HP + Galileo Partner to Accelerate Trustworthy AI
Mastering RAG: Choosing the Perfect Vector Database




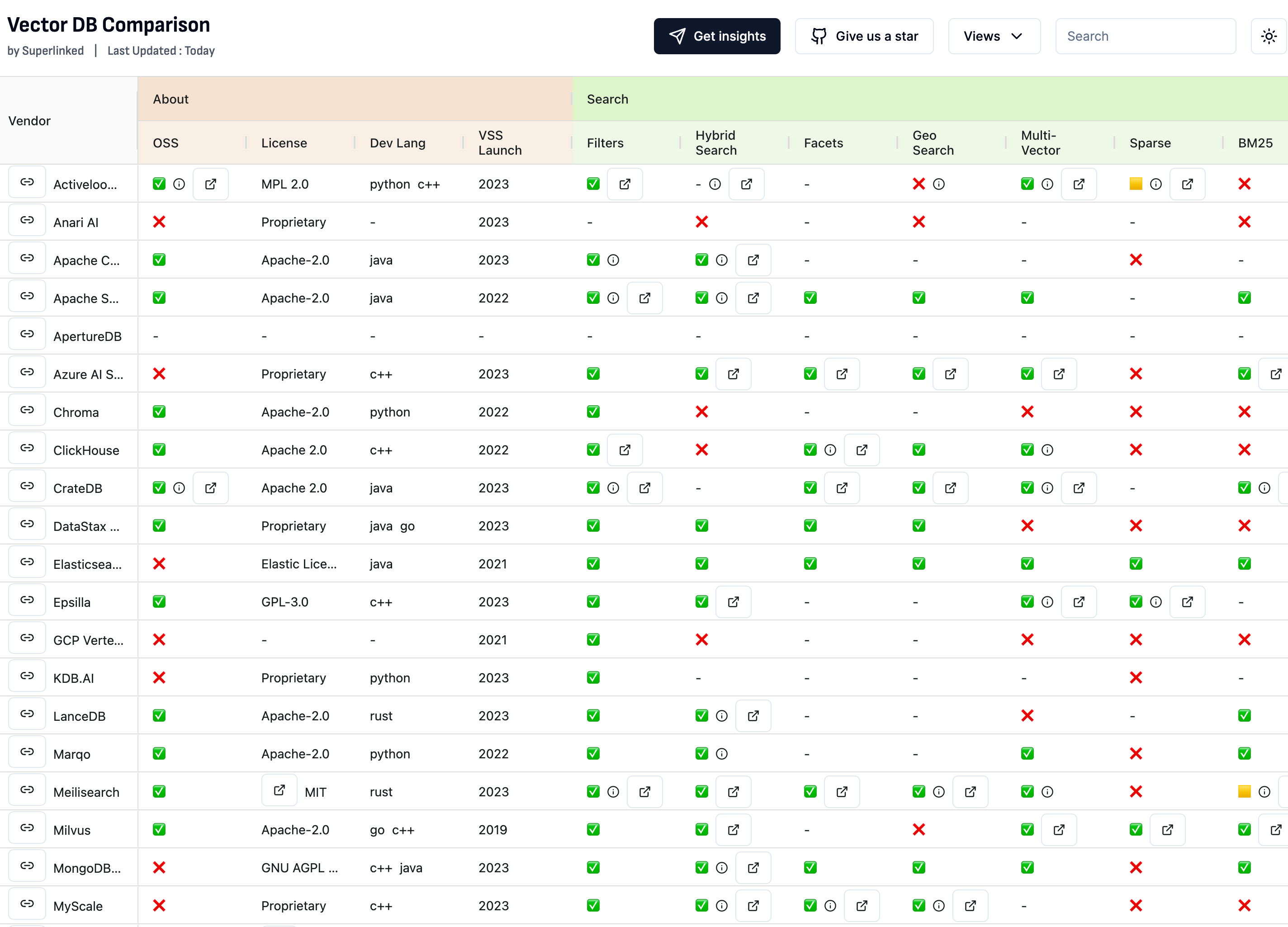
The vector database you choose for your RAG system will have a major impact on your RAG performance. Vector databases have emerged as a powerful solution for efficiently storing, indexing, and searching through unstructured data. However, with a plethora of options available, selecting the right vector database for your needs can be a daunting task. In this guide, we'll delve into the key technical criteria to consider when evaluating vector databases, helping you master the selection process with ease!
What is a Vector Database?

A vector database is a specialized database management system designed to store, index, and query high-dimensional vectors efficiently. Unlike traditional relational databases that primarily handle structured data, vector databases are optimized for managing unstructured and semi-structured data, such as images, text, audio represented as numerical vectors in a high-dimensional space. These vectors capture the inherent structure and relationships within the data, enabling sophisticated similarity search, recommendation, and data analysis tasks.
