All New: Evaluations for RAG & Chain applications
5 Techniques for Detecting LLM Hallucinations




Introduction
While LLMs are becoming increasingly proficient at an ever increasing number of use cases, LLM hallucinations remain a major hurdle to enterprise adoption. Mitigating hallucinations comes down to ensuring we work with the right prompts, data and providing the right context through a vector database. Galileo’s LLM studio is the LLM Ops platform to identify and mitigate hallucinations across prompt engineering, fine-tuning and production monitoring of your LLMs. Join 1000s of developers building apps powered by LLMs and get early access!
Finding hallucination in text generation has always been challenging. In our last post, we looked into different types of hallucinations and how they affect performance across different NLP tasks. In this article, we’ll look at five techniques, as covered in prominent research papers, for detecting and mitigating hallucinations in LLMs.
1. Log probability
The first technique comes from the paper Looking for a Needle in a Haystack: A Comprehensive Study of Hallucinations in Neural Machine Translation (Guerreiro et al. 2023).
Summary: In this paper the authors explore different detection techniques, reevaluating previous methods and introducing glass-box uncertainty-based detectors. The findings reveal that established methods are inadequate for preventive scenarios, with sequence log-probability proving most effective, comparable to reference-based methods. Additionally, the report introduces the DeHallucinator method, a straightforward approach that significantly reduces hallucination rates.
This paper proposes Seq-Logprob which calculates the length-normalized sequence log-probability for each word in the generated translation y for a trained model P (y|x, θ).

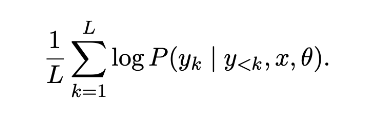
If a model is "hallucinating," it is likely not confident in its output. This means that the lower the model's confidence (as measured by Seq-Logprob), the higher the chance that it will produce a poor translation. This matches findings from previous studies on translation quality. Internal model characteristics may contain a lot more information than we expect.
Figure 1 demonstrates that Seq-Logprob is an effective heuristic for evaluating translation quality and performs similarly to the reference-based COMET method. One advantage of Seq-Logprob is its simplicity: unlike other methods that need additional computation, Seq-Logprob scores can be obtained easily during the translation process.

2. Sentence Similarity
The second paper is Detecting and Mitigating Hallucinations in Machine Translation: Model Internal Workings Alone Do Well, Sentence Similarity Even Better (David et al. Dec 2022)
Summary: This paper proposes evaluating the percentage of source contribution to generated translations and identifying hallucinations by detecting low source contribution. The team found this technique significantly enhances detection accuracy for severe hallucinations, outperforming previous approaches that relied on external models. They also found that sentence similarity from cross-lingual embeddings can further improve detection and mitigation of hallucinations.

