Introducing Galileo Protect: Real-Time Hallucination Firewall 🛡️
Is Llama 3 better than GPT4?




Meta's triumphant return to the forefront of AI innovation with the release of Llama 3 has ignited fervent discussions within the AI community. As open-source models like Llama 3 continue to evolve and demonstrate impressive performance, anticipation grows regarding their ability to challenge and potentially surpass top proprietary models like GPT-4, offering the possibility of democratizing AI and eliminating vendor lock-in.
But when will open-source models dethrone the propriety kings? From social media platforms to expert forums, AI builders are meticulously analyzing every detail of Llama 3, seeking clues about its potential to redefine the landscape of AI. The buzz of excitement and speculation underscores the significance of Llama 3's release and its implications for the future trajectory of artificial intelligence.

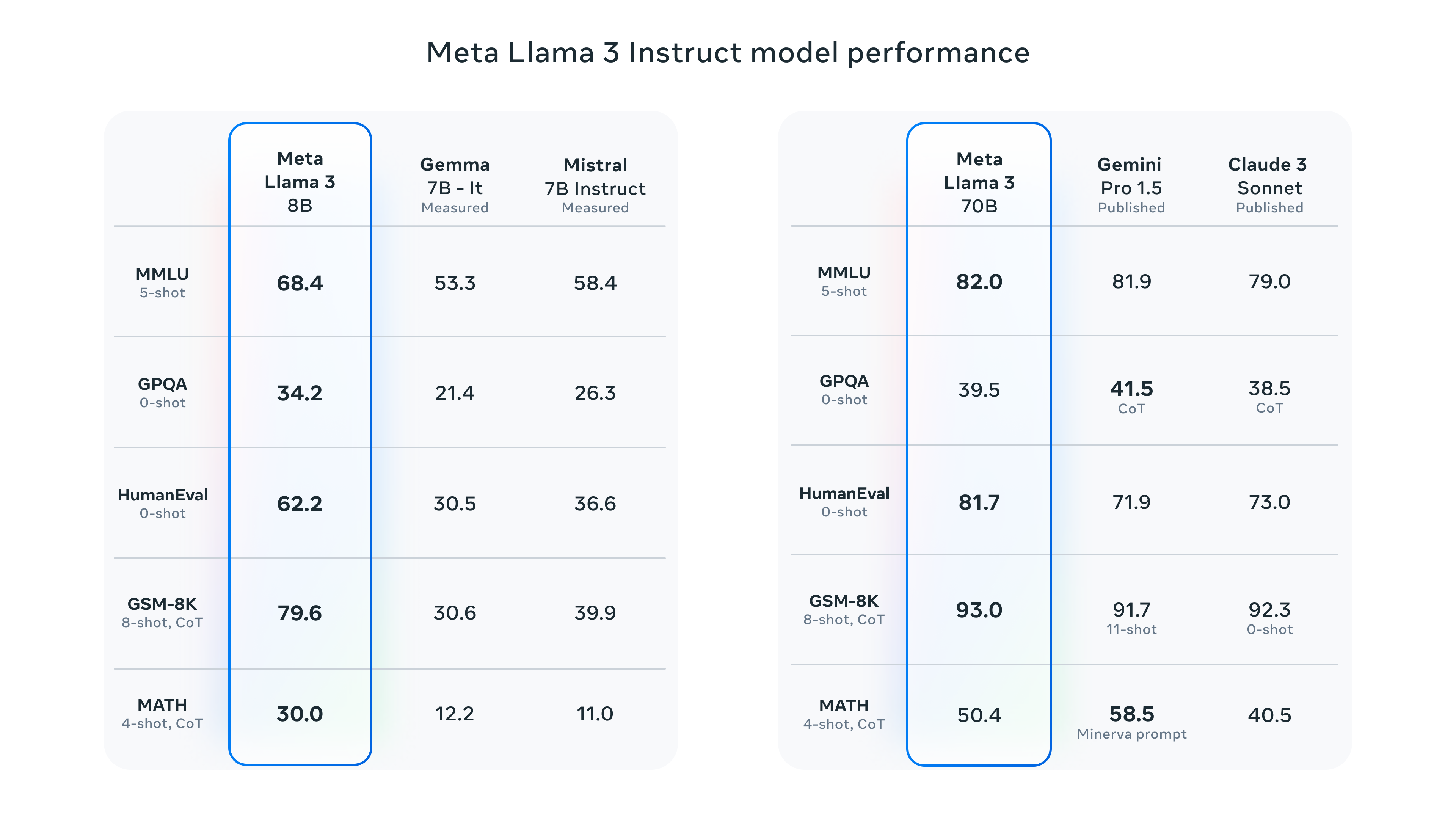
Llama 3 technical specs
Models:
- Pretrained and instruction-fine-tuned language models with 8B and 70B parameters.
