All New: Evaluations for RAG & Chain applications
Mastering RAG: Advanced Chunking Techniques for LLM Applications




Explore our research-backed evaluation metric for RAG – read our paper on Chainpoll.
What is chunking?
Chunking involves breaking down texts into smaller, manageable pieces called "chunks." Each chunk becomes a unit of information that is vectorized and stored in a database, fundamentally shaping the efficiency and effectiveness of natural language processing tasks.
Here is an example of how the character splitter splits the above paragraph into chunks using Chunkviz.

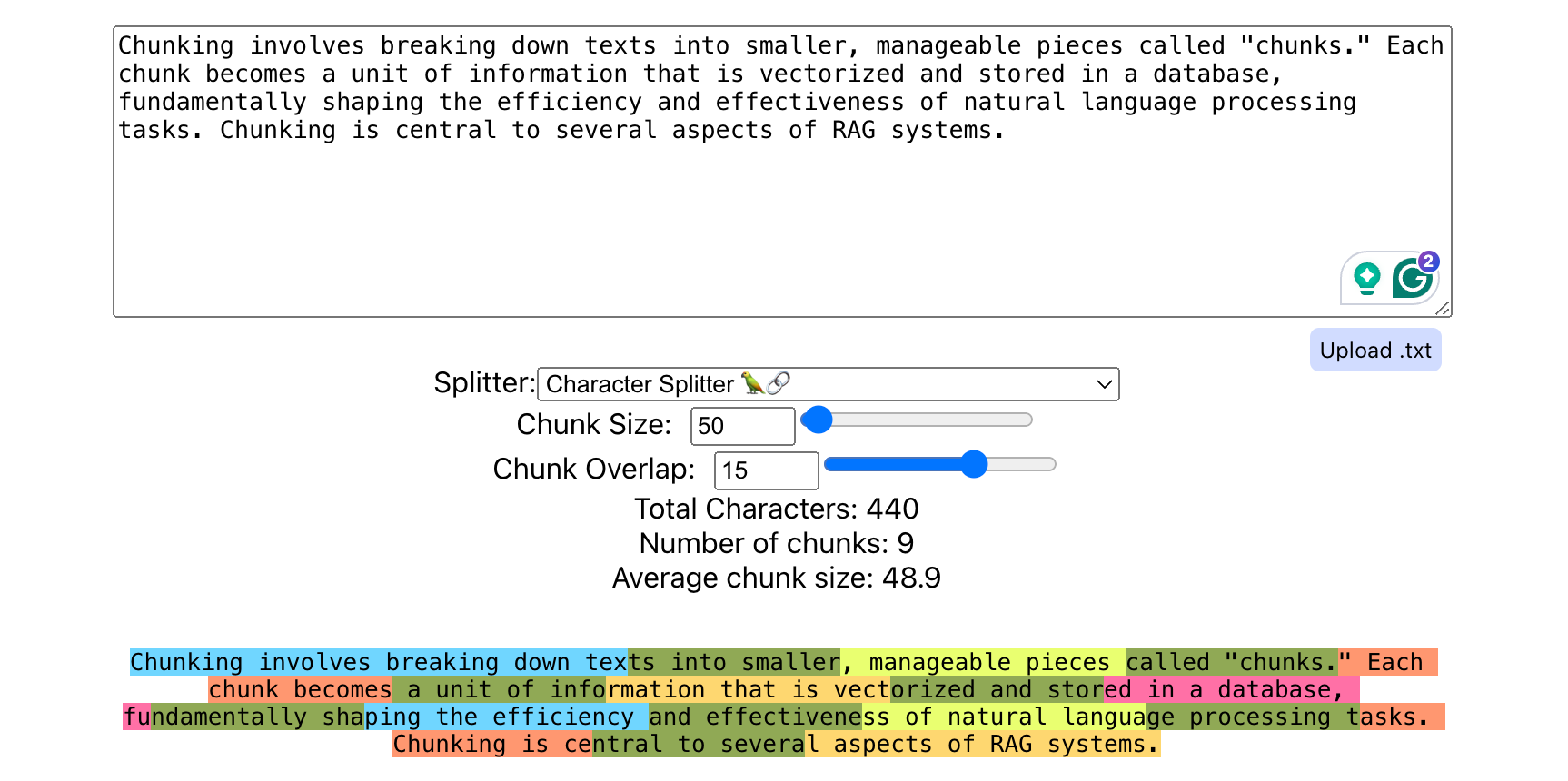
Impact of chunking
Chunking plays a central role in various aspects of RAG systems, exerting influence not only on retrieval quality but also on response. Let's understand these aspects in more detail.
Retrieval quality
The primary objective of chunking is to enhance the retrieval quality of information from vector databases. By defining the unit of information that is stored, chunking allows for retrieval of the most relevant information needed for the task.
Vector database cost
Efficient chunking techniques help optimize storage by balancing granularity. The cost of storage grows linearly with the number of chunks, therefore chunks should be as large as possible to keep costs low.
Vector database query latency
Maintaining low latency is essential for real-time applications. Minimizing the number of chunks reduces latency.
LLM latency and cost
The mind-blowing capabilities of LLMs come at a considerable price. Improved context from larger chunk sizes increases latency and serving costs.