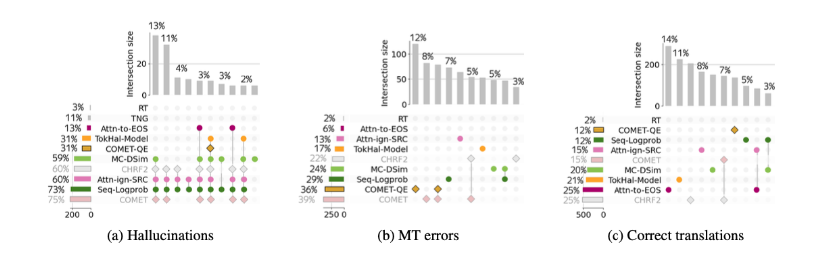
This paper evaluates NLI based reference free techniques in comparison to SOTA reference based and internal measures techniques. Here is a quick breakdown of all techniques.
Reference-Based
- ChrF: This represents the character n-gram F score of the translation in relation to the reference text. They implement the CHRf++ version that not only factors in character n-grams, but also word unigrams and bigrams [Popovic, 2017].
- COMET: Developed by Rei et al., COMET is a neural quality estimation metric that has been validated as a state-of-the-art reference-based method [Kocmi et al.].
Internal Measures
- Seq-Logprob: Length normalized log prob as described earlier.
- ALTI: Essentially, ALTI breaks down each transformer block into a collection of individual token functions, taking the output representation as an aggregation of transformed input vectors. It then assesses the impact of these vectors on the final summation. Interesting findings revealed by ALTI+ and an earlier LRP-based method by Voita et al. [2021] include the lower influence of the source in artificially created hallucinations compared to normal accurate translations. They quantify the total source contribution by adding up contributions from all source tokens for each target token and then averaging the results. The same model that generated the translations calculates these scores.
Reference-free
- COMET-QE: In terms of reference-free models, they utilize the advanced COMET-QE [Rei et al., 2020b] because of its high performance in comparison to other quality estimators.
In addition to these, they employ three distinct measures based on pretrained models to assess the semantic similarity between two sentences:
LASER: This measures the cosine similarity of the source and translation sentence embeddings using LASER2 [Heffernan et al.]. LASER2 enhances the original LASER [Artetxe and Schwenk] by substituting the LSTM encoder with a Transformer and applying teacher-student training.
LaBSE: The LaBSE measure evaluates the cosine similarity of the source and translation sentence embeddings [Feng et al.]. It's a dual-encoder approach that relies on pretrained transformers and is fine-tuned for translation ranking with an additive margin softmax loss.
XNLI: This entails calculating the product of the entailment probabilities from source to translation and vice versa. The entailment scores are computed using RoBERTa [Conneau et al., 2020] which has been fine-tuned on a compilation of NLI data in 15 languages [Conneau et al., 2018].
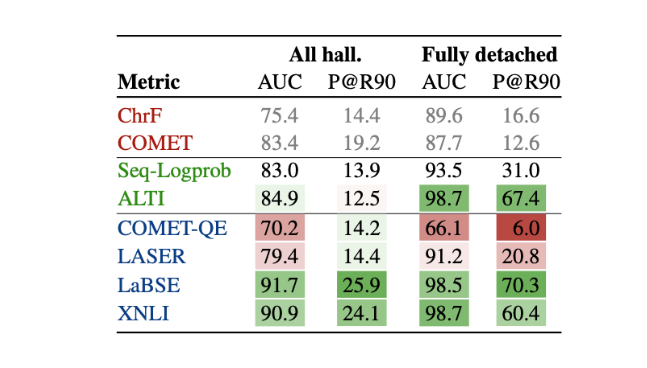
They find that LaBSE and XNLI significantly outpace their predecessor, Seq-Logprob, in detecting both all and completely detached hallucinations, doubling the precision at 90% recall. It's not surprising to see such performance from LaBSE, which evaluates cross-lingual sentence similarity, often interpreted as an indicator of translation quality. However, the excellent results from XNLI were unexpected.
3. SelfCheckGPT
The third technique comes from SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models (Manakul et al. 2023)
Summary: This paper evaluates techniques for hallucination using GPT when output probabilities are not available, as is often the case with black box which don’t provide access to output probability distributions. With this in mind, this technique explores three variants of SelfCheckGPT for assessing informational consistency.
SelfCheckGPT with BERTScore
SelfCheckGPT uses BERTScore to calculate the average BERTScore of a sentence when compared with the most similar sentence from each selected sample. If the information contained in a sentence is found across many selected samples, it is reasonable to conclude that the information is factual. On the other hand, if the statement does not appear in any other sample, it may likely be a hallucination or an outlier.

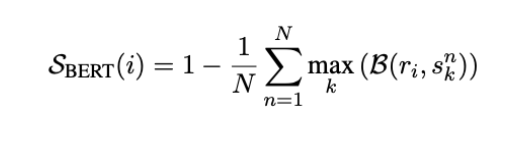
Here r_i refers to the i-th sentence in R, and s_nk refers to the sentence in the drawn samples.
SelfCheckGPT with Question Answering
They incorporate the automatic framework of multiple-choice question answering generation (MQAG) [Manakul et al.] into SelfCheckGPT. MQAG facilitates consistency assessment by creating multiple-choice questions that a separate answering system can answer for each passage. If the same questions are asked it's anticipated that the answering system will predict the same answers. The MQAG framework is constructed of three main components: a question-answer generation system (G1), a distractor generation system (G2), and an answering system (A).
For each sentence r_i within the response R, they formulate the corresponding questions q, their answers a and the distractors o_a. To eliminate unanswerable queries, they assign an answerability score. They utilize α to exclude unanswerable queries which have an α lower than a certain limit. Then they use the answering system to answer all the answerable questions. They compare answers from a sample with answers from all other samples. This gives us the matches(N_m) and non matches(N_n). They calculate a simple inconsistency score for ith sentence and qth question using Bayes theorem as shown below. Here N_m′ = the effective match count, N_n′ = the effective mismatch count, γ1, and γ2 are defined constants.