Data Scaling and Quality Improvement:
- Trained on a massive dataset of 15 trillion tokens, seven times larger than Llama 2.
- Enhanced data quality through new filtering methods, including heuristic, NSFW, and semantic deduplication filters, along with text classifiers.
- Utilized Llama 2 to generate synthetic training data for text-quality classifiers.
Technical Enhancements:
- Implemented attention-mask to prevent self-attention from crossing documents.
- Increased input sequence length from 4096 to 8192 tokens.
- Introduced a new tokenizer with a 128k vocabulary, reducing token requirements by 15% compared to Llama 2 and enhancing multilingual capabilities.
- Employed grouped query attention (GQA) for all model sizes.
Training Approach:
- Leveraged a combination of supervised fine-tuning (SFT), rejection sampling (RS), proximal policy optimization (PPO), and direct policy optimization (DPO) for training.
- Trained on a diverse dataset, including public datasets and over 10 million human-annotated examples, focusing on high-quality prompts and preference rankings.
Performance and Evaluation:
- Achieved remarkable performance, with the 70B version being the best open large language model on the MMLU task, scoring over 80.
- Demonstrated log-linear performance improvement even after processing 15T tokens.
- Underwent extensive human evaluation with 1,800 prompts across 12 different topics, yielding positive results.
- Llama-3-70b-instruct sits at 5th position of LMSYS leaderboard.

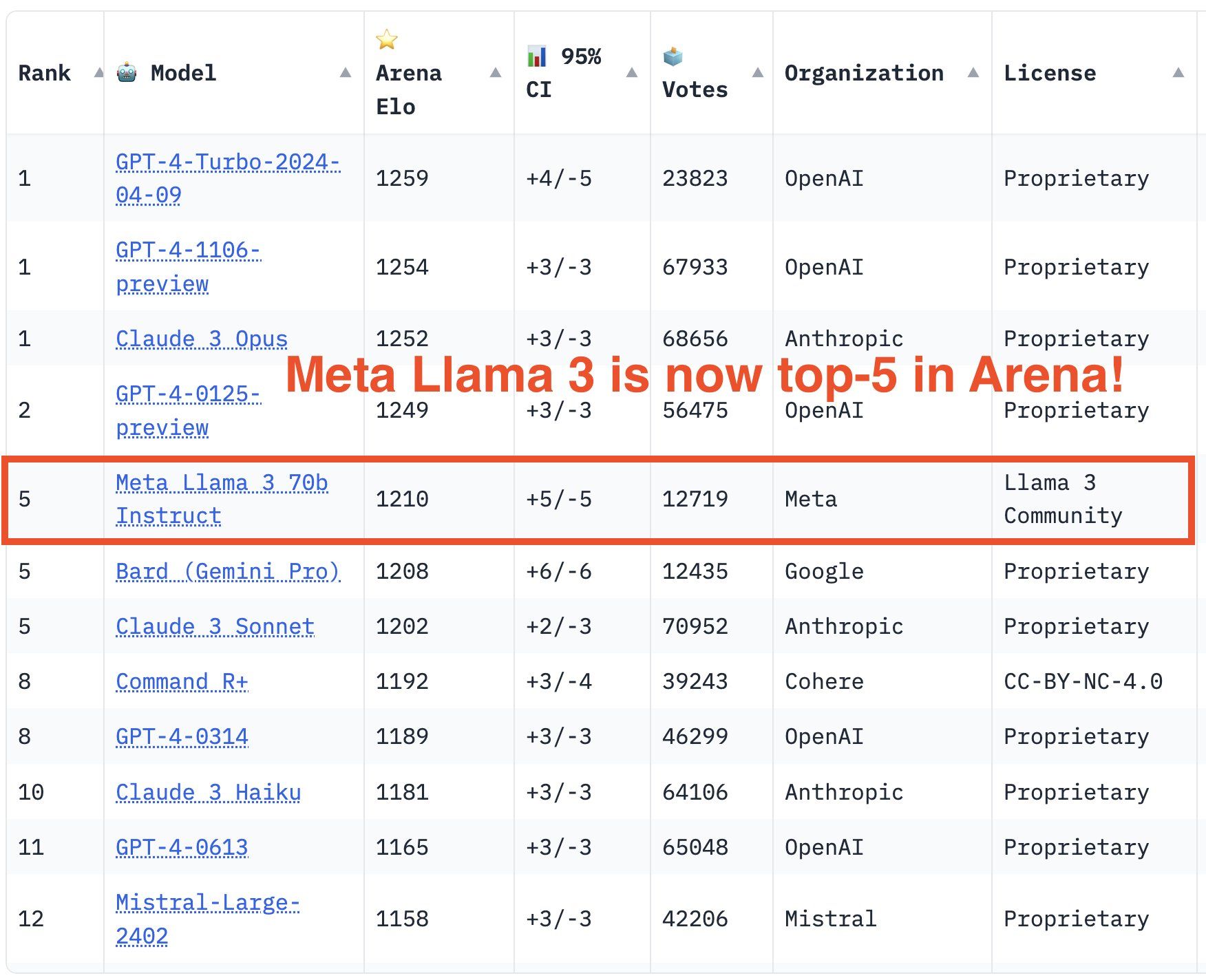
What experts are saying about Llama 3
Andrej Karpathy, previously Director of AI at Tesla and one of the founding members of OpenAI, extended his congratulations to Meta for releasing Llama 3 and shares some key insights.