Key Factors
Before we go into database features, here are some high-level key factors to consider in your decision.

OSS or Private
Open-Source (OSS)
Open-source vector databases provide transparency, flexibility, and community-driven development. They often have active communities contributing to their improvement and may be more cost-effective for organizations with limited budgets. Examples include Milvus, Annoy, and Faiss.
Private
Proprietary vector databases offer additional features, dedicated support, and may be better suited for organizations with specific requirements or compliance needs. Examples include Elasticsearch, DynamoDB, and Azure Cognitive Search.
Language Support
Ensure that the vector database supports the programming languages commonly used within your organization. Look for comprehensive client libraries and SDKs for languages such as Python, Java, JavaScript, Go, and C++. Language support facilitates seamless integration with existing applications and development frameworks.
License
Evaluate the vector database's licensing model to ensure compatibility with your organization's policies and objectives. Common licenses include Apache License 2.0, GNU General Public License (GPL), and commercial proprietary licenses. Understand any restrictions, obligations, or usage limitations imposed by the license.
Maturity
Assess the vector database's maturity in terms of development, adoption, and community support. Look for databases with a proven track record of stability, reliability, and scalability. Consider factors such as release frequency, community activity, and longevity in the market.
Enterprise Features
Let’s explore key enterprise features that organizations should consider when evaluating vector databases for their complex data management needs.
Regulatory Compliance
Many organizations require vector databases to comply with industry standards and regulations such as SOC-2 certification, ensuring that data management practices meet stringent security and privacy requirements.
SSO
Single Sign-On (SSO) integration allows users to access the vector database using their existing authentication credentials from other systems, such as Google, Microsoft, or LDAP. SSO streamlines user access management, enhances security, and improves user experience by eliminating the need for multiple logins.
Rate Limits
Rate limits are thresholds or constraints imposed on the rate of incoming requests or operations within a specified timeframe. By setting predefined limits on the number of queries, inserts, updates, or other operations, organizations can prevent system overload, prioritize critical tasks, and maintain optimal performance.
Multi-tenancy
Multi-tenant support enables efficient resource sharing and isolation for multiple users or clients within a single database instance, including user authentication, access control, and resource allocation policies. Multi-tenancy enhances scalability and resource utilization in multi-user environments.
Role-based Control
Role-based control mechanisms enable administrators to define access privileges and permissions based on user roles and responsibilities. This ensures that only authorized personnel can access, modify, or delete sensitive data within the vector database. Role-based access control (RBAC) enhances security, mitigates risks, and facilitates compliance with regulatory mandates such as GDPR and HIPAA.
Product Features
