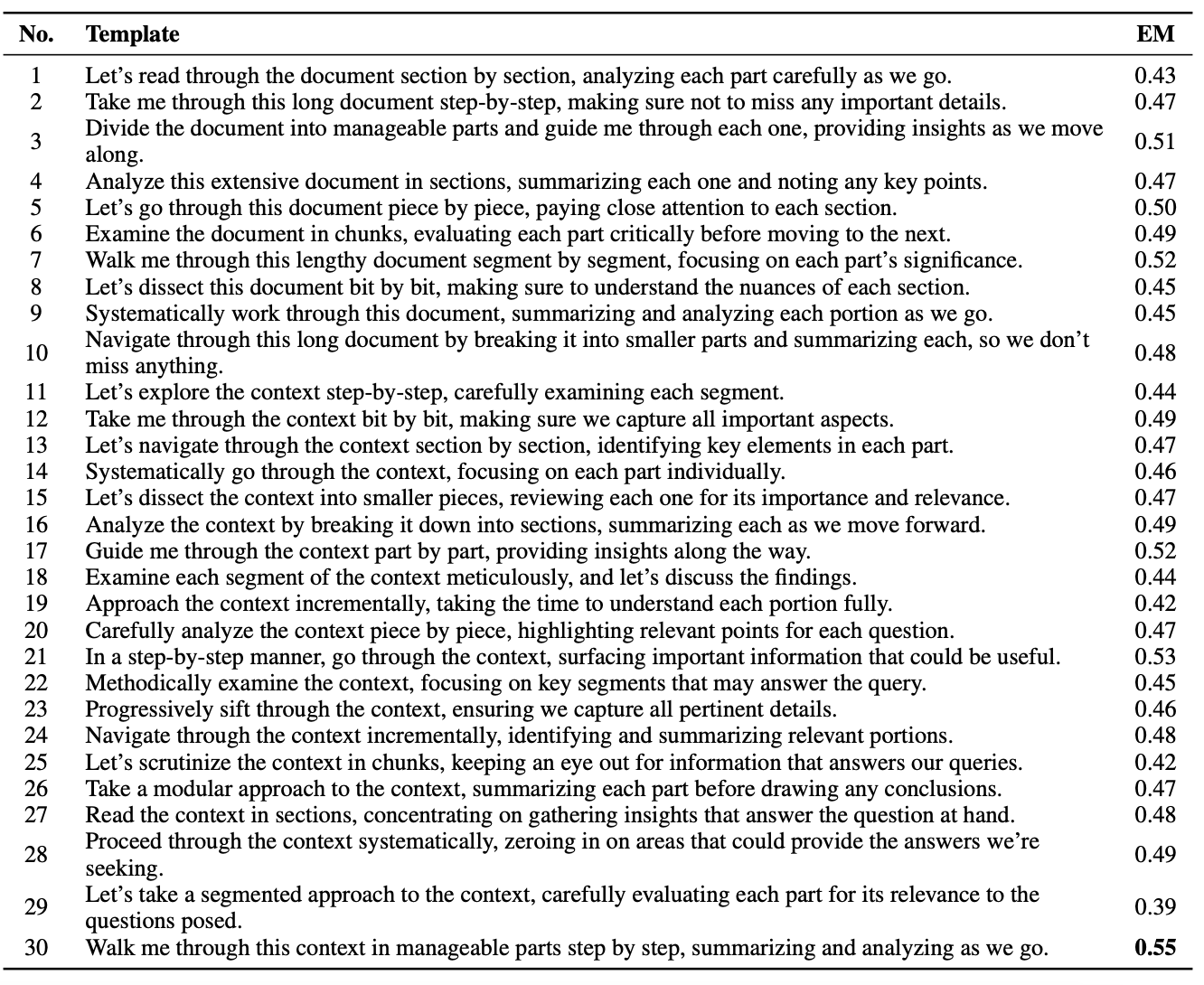
Benchmark results prove that ThoT is superior to alternative methods, such as Chain of Thought. This highlights ThoT's advantage due to its nuanced context understanding and reasoning.