- He noted that tokenizer’s token count quadrupled from Llama 2 to Llama 3, allowing for better sequence compression and downstream performance improvements.
- While the architecture maintains similarity to Llama 2, the implementation of Grouped Query Attention across all models enhances inference efficiency.
- The maximum sequence length increased to 8k in Llama 3, but it was relatively modest compared to other models like GPT-4.
- Andrej commends the unprecedented scale of data training for a model of Llama 3's size, which he sees as a positive trend towards long-trained, smaller models.
- Llama 3 was trained with 16K GPUs at an observed throughput of 400 TFLOPS, showcasing solid engineering efforts.
Bindu Reddy, an AI influencer, shared her views on why Llama-3 might be doing well on LMSYS leaderboard.
- Impact of training cut-off: The training cut-off date significantly affects the results. Llama-3, having a recent training cut-off of 12/23, seems to benefit from this, suggesting that newer training data positively impacts its performance.
- Uncensored nature: Llama-3 is described as "a lot more uncensored," implying that it generates responses with fewer restrictions or filters. Users seem to appreciate this characteristic, possibly contributing to its popularity.
- Ranking Compared to Other Models: When excluding refusals, Llama-3 falls below Claude in the ranking.
Maxime Labonne highlighted the diminishing gap between closed-source and open-source language models, noting a significant reduction in the timeframe for this convergence, which now takes only 6 to 10 months. He acknowledged the open-source community's reliance on major companies for pre-trained models but emphasizes their increasing skill in maximizing model performance.