LLM hallucinations
While adding more context may seem better, excessive context can lead to hallucinations in LLMs. Choosing the right chunking size for the job plays a large role in determining the quality of generated content. Balancing contextual richness with retrieval precision is essential to prevent hallucinatory outputs and ensure a coherent and accurate generation process.
Factors influencing chunking
We understand the importance of taking chunking seriously, but what factors influence it? A better understanding of these parameters will enable us to select an appropriate strategy.
Text structure
The text structure, whether it's a sentence, paragraph, code, table, or transcript, significantly impacts the chunk size. Understanding how structure relates to the type of content will help influence chunking strategy.
Embedding model
The capabilities and limitations of the embedding model play a crucial role in defining chunk size. Factors such as the model's context input length and its ability to maintain high-quality embeddings guide the optimal chunking strategy.
LLM context length
LLMs have finite context windows. Chunk size directly affects how much context can be fed into the LLM. Due to context length limitations, large chunks force the user to keep the top k in retrieval as low as possible.
Type of questions
The questions that users will be asking helps determine the chunking techniques best suited for your use case. Specific factual questions, for instance, may require a different chunking approach than complex questions which will require information from multiple chunks.
Types of chunking
As you see, selecting the right chunk size involves a delicate balance of multiple factors. There is no one-size-fits-all approach, emphasizing the importance of finding a chunking technique tailored to the RAG application's specific needs.
Let's delve into common chunking techniques to help AI builders optimize their RAG performance.


Text splitter
Let's first understand the base class used by all Langchain splitters. The _merge_splits method of the TextSplitter class is responsible for combining smaller pieces of text into medium-sized chunks. It takes a sequence of text splits and a separator, and then iteratively merges these splits into chunks, ensuring that the combined size of the chunks is within specified limits.
The method uses chunk_size and chunk_overlap to determine the maximum size of the resulting chunks and their allowed overlap. It also considers factors such as the length of the separator and whether to strip whitespace from the chunks.
The logic maintains a running total of the length of the chunks and the separator. As splits are added to the current chunk, the method checks if adding a new split would exceed the specified chunk size. If so, it creates a new chunk, considering the chunk overlap, and removes splits from the beginning to meet size constraints.
This process continues until all splits are processed, resulting in a list of merged chunks. The method ensures that the chunks are within the specified size limits and handles edge cases such as chunks longer than the specified size by issuing a warning.
Source: https://github.com/langchain-ai/langchain/blob/master/libs/langchain/langchain/text_splitter.py#L99
1from abc import ABC, abstractmethod
2
3class TextSplitter(BaseDocumentTransformer, ABC):
4 """Interface for splitting text into chunks."""
5
6 def __init__(
7 self,
8 chunk_size: int = 4000,
9 chunk_overlap: int = 200,
10 length_function: Callable[[str], int] = len,
11 keep_separator: bool = False,
12 add_start_index: bool = False,
13 strip_whitespace: bool = True,
14 ) -> None:
15 """Create a new TextSplitter.
16
17 Args:
18 chunk_size: Maximum size of chunks to return
19 chunk_overlap: Overlap in characters between chunks
20 length_function: Function that measures the length of given chunks
21 keep_separator: Whether to keep the separator in the chunks
22 add_start_index: If True, includes chunk's start index in metadata
23 strip_whitespace: If True, strips whitespace from the start and end of
24 every document
25 """
26 if chunk_overlap > chunk_size:
27 raise ValueError(
28 f"Got a larger chunk overlap ({chunk_overlap}) than chunk size "
29 f"({chunk_size}), should be smaller."
30 )
31 self._chunk_size = chunk_size
32 self._chunk_overlap = chunk_overlap
33 self._length_function = length_function
34 self._keep_separator = keep_separator
35 self._add_start_index = add_start_index
36 self._strip_whitespace = strip_whitespace
37
38 @abstractmethod
39 def split_text(self, text: str) -> List[str]:
40 """Split text into multiple components."""
41
42 def _join_docs(self, docs: List[str], separator: str) -> Optional[str]:
43 text = separator.join(docs)
44 if self._strip_whitespace:
45 text = text.strip()
46 if text == "":
47 return None
48 else:
49 return text
50
51 def _merge_splits(self, splits: Iterable[str], separator: str) -> List[str]:
52 # We now want to combine these smaller pieces into medium size
53 # chunks to send to the LLM.
54 separator_len = self._length_function(separator)
55
56 docs = []
57 current_doc: List[str] = []
58 total = 0
59 for d in splits:
60 _len = self._length_function(d)
61 if (
62 total + _len + (separator_len if len(current_doc) > 0 else 0)
63 > self._chunk_size
64 ):
65 if total > self._chunk_size:
66 logger.warning(
67 f"Created a chunk of size {total}, "
68 f"which is longer than the specified {self._chunk_size}"
69 )
70 if len(current_doc) > 0:
71 doc = self._join_docs(current_doc, separator)
72 if doc is not None:
73 docs.append(doc)
74 # Keep on popping if:
75 # - we have a larger chunk than in the chunk overlap
76 # - or if we still have any chunks and the length is long
77 while total > self._chunk_overlap or (
78 total + _len + (separator_len if len(current_doc) > 0 else 0)
79 > self._chunk_size
80 and total > 0
81 ):
82 total -= self._length_function(current_doc[0]) + (
83 separator_len if len(current_doc) > 1 else 0
84 )
85 current_doc = current_doc[1:]
86 current_doc.append(d)
87 total += _len + (separator_len if len(current_doc) > 1 else 0)
88 doc = self._join_docs(current_doc, separator)
89 if doc is not None:
90 docs.append(doc)
91 return docsCharacter splitter
Langchain’s CharacterTextSplitter class is responsible for breaking down a given text into smaller chunks. It uses a separator such as "\n" to identify points where the text should be split.
