HP + Galileo Partner to Accelerate Trustworthy AI
RAG Vs Fine-Tuning Vs Both: A Guide For Optimizing LLM Performance




Welcome to the latest instalment in our LLM blog series! One of the most significant debates across generative AI revolves around the choice between Fine-tuning, Retrieval Augmented Generation (RAG) or a combination of both. In this blog post, we will explore both techniques, highlighting their strengths, weaknesses, and the factors that can help you make an informed choice for your LLM project. By the end of this blog, you will have a clear understanding of harnessing the full potential of these approaches to drive the success of your AI.

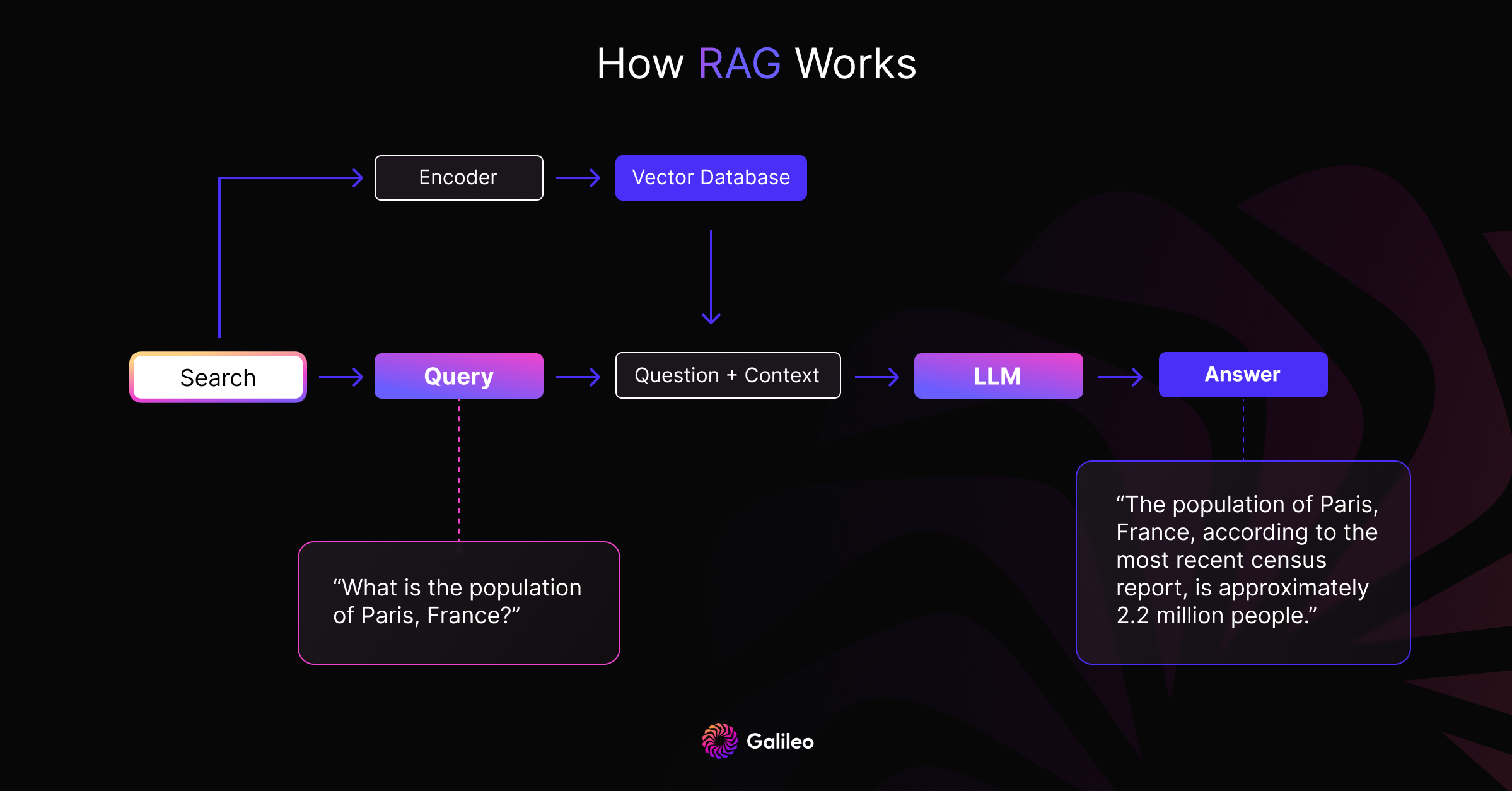
This is the most basic RAG system, and you can refer to Enteprise architecture if you want to understand how to build one.
