All New: Evaluations for RAG & Chain applications
🔭 Improving Your ML Datasets, Part 2: NER





In our first post, we dug into 20 Newsgroups, a standard dataset for text classification. We uncovered numerous errors and garbage samples, cleaned about 6.5% of the dataset, and improved validation by 7.24 point F1-score.
In this blog, we look at a new task: Named Entity Recognition, or NER. If you are new to NER, check out our primer. NER is a more challenging problem than text classification because the model needs to optimize for a two-part objective – predicting span boundaries as well as span labels. Furthermore, every sample can have multiple spans, each having different labels. So, an underperforming class cannot simply be remedied by collecting more samples. Instead, one must be more deliberate in their data modifications, making NER system improvement a non-linear effort.
For these reasons, we are excited to demonstrate how we can improve an NER system using a data-centric approach with Galileo. By changing only about 4% of the spans, we are able to uncover a 3.3 point F1-score improvement on test data.
As always, these cleaned datasets will be made publically available here.
Model and Data
Here we use a BERT “bert-base-cased” token classification model from HuggingFace with a linear top layer for classification of each token. We train for 5 epochs with a batch size of 32, and pick the “best” model based on the test loss. We use the HuggingFace recommended hyperparameters and tokenizer, and do not focus on any hyperparameter tuning.
For this experiment, we use the MIT Movies dataset. This is a reasonably sized dataset, with 9,500 sentences, 22k spans in the training split, and 2,500 sentences, 5.67k spans in the test split. It is a popular academic dataset, and is widely used to benchmark NLP systems [1, 2].
This dataset has 12 classes, with a few semantically overlapping such as Actor/Director and Rating/Rating Average. These overlapping classes make it particularly challenging for the model to learn robust decision boundaries, and hence creates an exciting opportunity to uncover both - dataset inconsistencies from human annotations and model inconsistencies in predictions.
Insights
1. Surfacing annotation errors with high DEP spans
The first immediate insight we uncover when looking at the dataframe view is that the spans with the highest DEP scores are very clearly mislabeled. Many have incorrect span boundaries, incorrect tags assigned, and many are simply not tagged at all, resulting in the model hallucinating spans, albeit correctly.


We filter the spans based on a pre-selected high DEP score threshold of 0.90, leaving 3% of the spans. We send this data out for relabeling, wherein 200 spans are corrected.
2. Poor span boundary labeling
Next, we look at the most frequent high DEP words (surfaced through Galileo insights), and see that “movie” is one of the most frequent words across all high DEP spans. Since we are working with the MIT Movies dataset, it is particularly surprising to see the word “movie” being so frequently challenging for the model. We click on “movie”, which filters for spans that contain this word and see that Genre is the majority class.

![[L] movie as a frequent high DEP word , [R] Genre has the highest class distribution when looking at movie spans](https://cdn.sanity.io/images/tf66morw/production/40f911c4e8bd4c31838f07b149e71226da4a9f5c-1134x242.png?w=1134&h=242&auto=format)
Clicking on Genre further filters the dataset for a subset of those spans that are classified as Genre. This represents 0.11% of the Genre spans. To confirm that the word “movie” indeed shouldn’t be included in Genre spans, we use Galileo to quickly search for Genre spans where the word “movie” is present in the sample but not the span. This search returns 8.3% of the spans and 18.8% of the training data.
That is to say, the majority of Genre spans do not contain the word “movie” in the span boundary, and we can now confirm that the span boundaries for 0.11% of Genre spans are improperly annotated as they include the term “movie” when it shouldn’t. We clean these 25 faulty spans.

![[L] Genre spans with “movie” in span boundary, [R] Genre spans without “movie” in span boundary](https://cdn.sanity.io/images/tf66morw/production/7ddc1085db184401f011b1c1cd9273d8bbbff691-1006x502.png?w=1006&h=502&auto=format)
3. High DEP labeling errors
Galileo provides 4 different error counts per sample, enabling one to sort by different span errors. Intuiting that Director and Actor can be confused easily, we look at Top Misclassified Pairs to validate this assumption.
Seeing high Director/Actor span confusion, we apply a filter for these samples, and sort by Wrong Tag errors. We see the model predicting Actor tags while the span is labeled as Director. These are infact clear annotation errors, which can have particularly high negative impact on the model due to semantic overlap between classes. The model score will also be penalized for predicting Actor tags, albeit correctly. We quickly bulk-relabel 30 spans using the Galileo bulk-edit functionality.