The method first splits the text using the specified separator and then merges the resulting splits into a list of chunks. The size of these chunks is determined by parameters like chunk_size and chunk_overlap defined in the parent class TextSplitter.
Source: https://github.com/langchain-ai/langchain/blob/master/libs/langchain/langchain/text_splitter.py#L289
1class CharacterTextSplitter(TextSplitter):
2 """Splitting text that looks at characters."""
3
4 def __init__(
5 self, separator: str = "\n\n", is_separator_regex: bool = False, **kwargs: Any
6 ) -> None:
7 """Create a new TextSplitter."""
8 super().__init__(**kwargs)
9 self._separator = separator
10 self._is_separator_regex = is_separator_regex
11
12 def split_text(self, text: str) -> List[str]:
13 """Split incoming text and return chunks."""
14 # First we naively split the large input into a bunch of smaller ones.
15 separator = (
16 self._separator if self._is_separator_regex else re.escape(self._separator)
17 )
18 splits = _split_text_with_regex(text, separator, self._keep_separator)
19 _separator = "" if self._keep_separator else self._separator
20 return self._merge_splits(splits, _separator)Let's analyze its behavior with an example text. The empty string separator “” treats each character as a splitter. Subsequently, it combines the splits according to chunk size and chunk overlap.
1text = "This is first. This is second. This is third. This is fourth. This is fifth.\n\nThis is sixth. This is seventh. This is eighth. This is ninth. This is tenth."
2
3splitter = CharacterTextSplitter(separator="", chunk_size=40, chunk_overlap=20)
4splitter.split_text(text)
5
6Output:
7['This is first. This is second. This is t',
8 'is second. This is third. This is fourth',
9 'hird. This is fourth. This is fifth.\n\nTh',
10 '. This is fifth.\n\nThis is sixth. This is',
11 'is is sixth. This is seventh. This is ei',
12 'seventh. This is eighth. This is ninth.',
13 'ghth. This is ninth. This is tenth.']Recursive Character Splitter
Langchain’s RecursiveCharacterTextSplitter class is designed to break down a given text into smaller chunks by recursively attempting to split it using different separators. This class is particularly useful when a single separator may not be sufficient to identify the desired chunks.
The method starts by trying to split the text using a list of potential separators specified in the _separators attribute. It iteratively checks each separator to find the one that works for the given text. If a separator is found, the text is split, and the process is repeated recursively on the resulting chunks until the chunks are of a manageable size.
The separators are listed in descending order of preference, and the method attempts to split the text using the most specific ones first. For example, in the context of the Python language, it tries to split along class definitions ("\nclass "), function definitions ("\ndef "), and other common patterns. If a separator is found, it proceeds to split the text recursively.
The resulting chunks are then merged and returned as a list. The size of the chunks is determined by parameters like chunk_size and chunk_overlap defined in the parent class TextSplitter. This approach allows for a more flexible and adaptive way of breaking down a text into meaningful sections.
Source: https://github.com/langchain-ai/langchain/blob/master/libs/langchain/langchain/text_splitter.py#L851
1class RecursiveCharacterTextSplitter(TextSplitter):
2 """Splitting text by recursively look at characters.
3
4 Recursively tries to split by different characters to find one
5 that works.
6 """
7
8 def __init__(
9 self,
10 separators: Optional[List[str]] = None,
11 keep_separator: bool = True,
12 is_separator_regex: bool = False,
13 **kwargs: Any,
14 ) -> None:
15 """Create a new TextSplitter."""
16 super().__init__(keep_separator=keep_separator, **kwargs)
17 self._separators = separators or ["\n\n", "\n", " ", ""]
18 self._is_separator_regex = is_separator_regex
19
20 def _split_text(self, text: str, separators: List[str]) -> List[str]:
21 """Split incoming text and return chunks."""
22 final_chunks = []
23 # Get appropriate separator to use
24 separator = separators[-1]
25 new_separators = []
26 for i, _s in enumerate(separators):
27 _separator = _s if self._is_separator_regex else re.escape(_s)
28 if _s == "":
29 separator = _s
30 break
31 if re.search(_separator, text):
32 separator = _s
33 new_separators = separators[i + 1 :]
34 break
35
36 _separator = separator if self._is_separator_regex else re.escape(separator)
37 splits = _split_text_with_regex(text, _separator, self._keep_separator)
38
39 # Now go merging things, recursively splitting longer texts.