Fine-Tuning vs. Retrieval Augmented Generation: A False Dichotomy
Before diving into the comparison, it's crucial to understand that Fine-tuning and Retrieval Augmented Generation are not opposing techniques. Instead, they can be used in conjunction to leverage the strengths of each approach. Let’s explore this in detail.
The Two Types of Fine-Tuning
Language Modeling Task Fine-tuning:
Purpose: Language model task fine-tuning is a broader approach that aims to adapt a pre-trained language model (like GPT-3 & Llama 2) to perform next token prediction.
Training Data: The training data for language modeling task fine-tuning includes raw unsupervised text where we leverage the next token as the prediction label.
Supervised Q&A Fine-tuning
Purpose: Supervised Q&A fine-tuning is a more specialized form focusing on improving the model's performance in question-answering tasks.
Training data: The training data for supervised Q&A fine-tuning consists of question-answer pairs. This data is used to fine-tune the model specifically for tasks where the input is a question, and the desired output is an answer.
Distinct Purposes
Fine-tuning helps adapt the general language model to perform well on specific tasks, making it more task-specific.
Retrieval Augmented Generation (RAG) focuses on connecting the LLM to external knowledge sources through retrieval mechanisms. It combines generative capabilities with the ability to search for and incorporate relevant information from a knowledge base.
RAG and Fine-Tuning: Complementary Roles
Combining RAG and fine-tuning in an LLM project offers a powerful synergy that can significantly enhance model performance and reliability. While RAG excels at providing access to dynamic external data sources and offers transparency in response generation, fine-tuning adds a crucial layer of adaptability and refinement.
Without fine-tuning, the model can continue making the same mistakes. Fine-tuning allows for correcting such errors by fine-tuning the model with domain-specific and error-corrected data. Other benefits include learning the desired generation tone and handling the long tail of edge cases more gracefully.

Research on RAG Fine-tuning
Retrieval Augmented Fine Tuning (RAFT)
A recent paper RAFT: Adapting Language Model to Domain Specific RAG takes the principles of RAG a step further by not only integrating retrieval into the generation process but also fine-tuning the model to better handle the retrieved documents. In RAFT, given a question and a set of retrieved documents, the model is trained to ignore distractor documents—those that do not help in answering the question. This leads to significant improvements in model performance for open-domain question answering.


ChatQA
In ChatQA, the researchers demonstrates how to surpass even GPT-4 in performance for RAG and conversational question answering (QA). Here are the key insights from recent research on this topic:
The research proposes a novel two-stage instruction tuning method that significantly boosts the performance of RAG models. This approach involves refining the model's ability to integrate user-provided or retrieved context, which is crucial for generating accurate and relevant responses in conversational QA tasks.


By carefully curating the training data with instruction, conversational and RAG datasets, the model's capability to handle context in conversations is greatly enhanced, leading to superior performance in RAG tasks.


These experiments serve as compelling evidence that combining RAG and fine-tuning can significantly minimize hallucinations.
7 Factors to Consider When Evaluating Fine-Tuning and RAG
1. Dynamic vs. Static Data
RAG
RAG excels in dynamic data environments. It continuously queries external sources, ensuring that the information remains up-to-date without frequent model retraining.