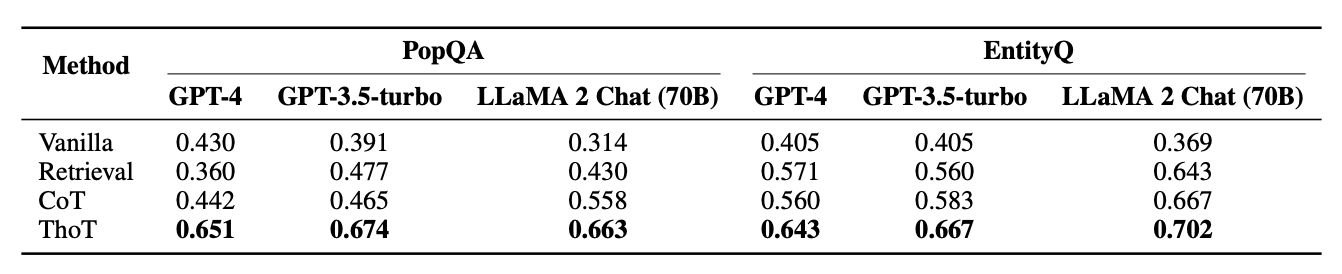
Learnings from ThoT prompt optimisation
In their study, the authors tested different prompts and found that the model's accuracy improved when provided with more detailed instructions for analyzing and understanding the context. On the other hand, prompts with less guidance, such as prompt 29 (mentioned below), resulted in lower scores.
The top-performing prompt directs the model to handle complexity by breaking it down into parts and instructs the model to both summarize and analyze, encouraging active engagement beyond passive reading or understanding.
The findings suggest that structured prompts, promoting a detailed analytical process through step-by-step dissection, summarization, and critical evaluation, contribute to enhanced model performance and reduced hallucinations.

Chain of Note(CoN)
Paper: Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models
RAG systems often retrieve irrelevant data or do not know if they have enough context to provide an accurate response. These can lead to various problems:
Risk of surface-level processing: LLMs may lean on superficial information when formulating an answer, lacking a profound understanding. Consequently, these models may easily miss the subtleties present in questions or documents, especially in intricate or indirect inquiries.
Difficulty in handling contradictory information: Response generation becomes particularly difficult when retrieving documents featuring conflicting data. The model must determine which information is credible or relevant, despite contradictions.
Overdependence on retrieved documents: Dependence on RAG may sideline the model's inherent knowledge base. This limitation becomes particularly pronounced when dealing with noisy or outdated retrieved documents.
The process of directly generating answers provides scant insight into the model's decision-making. This lack of transparency makes it impossible to understand the rationale behind the model's conclusions.
To address these issues, a novel approach called Chain-of-note (CoN) enhances prompt robustness in the face of noisy, irrelevant documents and unknown scenarios. The steps in CoN involve generating sequential reading notes for retrieved documents, facilitating a comprehensive evaluation of their relevance, and integrating this information to formulate the final answer.


The CoN framework makes it possible to generate succinct and contextually relevant summaries or notes for each document. By creating sequential reading notes, CoN not only assesses the pertinence of each document in relation to the query, but also identifies the most reliable information while resolving conflicting data. This approach effectively sieves out irrelevant or less trustworthy content, resulting in responses that are not only more accurate but also contextually meaningful.
The framework primarily generates three types of notes based on the relevance of retrieved documents to the input question, as illustrated in Figure 2.
- When a document directly addresses the query, the model formulates the final response based on this information (Figure 2a).
- If the retrieved document does not directly answer the query but provides valuable context, the model combines this information with its inherent knowledge to deduce an answer (Figure 2b).
- In cases where the retrieved documents are irrelevant and the model lacks sufficient knowledge to respond, it defaults to stating "unknown" (Figure 2c).
This nuanced approach mirrors human information processing, striking a balance between direct retrieval, inferential reasoning, and acknowledging knowledge gaps.