40 _good_splits = []
41 _separator = "" if self._keep_separator else separator
42 for s in splits:
43 if self._length_function(s) < self._chunk_size:
44 _good_splits.append(s)
45 else:
46 if _good_splits:
47 merged_text = self._merge_splits(_good_splits, _separator)
48 final_chunks.extend(merged_text)
49 _good_splits = []
50 if not new_separators:
51 final_chunks.append(s)
52 else:
53 other_info = self._split_text(s, new_separators)
54 final_chunks.extend(other_info)
55 if _good_splits:
56 merged_text = self._merge_splits(_good_splits, _separator)
57 final_chunks.extend(merged_text)
58 return final_chunks
59
60 def split_text(self, text: str) -> List[str]:
61 return self._split_text(text, self._separators)
62
63 @classmethod
64 def from_language(
65 cls, language: Language, **kwargs: Any
66 ) -> RecursiveCharacterTextSplitter:
67 separators = cls.get_separators_for_language(language)
68 return cls(separators=separators, is_separator_regex=True, **kwargs)
69
70 @staticmethod
71 def get_separators_for_language(language: Language) -> List[str]:
72 if language == Language.PYTHON:
73 return [
74 # First, try to split along class definitions
75 "\nclass ",
76 "\ndef ",
77 "\n\tdef ",
78 # Now split by the normal type of lines
79 "\n\n",
80 "\n",
81 " ",
82 "",
83
In this example, the text is initially divided based on "\n\n" and subsequently on "" to adhere to the specified chunk size and overlap. The separator "\n\n" is removed from the text.
1text = "This is first. This is second. This is third. This is fourth. This is fifth.\n\nThis is sixth. This is seventh. This is eighth. This is ninth. This is tenth."
2
3splitter = RecursiveCharacterTextSplitter(separators=["\n\n", ""], chunk_size=40, chunk_overlap=20)
4splitter.split_text(text)
5
6
7Output:
8['This is first. This is second. This is t',
9 'is second. This is third. This is fourth',
10 'hird. This is fourth. This is fifth.',
11 'This is sixth. This is seventh. This i',
12 's is seventh. This is eighth. This is ni',
13 's eighth. This is ninth. This is tenth.']
You can also employ the above method to chunk code from various languages by utilizing well-defined separators specific to each language.
Sentence splitter
Character splitting poses an issue as it tends to cut sentences midway. Despite attempts to address this using chunk size and overlap, sentences can still be cut off prematurely. Let's explore a novel approach that considers sentence boundaries instead.
The SpacySentenceTokenizer takes a piece of text and divides it into smaller chunks, with each chunk containing a certain number of sentences. It uses the Spacy library to analyze the input text and identify individual sentences.
The method allows you to control the size of the chunks by specifying the stride and overlap parameters. The stride determines how many sentences are skipped between consecutive chunks, and the overlap determines how many sentences from the previous chunk are included in the next one.
1from typing import List, Optional
2from langchain_core.documents import Document
3import spacy
4
5
6class SpacySentenceTokenizer:
7 def __init__(self, spacy_model="en_core_web_sm"):
8 self.nlp = spacy.load(spacy_model)
9
10 def create_documents(
11 self, documents, metadatas=None, overlap: int = 0, stride: int = 1
12 )-> List[Document]:
13 chunks = []
14 if not metadatas:
15 metadatas = [{}] * len(documents)
16 for doc, metadata in zip(documents, metadatas):
17 text_chunks = self.split_text(doc, overlap, stride)
18 for chunk_text in text_chunks:
19 chunks.append(Document(page_content=chunk_text, metadata=metadata))
20 return chunks
21
22 def split_text(self, text: str, stride: int = 1, overlap: int = 1) -> List[str]:
23 sentences = list(self.nlp(text).sents)
24 chunks = []
25 for i in range(0, len(sentences), stride):
26 chunk_text = " ".join(str(sent) for sent in sentences[i : i + overlap + 1])
27 chunks.append(chunk_text)
28 return chunksThe example below shows how a text with pronouns like “they” requires the context of the previous sentence to make sense. Our brute force overlap approach helps here but is also redundant at some places and leads to longer chunks 🙁
1text = "I love dogs. They are amazing. Cats must be the easiest pets around. Tesla robots are advanced now with AI. They will take us to mars."
2
3tokenizer = SpacySentenceTokenizer()
4tokenizer.split_text(text, stride=1, overlap=2)
5
6Output:
7['I love dogs. They are amazing. Cats must be the easiest pets around.',
8 'They are amazing. Cats must be the easiest pets around. Tesla robots are advanced now with AI.',
9 'Cats must be the easiest pets around. Tesla robots are advanced now with AI. They will take us to mars.',
10 'Tesla robots are advanced now with AI. They will take us to mars.',
11 'They will take us to mars.']Semantic splitting
This brings us to my favorite splitting method!
The SimilarSentenceSplitter takes a piece of text and divides it into groups of sentences based on their similarity. It utilizes a similarity model to measure how similar each sentence is to its neighboring sentences. The method uses a sentence splitter to break the input text into individual sentences.
The goal is to create groups of sentences where each group contains related sentences, according to the specified similarity model. The method starts with the first sentence in the first group and then iterates through the remaining sentences. It decides whether to add a sentence to the current group based on its similarity to the previous sentence.
The group_max_sentences parameter controls the maximum number of sentences allowed in each group. If a group reaches this limit, a new group is started. Additionally, a new group is initiated if the similarity between consecutive sentences falls below a specified similarity_threshold.
In simpler terms, this method organizes a text into clusters of sentences, where sentences within each cluster are considered similar to each other. It's useful for identifying coherent and related chunks of information within a larger body of text.