Fine-Tuning
Fine-tuned models become static data snapshots during training and may quickly become outdated in dynamic data scenarios. Furthermore, fine-tuning does not guarantee recall of this knowledge, making it unreliable.
Conclusion: RAG offers agility and up-to-date responses in rapidly evolving data landscapes, making it ideal for projects with dynamic information needs.
2. External Knowledge
RAG
RAG is designed to augment LLM capabilities by retrieving relevant information from knowledge sources before generating a response. It's ideal for applications that query databases, documents, or other structured/unstructured data repositories. RAG excels at leveraging external sources to enhance responses.
Fine-Tuning
While it's possible to fine-tune an LLM to learn external knowledge, it may not be more practical for frequently changing data sources. Usually, training and evaluating models can be difficult and time-consuming.
Conclusion: RAG is likely the better option if your application heavily relies on external data sources due to its flexibility and ability to adapt to changing information.
3. Model Customization
RAG
RAG primarily focuses on information retrieval and may not inherently adapt its linguistic style or domain-specificity based on the retrieved information. It excels at incorporating external knowledge but may not fully customize the model's behavior or writing style.
Fine-Tuning
Fine-tuning allows you to adapt an LLM's behavior, writing style, or domain-specific knowledge to specific nuances, tones, or terminologies. It offers deep alignment with particular styles or expertise areas.
Conclusion: Fine-tuning offers a more direct route if your application demands specialized writing styles or deep alignment with domain-specific vocabulary and conventions.
4. Reducing Hallucinations
RAG
RAG systems are inherently less prone to hallucination because they ground each response in retrieved evidence, reducing the model's ability to fabricate responses.
Fine-Tuning
Fine-tuning can help reduce hallucinations by grounding the model in a specific domain's training data. However, it may still fabricate responses when faced with unfamiliar inputs.
Conclusion: RAG systems provide better mechanisms to minimize hallucinations for applications where suppressing falsehoods and imaginative fabrications is vital.
5. Transparency
RAG
RAG systems offer transparency by breaking down response generation into distinct stages, providing insight into data retrieval and fostering trust in outputs.
Fine-Tuning
Fine-tuning operates like a black box, making the reasoning behind responses more opaque.
Conclusion: RAG provides a clear advantage if transparency and interpretability are priorities
6. Cost Benefits of Smaller Models
RAG
RAG does not allow us to use a smaller model.
Fine-Tuning
Fine-tuning can play a pivotal role in improving the effectiveness of small models, which in turn can lead to cheaper and faster inference. Smaller models require less hardware infrastructure for deployment and maintenance, which translates to cost savings in terms of cloud computing expenses or hardware procurement.
Conclusion: When cost considerations are paramount, training and deploying smaller models can yield substantial savings, particularly at scale—advantage fine-tuning.
7. Technical Expertise
RAG
Implementing RAG typically requires a moderate to advanced level of technical expertise. Setting up the retrieval mechanisms, integrating with external data sources, and ensuring data freshness can be complex tasks. Additionally, designing efficient retrieval strategies and handling large-scale databases efficiently demand technical proficiency. However, various pre-built RAG frameworks and tools are available, simplifying the process to some extent.
Fine-tuning
Fine-tuning, especially with large language models, demands high technical expertise. Preparing and curating high-quality training datasets, defining fine-tuning objectives, and managing the fine-tuning process are intricate tasks. Furthermore, fine-tuning often involves substantial computational resources, making it essential to have expertise in handling such infrastructure. Fine-tuning also requires understanding domain-specific nuances and creating appropriate evaluation metrics.
Conclusion: RAG leans towards moderate technical expertise, mainly in data integration and retrieval mechanisms. Fine-tuning, on the other hand, demands a higher level of technical proficiency due to the complexities involved in data preparation, infrastructure management, and domain-specific adaptation.
How Can We Apply This to Use Cases?
Now, let's take what we've learned above and apply it to various use cases. We will consider different parameters for these use cases to determine the ultimate recommendation.