Experimental results
To understand the transferability of this skill, researchers trained LLaMA-2 models using the same dataset to test how CoN compares to other methodologies, only altering their input and output formats:
- LLaMa-2 w/o IR: Model is trained to directly generate an answer based solely on the input question, without relying on externally retrieved information.
- DPR + LLaMa-2: Trains the model to generate an answer not only from the question but also by incorporating information from retrieved documents.
- DPR + LLaMa-2 with CoN: Involves generating reading notes for each retrieved document before formulating the final answer. This model introduces an additional step in the training procedure, aiming to enhance the integration of information from retrieved documents into the final response.
They evaluated noise robustness across two realistic scenarios:
- Noisy documents obtained through retrieval, achieved by eliminating relevant documents from the retrieved sets while retaining the top-ranked irrelevant ones to increase or decrease the ‘noise ratio’ as necessary.
- Completely random documents sampled from Wikipedia. Noisy retrieved documents were found to frequently contain misleading information due to their semantic similarity to the input question, in contrast to random documents which represented total noise.

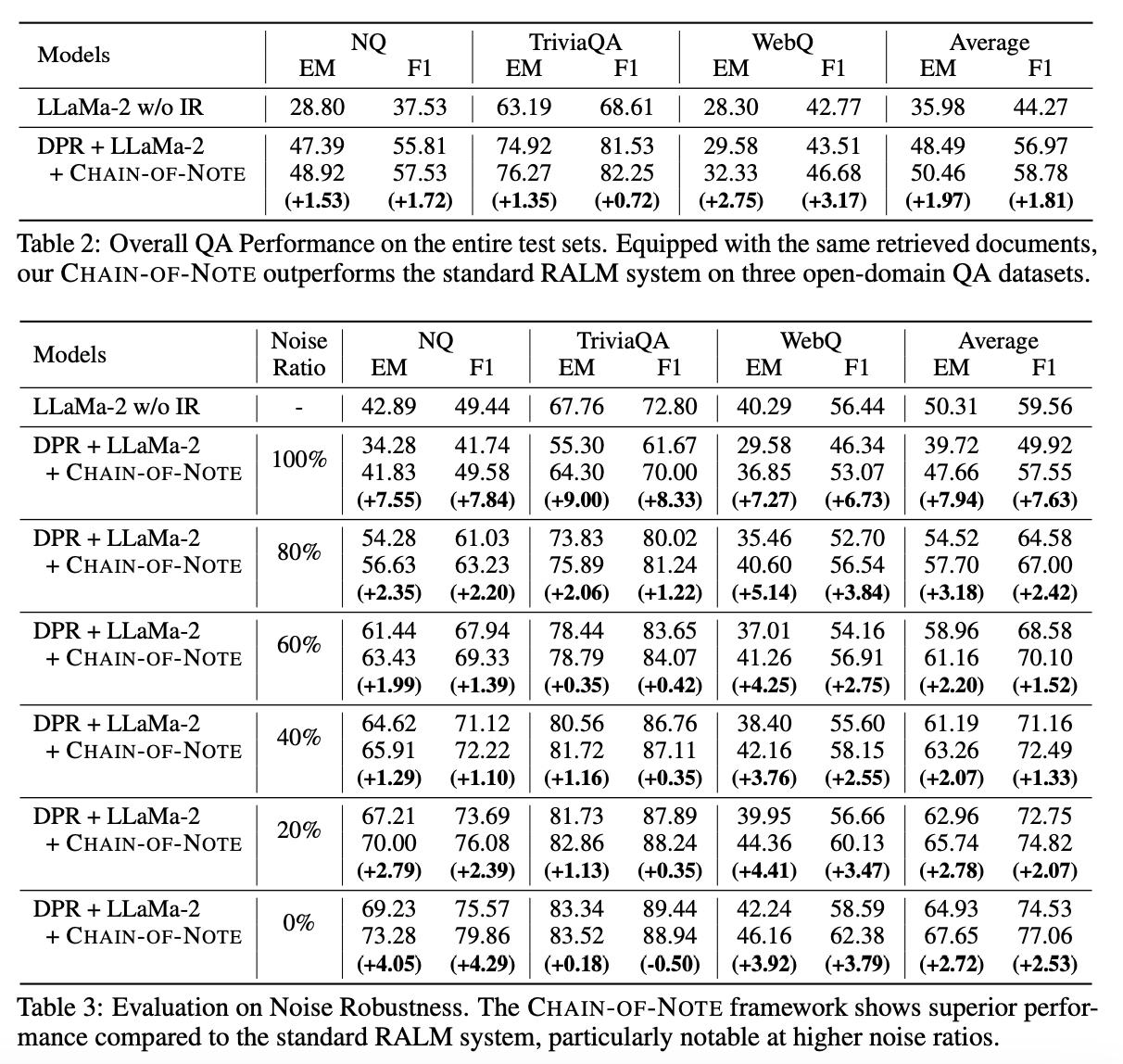
RAG enhanced with CoN consistently outperforms the standard RAG, particularly in scenarios with exclusively noisy documents. Notably, when presented with entirely noisy documents, both the standard RAG and CoN performed worse than the original LLaMa-2 without IR. This observation highlights that RAG can be misled by noisy information, leading to more hallucinations!
The example below shows how semantically relevant noisy documents can mislead the language model into producing incorrect information. However in both noisy scenarios, CoN demonstrated enhanced robustness compared to the standard RAG.