![[L] Director to Actor is one of the most frequent misclassifications, [R] Actor is often mislabeled as Director, surfaced by high DEP scores](https://cdn.sanity.io/images/tf66morw/production/2f980cfd35b1bfb53ba198ae68685a5c1b8d4693-1166x322.png?w=1166&h=322&auto=format)
4. High DEP classes uncover high ROI errors
Looking at insights from Galileo, we see that the Review class has both the highest DEP score and lowest class distribution.

![[L] Review class has the highest overall DEP, [R]Review class has the fewest examples](https://cdn.sanity.io/images/tf66morw/production/122c2c815203c3e17a1dcdf40e3486992ec68df1-1148x320.png?w=1148&h=320&auto=format)
Filtering our data by only Review spans, we see that 7% of these spans are being confused as Ratings_Average. We further filter by the prediction being Ratings_Average and see that the samples were in fact incorrectly labeled.

![[L] Review samples are being misclassified as Ratings_Average [R] The model is correctly predicting Ratings_Average while the annotator mislabeled spans as Review](https://cdn.sanity.io/images/tf66morw/production/75c2fd1771d3dfc363116c3727f3c0e0f0a578f6-1146x206.png?w=1146&h=206&auto=format)
Looking deeper at the Review class, we see that there are no easy (low DEP) samples for this cohort, and of the 218 Review spans, 142 are misclassified. Additionally, the semantic overlap between Review and Ratings_Average is quite high, evident from the embeddings. We quickly relabel the 20 mislabeled Review spans to Ratings_Average.

5. High DEP classes uncover high ROI errors
Taking another look at the Actor class, we see a relatively high number of span shift errors, and a large number of outliers in the embedding space.


Filtering by Actor, we see the word “and” appear as the most frequent word in hard spans. Further filtering by spans with the word “and”, we see a number of spans (2.3% of this cohort) have two actors joined by word “and”, and are labeled as a single Actor span. Note that even though the model predicted these spans correctly, DEP still surfaced this issue.
These samples, although relatively small in number, are particularly high ROI. Including the term “and” in the span label teaches the model that two distinct actors should be treated as one, so the model begins associating “and” with Actor. With very few samples containing two actors, mislabelling these has a disproportionate effect on model generalization.

![[R] 'and' is the most frequent word in high DEP spans, [R] Annotators are labeling two actors with an 'and' between them as a single actor](https://cdn.sanity.io/images/tf66morw/production/54a573a7f321d6501f058b8395cc705abbdf8f95-1150x248.png?w=1150&h=248&auto=format)
6. Bonus errors discovered but not fixed
We are able to uncover a few additional insights rapidly using some of Galileo’s built-in features.
Sorting hard samples by Total Errors shows the overall samples that were most challenging for the model


However, sorting by Missed Spans shows the most challenging spans because these are spans that have been labeled but entirely missed by the model, no prediction made.


Lastly, sorting by Ghost Spans surfaces spans that were skipped by annotators but caught by the model. These are high ROI corrections because the model is being penalized for correctly finding spans.


Results
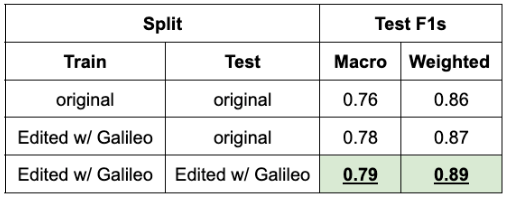
In total, 789 training spans and 320 test spans were fixed. By changing ~4% of the span data, we see up to 3.3 point F1-score improvement. Even without any modifications to the test split, we realize 2 point F1-score improvement on test data by improving only the training data. As revealed in our first blog, these data errors permeate the test set as well. Therefore, to properly realize improvement in model generalization, we also make similar corrections in the test split. This gives a further 1.3 point F1-score improvement.
Note that no changes to the model, data splits, or hyper parameters were made. The entirety of the realized performance gains come from changing high ROI spans.
We believe Galileo's workflow has the potential to save model iterations, GPU costs, and training time, as well as improve model performance in production.

If working on such cutting-edge data centric ML excites you, we are hiring for various positions including ML engineers.
Conclusion
In this short experiment, by changing only about 4% of the spans, we are able to uncover a 3.3 point F1-score improvement on test data very quickly.
We call this practice of inspecting, analyzing and fixing crucial data blindspots - ML Data Intelligence. This quick experiment (which surfaced many nuanced issues in a highly peer-reviewed dataset) underlines the importance of this practice. Galileo short-circuits this process and solves for these necessary steps in the ML lifecycle.
If you have thoughts, feedback or ideas for other datasets we can tackle, please join our Slack Community and let us know. If you want to use Galileo within your team, we would love to chat!
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