Credits: https://github.com/agamm/semantic-split
1from typing import List
2
3from sentence_transformers import SentenceTransformer, util
4import spacy
5
6
7class SentenceTransformersSimilarity:
8 def __init__(self, model="all-MiniLM-L6-v2", similarity_threshold=0.2):
9 self.model = SentenceTransformer(model)
10 self.similarity_threshold = similarity_threshold
11
12 def similarities(self, sentences: List[str]):
13 # Encode all sentences
14 embeddings = self.model.encode(sentences)
15
16 # Calculate cosine similarities for neighboring sentences
17 similarities = []
18 for i in range(1, len(embeddings)):
19 sim = util.pytorch_cos_sim(embeddings[i - 1], embeddings[i]).item()
20 similarities.append(sim)
21
22 return similarities
23
24
25class SpacySentenceSplitter():
26
27 def __init__(self):
28 self.nlp = spacy.load("en_core_web_sm")
29
30 def split(self, text: str) -> List[str]:
31 doc = self.nlp(text)
32 return [str(sent).strip() for sent in doc.sents]
33
34
35class SimilarSentenceSplitter():
36
37 def __init__(self, similarity_model, sentence_splitter):
38 self.model = similarity_model
39 self.sentence_splitter = sentence_splitter
40
41 def split_text(self, text: str, group_max_sentences=5) -> List[str]:
42 """
43 group_max_sentences: The maximum number of sentences in a group.
44 """
45 sentences = self.sentence_splitter.split(text)
46
47 if len(sentences) == 0:
48 return []
49
50 similarities = self.model.similarities(sentences)
51
52 # The first sentence is always in the first group.
53 groups = [[sentences[0]]]
54
55 # Using the group min/max sentences contraints,
56 # group together the rest of the sentences.
57 for i in range(1, len(sentences)):
58 if len(groups[-1]) >= group_max_sentences:
59 groups.append([sentences[i]])
60 elif similarities[i - 1] >= self.model.similarity_threshold:
61 groups[-1].append(sentences[i])
62 else:
63 groups.append([sentences[i]])
64
65 return [" ".join(g) for g in groups]
Now, let's apply semantic chunking to the text. The model appropriately connects sentences related to the dog and robot, referred to as "they" in the sentences, factoring in previous context. This approach allows us to overcome various challenges, including setting chunk size, managing overlap, and avoiding cropping in the middle.
1text = "I love dogs. They are amazing. Cats must be the easiest pets around. Tesla robots are advanced now with AI. They will take us to mars."
2
3model = SentenceTransformersSimilarity() # emb model
4sentence_splitter = SpacySentenceSplitter() # sentence tokenizer
5splitter = SimilarSentenceSplitter(model, sentence_splitter)
6splitter.split_text(text)
7
8Output:
9['I love dogs. They are amazing.',
10 'Cats must be the easiest pets around.',
11 'Tesla robots are advanced now with AI. They will take us to mars.']This covers all the major practical text chunking methods commonly used in production. Now let’s look at one final approach to chunking for complicated documents.
LLM based chunking
These popular methods are all fine and good, but can we push them further? Let’s use the power of LLMs to go beyond traditional chunking!
Propositions
Unlike the conventional use of passages or sentences, a new paper Dense X Retrieval: What Retrieval Granularity Should We Use? introduces a novel retrieval unit for dense retrieval called "propositions." Propositions are atomic expressions within text, each encapsulating a distinct factoid and presented in a concise, self-contained natural language format.
The three principles below define propositions as atomic expressions of meanings in text:
- Each proposition should represent a distinct piece of meaning in the text, collectively embodying the semantics of the entire text.
- A proposition must be minimal and cannot be further divided into separate propositions.
- A proposition should contextualize itself and be self-contained, encompassing all the necessary context from the text (e.g., coreference) to interpret its meaning.