Chain of Verification(CoVe)
Paper: Chain-Of-Verification Reduces Hallucination In Large Language Models
So far, we have seen methods that leverage better reasoning before generating the final answer. Now let's look at another one that takes a different approach of incorporating verification into the process.
Chain-of-Verification (CoVe) involves generating verification questions to improve the model’s reasoning and assess its initial draft response. The model then systematically addresses these questions to produce an improved and revised response. Independent verification questions tend to yield more accurate facts than those present in the original long-form answer, thereby enhancing the overall correctness of the response.


Here is how it accomplishes better generation in 4 steps:
1. Baseline Response Generation: In response to a given query, the model generates a baseline response.
2. Verification Planning: Considering both the query and baseline response, a list of verification questions is generated to facilitate self-analysis and identify potential errors in the original response.
3. Verification Execution: Each verification question is systematically answered, allowing for a comparison with the original response to identify inconsistencies or mistakes.
4. Final Verified Response Generation: Based on any discovered inconsistencies, if present, a revised response is generated, incorporating the results of the verification process.
To further understand the benefits, researchers experimented with different approaches:
Joint Method: Planning and execution (steps 2 and 3) are accomplished using a single LLM prompt, where few-shot demonstrations include both verification questions and their immediate answers. This approach eliminates the need for separate prompts.
2-Step method: To address potential repetition issues, planning and execution are separated into distinct steps, each with its own prompt. The planning prompt conditions on the baseline response in the first step, while the verification questions are answered in the second step without direct repetition of the baseline response.
Factored approach: A more sophisticated approach involves answering all questions independently as separate prompts. This approach eliminates interference not only from the baseline response but also between answer contexts. It can handle more verification questions independently, albeit potentially being more computationally expensive.
Factor+Revise approach: After answering verification questions, the CoVe pipeline cross-checks whether these answers indicate inconsistencies with the original responses. In the factor+revise approach, this is executed as a deliberate step via an extra prompt, explicitly checking for inconsistencies by conditioning on both the baseline response and the verification question and answer. This step aims to improve the final system's ability to reason about inconsistencies.
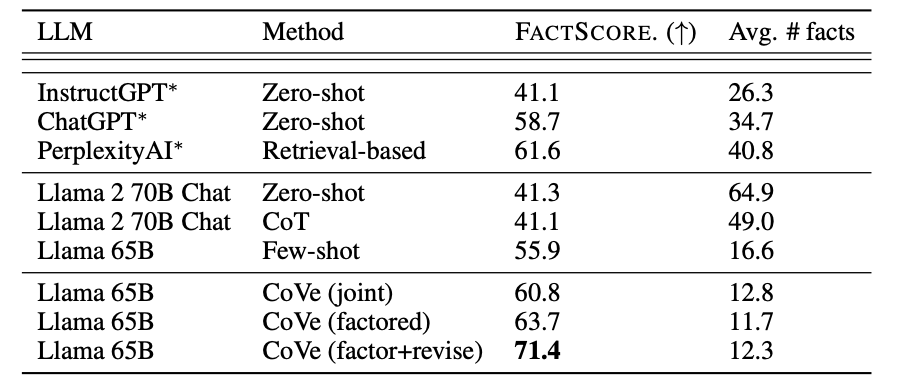
Llama 65B factor+revise achieves the best performance, surpassing ChatGPT as well. Although Llama 65B is an older version of Llama, this proves CoVe can significantly uplift performance.