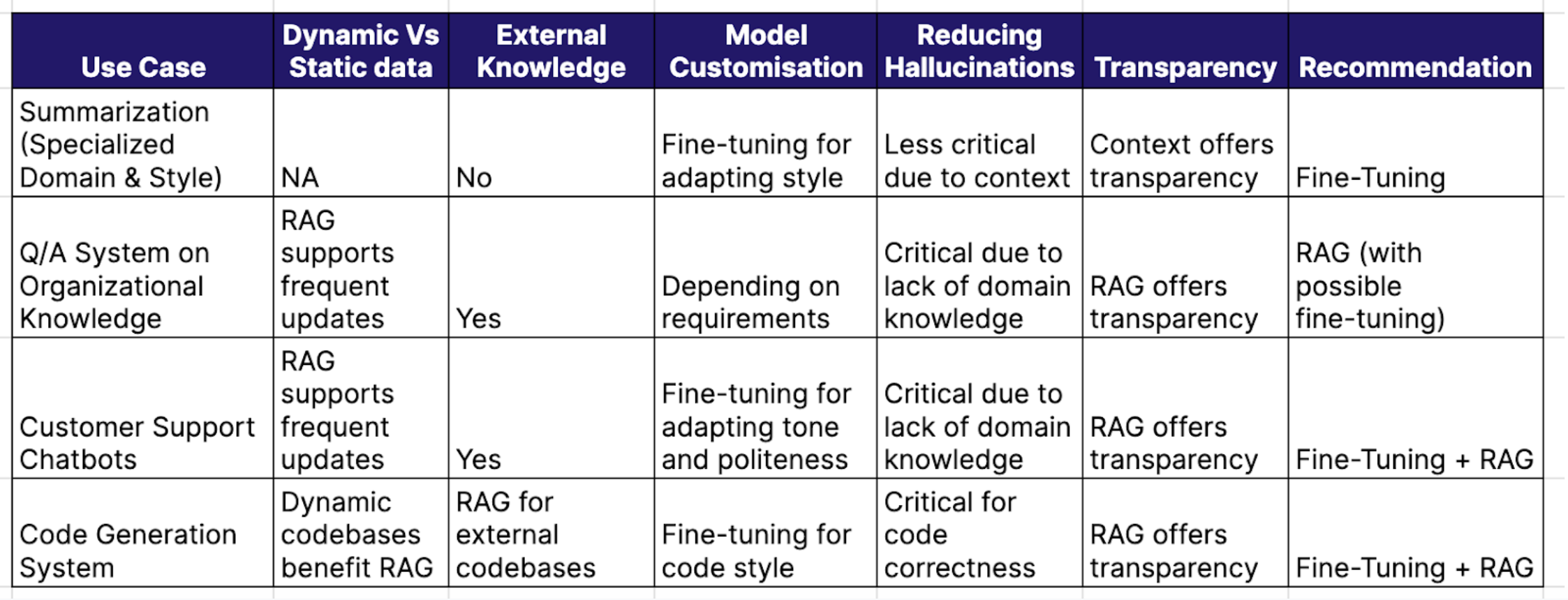
Summarisation - Summarise articles
Question answering - Question-answering system on internal documents of a company
Customer support chatbot - Answer queries of an e-commerce website
Code generation - System to suggest code based on private + public codebase
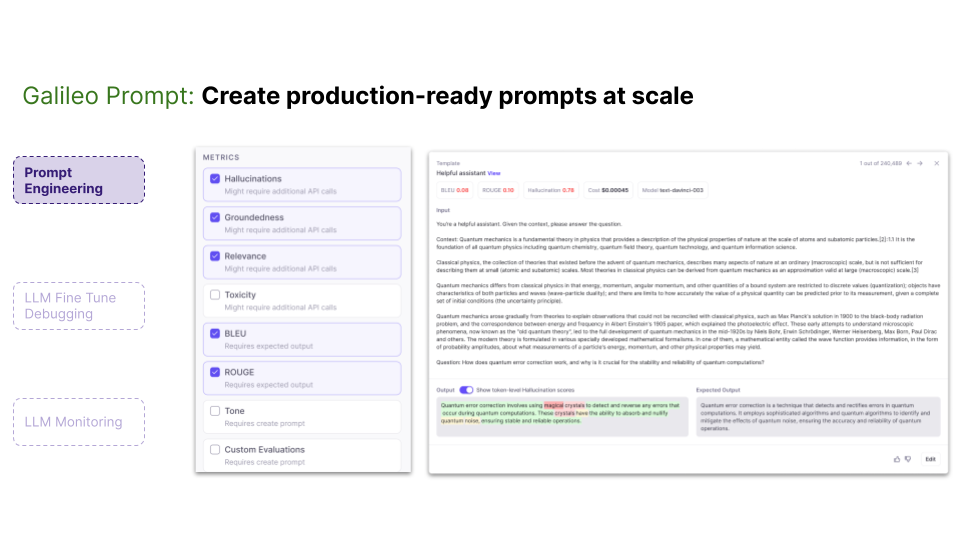
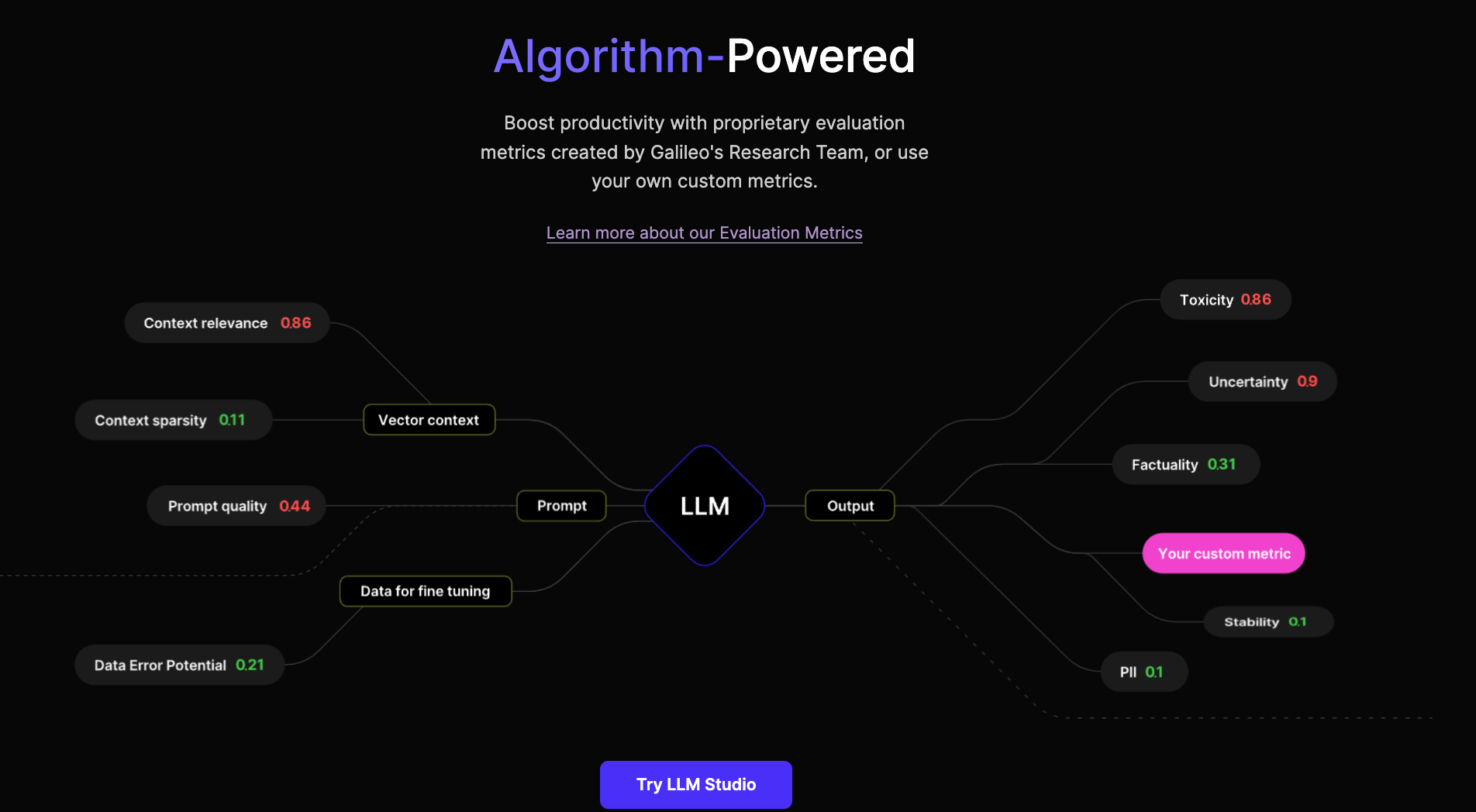
At Galileo, we're dedicated to enhancing the performance of your LLMs throughout the machine learning journey. If you're opting for the Retrieval Augmented Generation (RAG) approach, Galileo Prompt can assist you in optimizing your prompts