There are many critical product features to consider when evaluating vector databases.
Exact Search Indices
Exact search indices like Flat are data structures optimized for precise retrieval of vectors based on exact similarity measures, such as Euclidean distance or cosine similarity. These indices enable fast and accurate identification of vectors that exactly match a query vector or meet specified similarity thresholds.
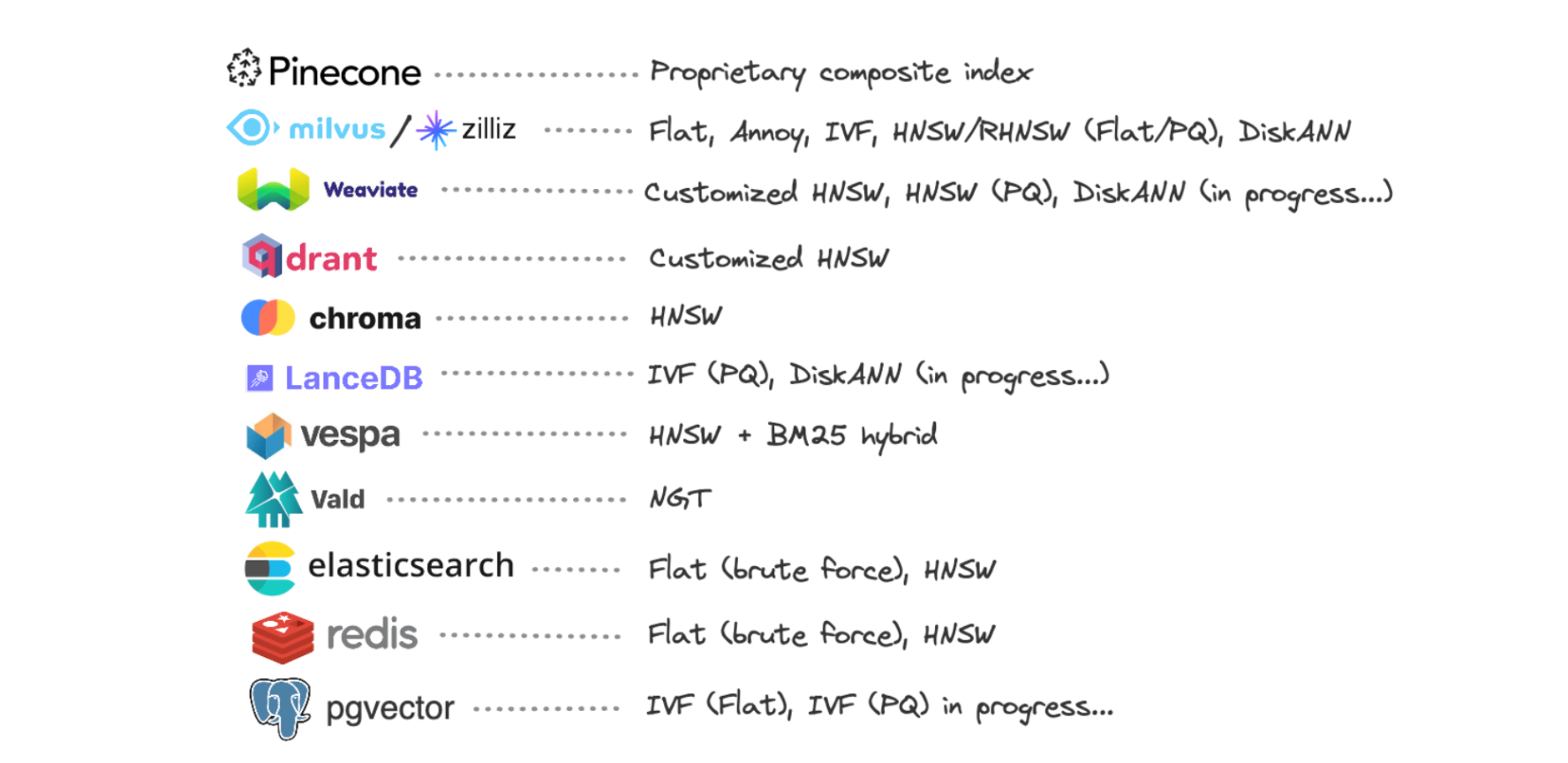
Approximate Search Indices
Approximate search indices like HNSW are optimized for fast and scalable retrieval of vectors based on approximate similarity metrics. These indices sacrifice some accuracy in exchange for improved performance and scalability, making them well-suited for large-scale datasets or scenarios where exact matches are not strictly required.
Pre-Filtering
Pre-filtering is like putting on a pair of glasses before searching for something. It helps you see clearer by narrowing down the search space before you even start looking. In vector databases, pre-filtering works by applying specific criteria or conditions to the dataset upfront. This means we figure out which data points are worth considering before we dive into the heavy lifting of similarity computations.
Pre-filtering reduces the number of vectors we need to compare during the search by weeding out irrelevant candidates early on. With a smaller pool of data to search through, queries run faster and more efficiently.
Post-Filtering
Post-filtering is like fine-tuning your search results after you've already done the heavy lifting. Once similarity computations are done, post-filtering steps in to refine the results based on additional criteria or ranking algorithms. It's like putting the finishing touches on your search to make sure you get exactly what you're looking for.
Post-filtering allows us to prioritize or exclude search results based on relevance, similarity scores, or user preferences. By tweaking the results after the fact, post-filtering ensures that the final output meets the user's expectations.
Hybrid Search
Hybrid search combines exact and approximate search methodologies to balance accuracy and scalability. By integrating the strengths of both keyword-based search methods and vector search techniques, hybrid search offers users a comprehensive and efficient means of retrieval.
Sparse Vectors
Sparse vectors offer a unique approach to data representation where most values are zero, highlighting only the essential information. By focusing only on significant elements, sparse vectors optimize storage, computation, and understanding, making them invaluable in RAG tasks where efficiency and interpretability are paramount.
Full text search
BM25 is a probabilistic information retrieval model that improves search relevance by considering factors such as term frequency and document length. Integration of BM25 scoring enables relevance ranking of search results based on keyword relevance and document quality. BM25 enhances the accuracy and effectiveness of text-based search queries.
Model Inference Support
Consider the support for models you’ll be using in your RAG system to ensure effective integration with your vector database of choice.
Embedding Model Integration
A native integration with encoder models facilitates seamless generation and indexing of vector embeddings without setting up embedder inferencing. Common models include sentence transformers, Mixedbread, BGE, OpenAI & Cohere.