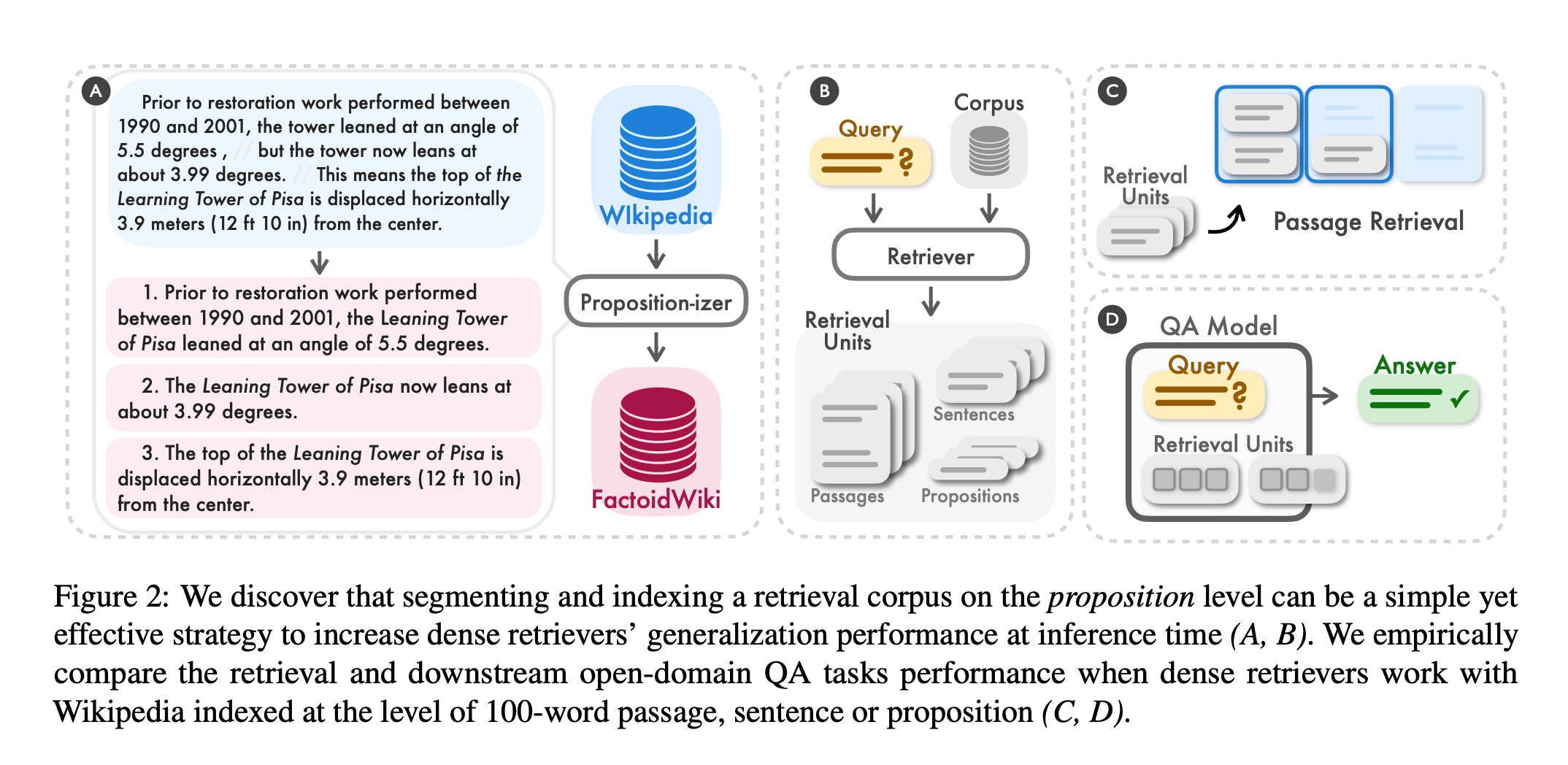
Let's put this novel approach into practice. The authors themselves trained the propositionizer model used in the code snippet below. As evident in the output, the model successfully performs coreference resolution, ensuring each sentence is self-sufficient.
1from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
2import torch
3import json
4
5model_name = "chentong00/propositionizer-wiki-flan-t5-large"
6device = "cuda" if torch.cuda.is_available() else "cpu"
7tokenizer = AutoTokenizer.from_pretrained(model_name)
8model = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(device)
9
10input_text = "I love dogs. They are amazing. Cats must be the easiest pets around. Tesla robots are advanced now with AI. They will take us to mars."
11
12input_ids = tokenizer(input_text, return_tensors="pt").input_ids
13outputs = model.generate(input_ids.to(device), max_new_tokens=512).cpu()
14
15output_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
16try:
17 prop_list = json.loads(output_text)
18except:
19 prop_list = []
20 print("[ERROR] Failed to parse output text as JSON.")
21print(json.dumps(prop_list, indent=2))
22
23Output:
24I love dogs. Dogs are amazing. Cats are the easiest pets around. Tesla robots are advanced now with AI. Tesla robots will take us to mars.Multi-vector indexing
Another approach involves multi-vector indexing, where semantic search is performed for a vector derived from something other than the raw text. There are various methods to create multiple vectors per document.
Smaller chunks
Divide a document into smaller chunks and embed them (referred to as ParentDocumentRetriever).
Summary
Generate a summary for each document and embed it along with, or instead of, the document.
Hypothetical questions
Form hypothetical questions that each document would be appropriate to answer, and embed them along with, or instead of, the document.
Each of these utilizes either a text2text or an LLM with a prompt to obtain the necessary chunk. The system then indexes both the newly generated chunk and the original text, improving the recall of the retrieval system. You can find more details of these techniques in Langchain’s official documentation.
Document specific splitting
Is parsing documents really chunking? Despite my hesitation, let’s cover this related topic.
Remember the buzz around "Chat with PDF"? Things are easy with plain text, but once we introduce tables, images, and unconventional formatting things get a lot more complicated. And what about .doc, .epub, and .xml formats as well? This leads us to a very powerful library…
Unstructured, with its diverse set of document type support and flexible partitioning strategies, offers several benefits for reading documents efficiently.
Supports all major document types
Unstructured supports a wide range of document types, including .pdf, .docx, .doc, .odt, .pptx, .ppt, .xlsx, .csv, .tsv, .eml, .msg, .rtf, .epub, .html, .xml, .png, .jpg, and .txt files. This ensures that users can seamlessly work with different file formats within a unified framework.
Adaptive partitioning
The "auto" strategy in Unstructured provides an adaptive approach to partitioning. It automatically selects the most suitable partitioning strategy based on the characteristics of the document. This feature simplifies the user experience and optimizes the processing of documents without the need for manual intervention in selecting partitioning strategies.