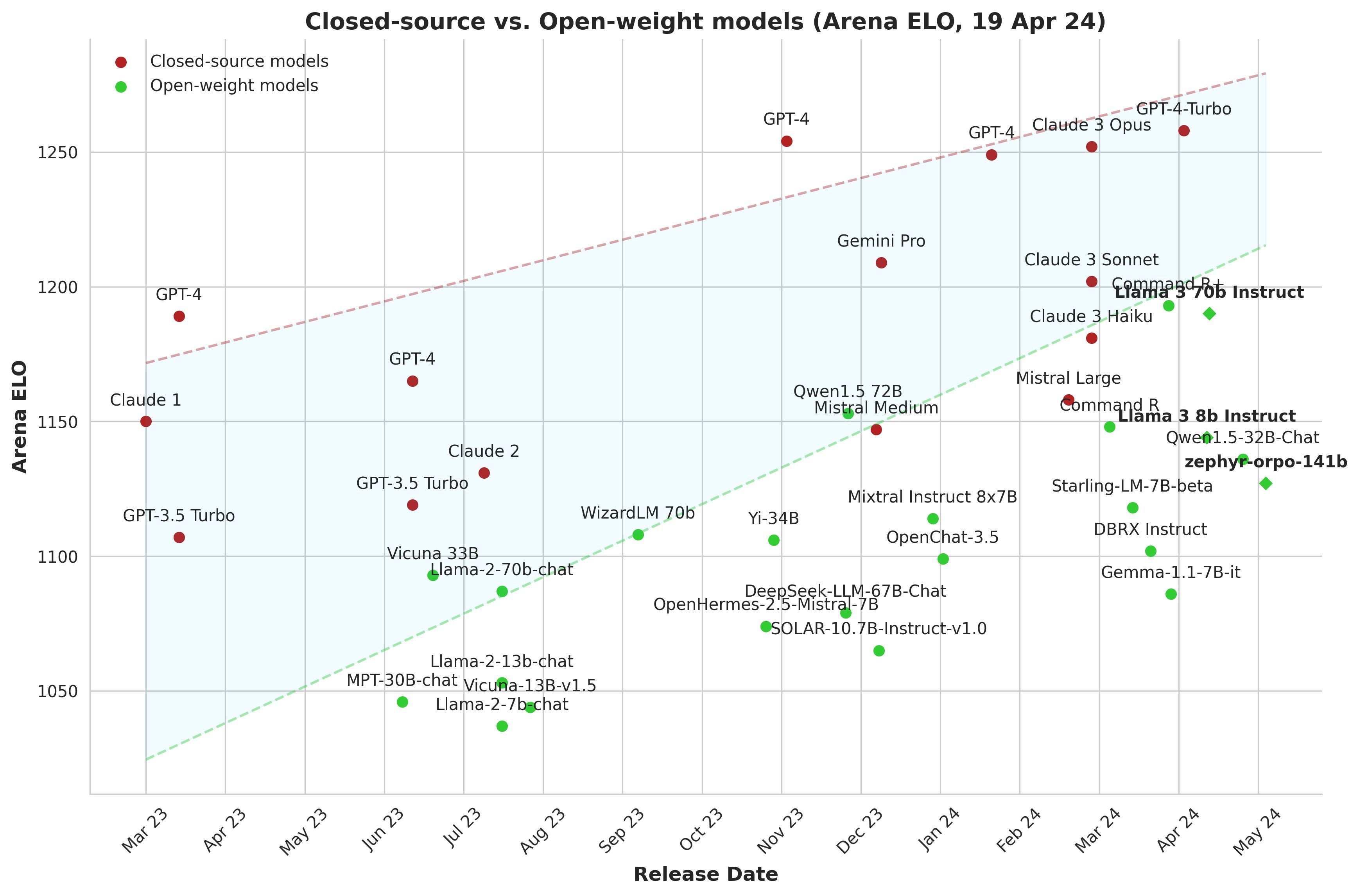
Impact of Llama 3 on the LLM industry
Meta's decision to open-source Llama 3 marks a paradigm shift in AI research and development. By embracing an open-source ethos, Meta not only fosters community-driven innovation but also strategically positions itself for long-term growth. Llama 3's arrival injects a surge of innovation and competition into the LLM industry, igniting a race for supremacy among AI giants. With its unparalleled performance, Llama 3 sets a new benchmark for excellence, compelling competitors to up their game.
Will Llama 3 beat GPT4-turbo?