Reranking Model Integration
Integrating a reranker in a vector database enhances its search capabilities by fine-tuning and re-ranking search results based on specific criteria. Rerankers analyze the initial search output and adjust the ranking to better match user preferences or application requirements. Native support for rerankers is very useful for high-quality results without engineering overhead.
Performance
Performance tuning is a serious aspect of any vector database, influencing its suitability for various applications and workloads. In this section, we'll delve into two key performance metrics: insertion speed and query speed.
Insertion Speed
Insertion speed refers to the rate at which new data points or vectors can be added to the vector database. Fast insertion speed is essential for real-time or streaming applications where data arrives continuously and needs to be ingested promptly without causing delays or bottlenecks.
Vector databases employ various techniques to optimize insertion speed, including batch processing, parallelization, and data partitioning. Batch processing enables efficient bulk loading of data, while parallelization distributes insertion tasks across multiple threads or nodes to leverage parallel computing resources. Data partitioning divides the dataset into smaller segments, allowing for concurrent insertion operations and reducing contention.
Query Speed
Query speed refers to the time it takes to retrieve relevant data points or vectors from the database in response to user queries or search requests. Fast query speed is essential for delivering responsive user experiences and enabling real-time analytics or decision-making applications.
To achieve fast query speed, vector databases employ various optimization techniques. These may include index structures, caching mechanisms, and query optimization algorithms. Index structures are like signposts that help you find things faster by organizing data in a way that makes it easier to search. Caching mechanisms store frequently accessed data in memory, reducing the need to fetch it from disk every time.
Cost Considerations
Cost-saving measures are essential for optimizing expenses and maximizing efficiency in database management. Organizations can achieve significant savings without compromising performance or functionality by implementing some common strategies.
Disk Index
Disk-based indexing stores vector embeddings directly on disk, minimizing memory overhead and enabling efficient storage and retrieval. Disk-based indexes may include memory-mapped files, disk-based hash tables, or segmented disk storage. Disk-based indexing enhances scalability and durability for large datasets exceeding memory capacity.
Serverless
Serverless vector database solutions offer a pay-as-you-go pricing model, minimizing upfront infrastructure costs and idle resource expenses. Serverless architectures scale automatically based on usage, eliminating the need for capacity planning or resource provisioning. Serverless deployments optimize cost efficiency and resource utilization for variable workloads.
Binary Quantization
Binary quantization further compresses vector embeddings into binary codes, minimizing storage overhead and accelerating similarity computations. Binary quantization reduces memory footprint and storage costs while enabling efficient similarity search in large-scale datasets.
Maintenance & Support
Ensuring the smooth operation of your vector database is vital for maximizing its benefits.
Managed database
Managed vector database services offer infrastructure management, maintenance, and optimization. Managed services may include automated provisioning, monitoring, patching, and backup management. Managed solutions ensure high availability, reliability, and performance without requiring dedicated operational resources.
Auto Scalability
Auto scalability features dynamically adjust resource allocation based on workload demands, ensuring optimal performance and cost-efficiency. Automated scaling may include vertical scaling (resizing resources within a single node) or horizontal scaling (adding or removing nodes dynamically). Auto scalability optimizes resource utilization and accommodates fluctuating workloads or data growth.
Monitoring and Alerts
Comprehensive monitoring and alerting capabilities provide real-time insights into database performance, health, and usage metrics. Monitoring features may include memory usage, query latency, and throughput. Alerting mechanisms notify administrators of anomalies, errors, or performance degradation, enabling timely intervention and optimization.
Multi-tier Storage
Multi-tier storage refers to data organization across multiple storage layers, each offering different performance and cost characteristics. This approach allows organizations to optimize storage utilization by storing frequently accessed or critical data on high-performance storage tiers (such as SSDs) while relegating less frequently accessed or archival data to lower-cost, lower-performance tiers (such as HDDs or cloud storage). By implementing multi-tier storage, organizations can achieve a balance between performance, cost-effectiveness, and scalability, ensuring that data is stored efficiently according to its access patterns and importance.
Backups
Better safe than sorry! Regular backups are essential for data durability, disaster recovery, and compliance with regulatory requirements. Backup features may include full backups, incremental backups, and point-in-time recovery. Automated backup schedules ensure data integrity and minimize the risk of data loss or corruption during failures.
Conclusion
Selecting the right vector database involves thoroughly understanding technical requirements, performance considerations, and scalability needs. Mastering the selection process empowers organizations to leverage the full potential of vector databases and unlock valuable insights from their private data. Choose wisely, and embark on a successful journey with the right vector database by your side!
Subscribe to Newsletter
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