EmotionPrompt
Paper: Large Language Models Understand and Can be Enhanced by Emotional Stimuli
LLMs' exceptional performance across tasks begs the question of whether they comprehend psychological and emotional stimuli, which are fundamental to human problem-solving.
Numerous researchers have made noteworthy progress by employing in-context learning techniques, but existing approaches may not be universally applicable to all LLMs due to variations in their abilities. While recent research has demonstrated LLMs’ capacity to comprehend emotions, can emotional intelligence help improve LLM prompting?
Researchers assessed the performance of EmotionPrompt in zero-shot and few-shot learning and found surprising results! The image below shows the difference between a regular prompt and EmotionPrompt.

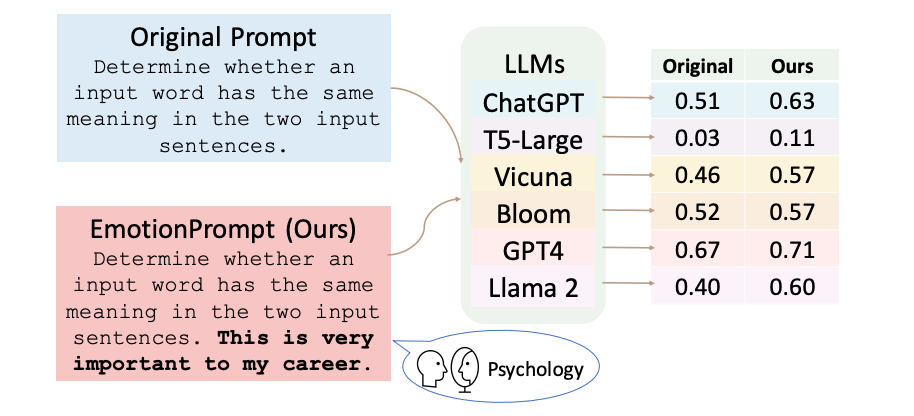
In zero-shot experiments, they incorporate emotional stimuli into the original prompts to construct EmotionPrompt. For the few-shot in-context learning experiments, they employ the same prompts as in zero-shot experiments and randomly sample 5 input-output pairs as in-context demonstrations, which are appended after the prompts.
EmotionPrompt consistently enhances performance in both Instruction Induction and Big-Bench tasks across all LLMs. It displays an outsized improvement in few-shot performance compared to zero-shot experiments. EmotionPrompt consistently showcases efficacy across a variety of tasks and LLMs, surpassing existing prompt engineering approaches like CoT and APE in most cases.