and model settings. You can choose from predefined metrics or custom metrics to assess your system's performance.

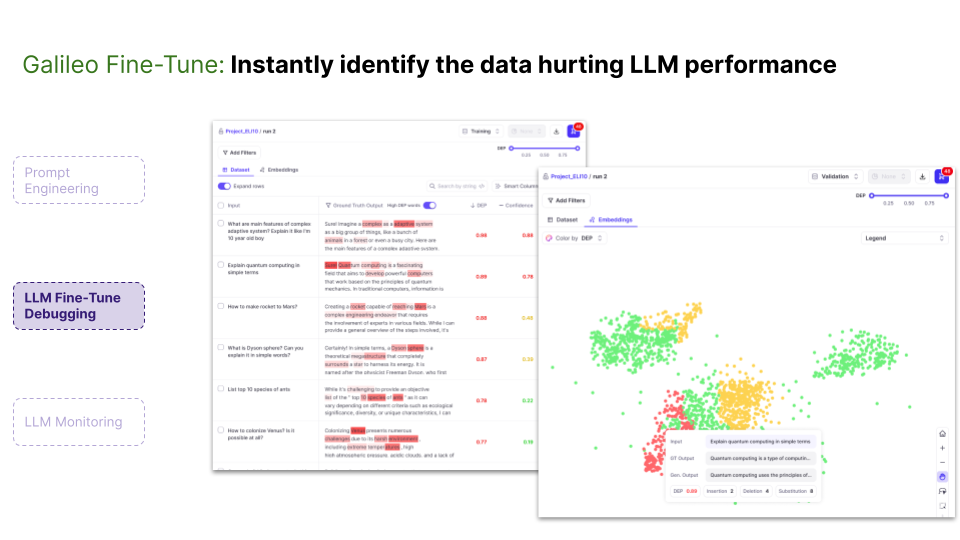
On the other hand, if you prefer the fine-tuning approach, Galileo Fine-Tune is your go-to tool. It helps identify errors in your training data, ultimately improving data quality. In both scenarios, our LLM Monitor enables real-time monitoring to detect and address hallucinations efficiently, ensuring a smoother and more reliable LLM experience.
Conclusion
When determining the best approach for your LLM project, it's essential to consider the specific requirements and limitations. Both approaches have their own strengths and weaknesses, and combining them might be the optimal solution. By choosing the right approach, you can unlock the full potential of your language model and create more reliable AI applications.
Galileo LLM Studio is the leading platform for rapid evaluation, experimentation and observability for teams building LLM powered applications. It is powered by a suite of metrics to identify and mitigate hallucinations. Join 1000s of developers building apps powered by LLMs and get early access!

Working with Natural Language Processing?
Read about Galileo’s NLP Studio