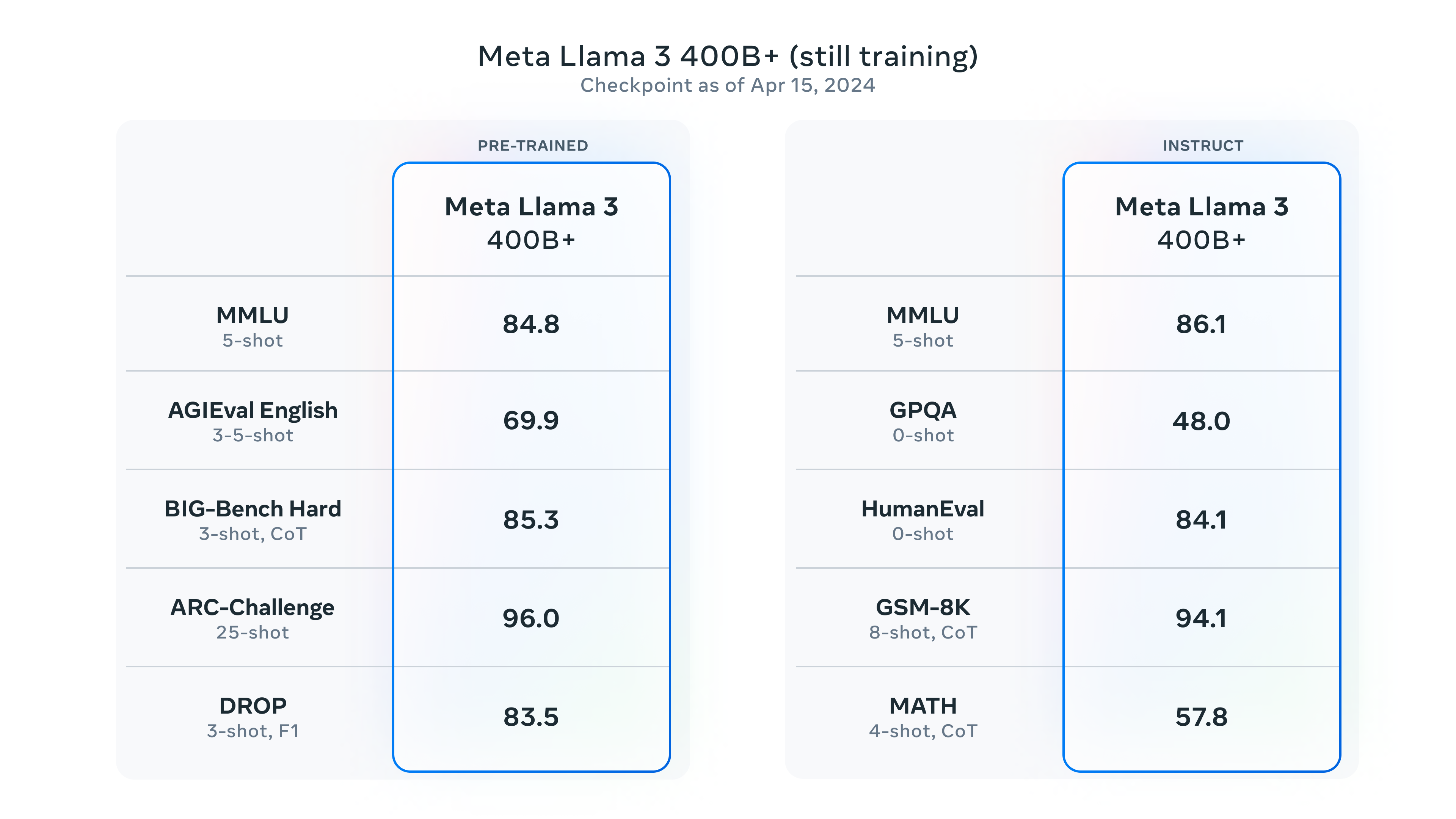
Llama 3 is gearing up for a significant leap with its upcoming release of models, particularly the colossal 400B-parameter models currently in training. Although these models are still undergoing refinement, the team is optimistic about their trajectory.
Models currently in the pipeline have enhanced capabilities, such as multimodality, multilingual conversation abilities, expanded context windows, and overall stronger performance. These advancements are poised to push the boundaries of what Llama 3 can achieve.
Although specifics about the 400B models remain under wraps, early insights suggest promising progress. As training continues, these models are expected to potentially surpass the benchmarks set by current state-of-the-art models like GPT-4.
With Llama 3's commitment to pushing the boundaries of AI capabilities, the anticipation surrounding the release of these mammoth models continues to grow, hinting at exciting possibilities in the AI landscape.
Hallucination Index 2.0
Since the debut of our Hallucination Index in November, numerous models have emerged in both private and public spheres. In our previous assessment, Llama-2-70b demonstrated strong performance in long-form text generation but fell short in QA with RAG. We're excited to evaluate how Llama 3 stacks up against GPT-4 in our next index update coming soon. Additionally, we're assessing leading models such as Claude 3, Gemini, and Command R+ on long-context RAG. We aim to test models with improved methodologies to bring the right insights to you!
Download the current Hallucination Index report below and get early access to our upcoming updates...
Subscribe to Newsletter
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