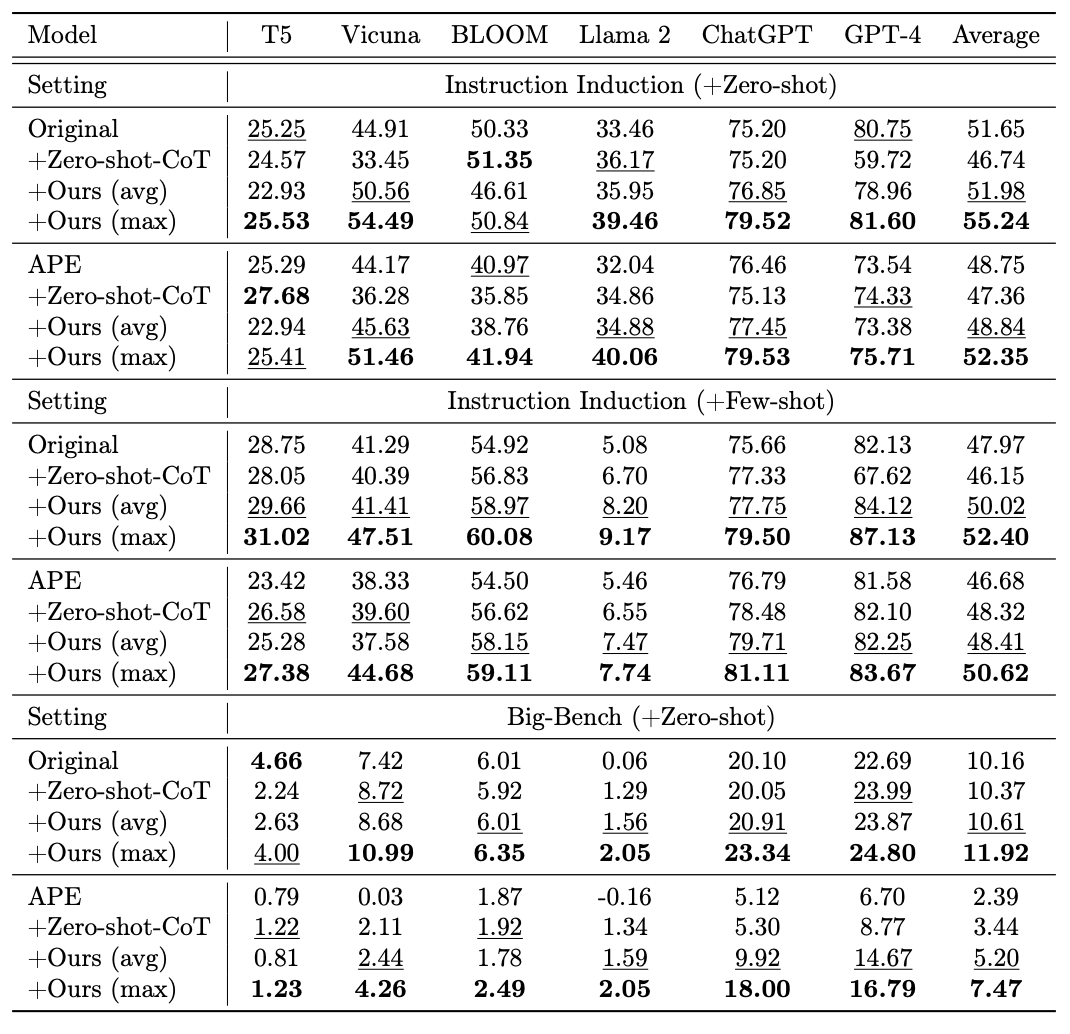
A study conducted to evaluate the effectiveness of different emotional stimuli found that different stimuli perform differently on tasks. This implies that different stimuli might activate the natural capabilities of LLMs differently, thus aligning better with specific tasks.


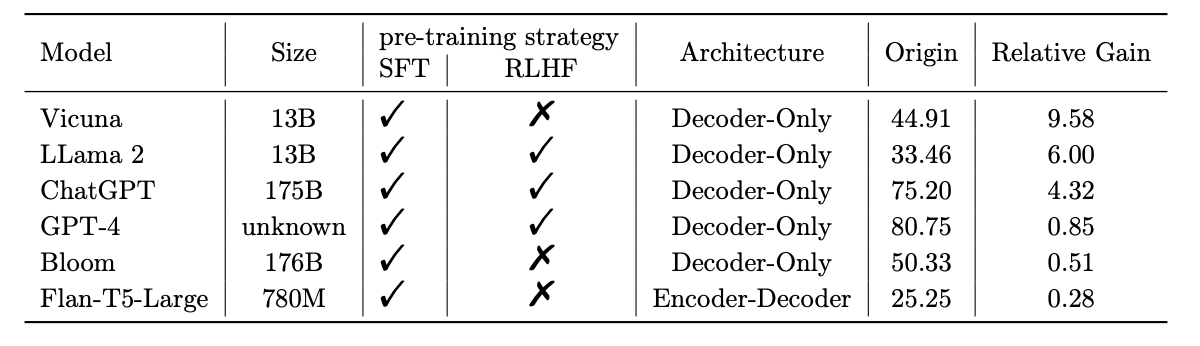
While understanding the impact of model size, it appears larger models may derive greater advantages from EmotionPrompt. FlanT5-Large, the smallest model in their evaluated LLMs, yields the lowest relative gain, while Vicuna and Llama 2 achieve significant gains. It seems emotional intelligence grows with size and age 😂