Specialized strategies for varied use cases
Unstructured provides specific strategies for different needs. The "fast" strategy quickly extracts information using traditional NLP techniques, "hi_res" ensures precise classification using detectron2 and document layout, and "ocr_only" is designed specifically for Optical Character Recognition in image-based files. These strategies accommodate various use cases, offering users flexibility and precision in their document processing workflows.
Unstructured's comprehensive document type support, adaptive partitioning strategies, and customization options make it a powerful tool for efficiently reading and processing a diverse range of documents.
Let's run an example and see how it partitions the Gemini 1.5 technical report.
1elements = partition_pdf(
2 filename=filename,
3
4 # Unstructured Helpers
5 strategy="hi_res",
6 infer_table_structure=True,
7 model_name="yolox"
8)
9
10Output:
11[<unstructured.documents.elements.Image at 0x2acfc24d0>,
12 <unstructured.documents.elements.Title at 0x2d4562c50>,
13 <unstructured.documents.elements.NarrativeText at 0x2d4563b50>,
14 <unstructured.documents.elements.NarrativeText at 0x2d4563350>,
15 <unstructured.documents.elements.Title at 0x2d4560b90>,
16 <unstructured.documents.elements.NarrativeText at 0x2d4562350>,
17 <unstructured.documents.elements.NarrativeText at 0x2d4561b10>,
18 <unstructured.documents.elements.NarrativeText at 0x2d4562410>,
19 <unstructured.documents.elements.NarrativeText at 0x2d45620d0>,
20 <unstructured.documents.elements.Header at 0x2d4562110>,
21 <unstructured.documents.elements.NarrativeText at 0x2d4560a50>,
22 <unstructured.documents.elements.Title at 0x2a58e3090>,
23 <unstructured.documents.elements.Image at 0x2d4563d90>,
24 <unstructured.documents.elements.FigureCaption at 0x2d4563c90>,
25 <unstructured.documents.elements.NarrativeText at 0x2d4563150>,
26 <unstructured.documents.elements.NarrativeText at 0x2d4562290>,
27 <unstructured.documents.elements.Footer at 0x2d4563e90>,
28 <unstructured.documents.elements.Header at 0x2d4562790>,
29 <unstructured.documents.elements.Table at 0x2d4561ed0>,
30 <unstructured.documents.elements.Title at 0x2a7efea10>,
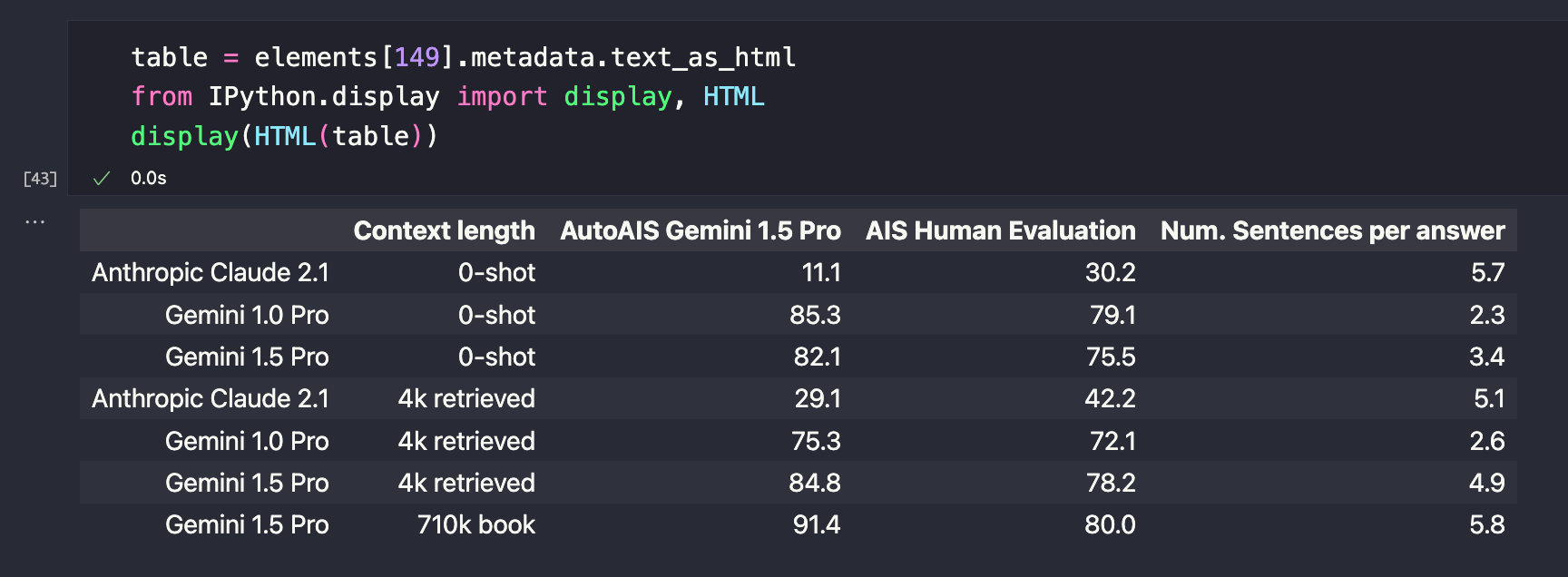
31......It effectively extracted various sections from the PDF and organized them into distinct elements. Now, let's examine the data to confirm if we successfully parsed the table below.

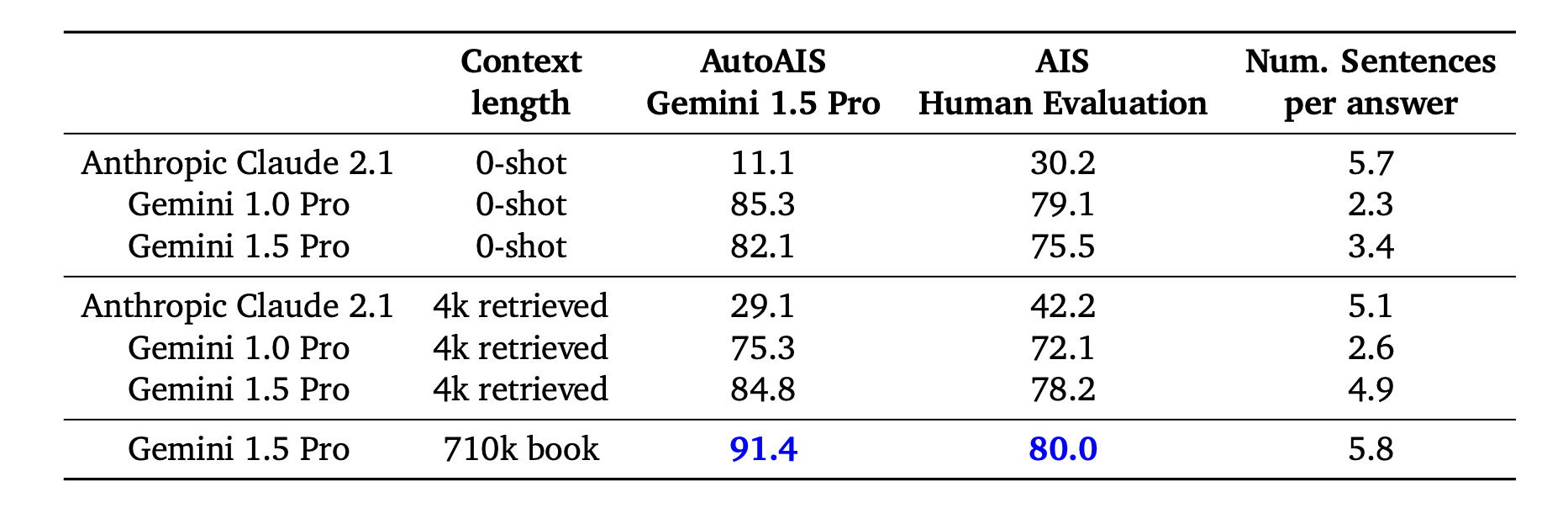
Look how similar the two tables are! It is able to identify the columns & rows to generate the table in HTML format. This makes it easier for us to do tabular QnA!

How to measure chunking effectiveness


To optimize RAG performance, improving retrieval with effective chunking is crucial. Here are two chunk evaluation metrics to help you debug RAG faster.
Chunk Attribution
Chunk attribution evaluates whether each retrieved chunk influences the model's response. It employs a binary metric, categorizing each chunk as either Attributed or Not Attributed. Chunk Attribution is closely linked to Chunk Utilization (see below), with Attribution determining if a chunk impacted the response and Utilization measuring the extent of the chunk's text involved in the effect. Only Attributed chunks can have Utilization scores greater than zero.
Chunk Attribution helps pinpoint areas for improvement in RAG systems, such as adjusting the number of retrieved chunks. If the system provides satisfactory responses but has many Not Attributed chunks, reducing the retrieved chunks per example may enhance system efficiency, leading to lower costs and latency.
Additionally, when investigating individual examples with unusual or unsatisfactory model behavior, Attribution helps identify the specific chunks influencing the response, facilitating quicker troubleshooting.
Chunk Utilization
Chunk Utilization gauges the fraction of text in each retrieved chunk that impacts the model's response. This metric ranges from 0 to 1, where a value of 1 indicates the entire chunk affected the response, while a lower value, such as 0.5, signifies the presence of "extraneous" text that did not impact the response. Chunk Utilization is intricately connected to Chunk Attribution, as Attribution determines if a chunk affected the response, while Utilization measures the portion of the chunk text involved in the effect. Only Attributed chunks can have Utilization scores greater than zero.
Low Chunk Utilization scores suggest that chunks may be longer than necessary. In such cases, reducing the parameters that control the chunk size is recommended to enhance system efficiency by lowering costs and latency.
Experiment
Learn more about how to utilize metrics in our latest talk, where we build a Q&A over earning call transcripts using Langchain. If you are looking for an end2end example with code, have a look at this blog.
Conclusion
In summary, effective chunking is crucial for optimizing RAG systems. It ensures accurate information retrieval and influences factors like response latency and storage costs. Choosing the right chunking strategy involves considering multiple aspects but can be done easily with metrics like Chunk Attribution and Chunk Utilization.
Galileo's RAG analytics offer a transformative approach, providing unparalleled visibility into RAG systems and simplifying evaluation to improve RAG performance. Try GenAI Studio for yourself today!
Subscribe to Newsletter
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