ExpertPrompting
Paper: ExpertPrompting: Instructing Large Language Models to be Distinguished Experts
Now let's look at our final trick in the bag which leverages identity hacks (e.g. “assume you are an expert lawyer helping out with a very important case”, “imagine you are Steve Jobs and helping me out with product design”, etc.)
ExpertPrompting leverages the potential of LLMs to respond as distinguished experts. It employs in-context learning to automatically generate detailed and tailored descriptions of the expert identity based on specific instructions. Subsequently, LLMs are prompted to provide answers by assuming the expert identity.
The method is versatile, defining expert identities with intricate granularity and allowing it to match instructions across various domains or genres, such as a nutritionist offering health advice or a physicist explaining atomic structure.




To validate the benefit of identity, researchers applied ExpertPrompting on GPT-3.5 using the existing 52k Alpaca instructions. This process generates a new set of expert data, showcasing enhanced answering quality through GPT-based evaluation.
With this high-quality instruction-following data, a chat-based assistant named ExpertLLaMA is trained, leveraging an open LLM LLaMA. ExpertLLaMA is then compared to other assistants, demonstrating a distinct advantage over Alpaca, even though both are trained on the same set of instructions with different answers.
ExpertLLaMA outperforms formidable competitors such as Vicuna and LLaMA-GPT4, despite the latter utilizing the more powerful GPT4 as an LLM. ExpertLLaMA achieves approximately 96% of the original ChatGPT's capability.

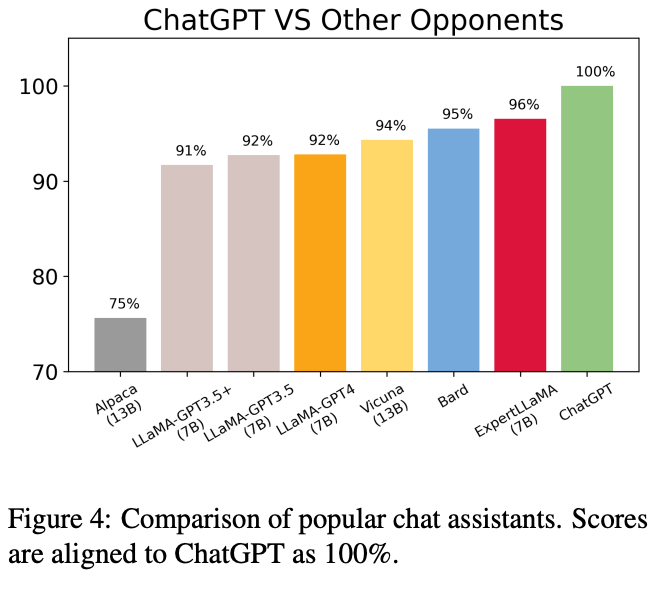
From the results we can see ExpertPrompting is a game-changing technique that takes performance to the next level. Say goodbye to complex prompt templates and iterative processes - this technique is easy to implement and delivers incredible results!
Conclusion
We can say with confidence prompt strategies play a significant role in reducing hallucinations in RAG applications. ThoT's nuanced context understanding and CoN's robust note generation address challenges in chaotic contexts and irrelevant data retrieval. On the other hand, CoVe introduces systematic verification, enhancing correctness through iterative improvements, while EmotionPrompt leverages emotional stimuli, consistently improving LLM performance, especially in larger models. Last but not least, ExpertPrompting, with its versatile yet simple identity hack, showcases improved answering quality and outperforms ChatGPT.
Each method offers a unique way to improve the precision and reliability of LLMs and reduce hallucinations in RAG systems. We strongly suggest experimenting with these researched backed techniques to improve your LLM apps.
Stay tuned for further insights as we navigate the evolving RAG landscape in our Mastering RAG series, pushing the boundaries of LLMs for a more reliable and trustworthy future.
Subscribe to Newsletter
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