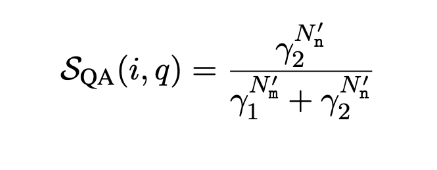
Final score is the mean of inconsistency scores across q.

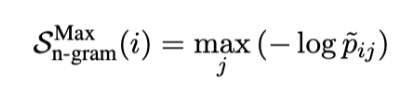
SelfCheckGPT Combination
Since different variants of SelfCheckGPT have different characteristics, they can provide complementary outcomes. They propose SelfCheckGPT-combination which integrates normalized scores from all the variants - S_bert, S_qa and S_ngram.
Results
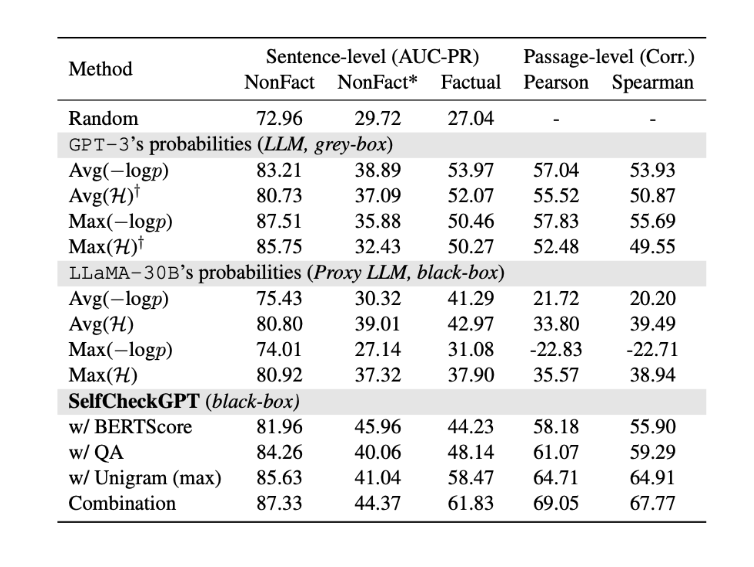
The results show that token probabilities are a good indicator of hallucinations. It is able to get AUC-PR of 53.97 compared to random baseline of 27.04. These results prove that when LLMs are uncertain about their generation, it shows up. Also, probability performs better than entropy of top-5 tokens.
Another insight is that proxy LLMs perform worse compared to the generator LLM. When using proxy LLMs like GPT-NeoX or OPT-30B, the performance is only slightly better than random baseline. This proves that LLMs have different characteristics of generation.
The good news is SelfCheckGPT gets comparable results to other probability based approaches. The simple approach of SelfCheckGPT with unigram performs great. If a token is found only a few times in the generations, it is likely to be hallucinated.
And the combination of all SelfCheckGPT gives the best score!

4. GPT4 prompting
The fourth technique comes from the paper Evaluating the Factual Consistency of Large Language Models Through News Summarization (Tam et al. 2023)
Summary: This paper focuses on the summarization use case and surveys different prompting techniques and models to find the best ways to detect hallucinations in summaries.
The authors try 2 types of prompting:
- Chain-of-thought prompting: They design chain-of-thought instruction which forces the model to generate the information from the document before giving the final conclusion.
- Sentence-by-sentence prompting: They break the summary into multiple sentences and verify facts for each.
They compare five LLMs - FLAN-T5-XXL, text-davinci-003, code-davinci-002, ChatGPT & GPT4 with five different baseline approaches:
DAE: An entailment based approach which calculates the factual score for each dependency arc in summary and aggregates them. [Goyal and Durrett]
QuestEval: Question-answer based approach which checks for answer overlap from questions generated from the summary and answered from document, and questions generated from the document and answered with the summary. [Scialom et al.]
QAFactEval: Question-answer based approach with better components which calculates the answer overlap scores from questions generated from the summary and answered from the document. [Fabbri et al.]
SummaC-ZS: Entailment based approach which finds the maximum entailment score for each sentence of summary and then computes the final score from these. [Laban et al., 2022]
SummaC-Conv: Entailment based approach which calculates scores with all source sentences and passes these scores through convolutional layers to generate summary sentence score and then aggregates similar to SummaC-ZS. [Laban et al., 2022]
The authors also experiment with different combinations of few-shot, zero-shot and prompts to find the best performance.


The below results show that performance improves by a good margin with a few-shot prompt. FLAN-T5 is excluded from testing with more than 2 prompts since it does not fit in the context window.

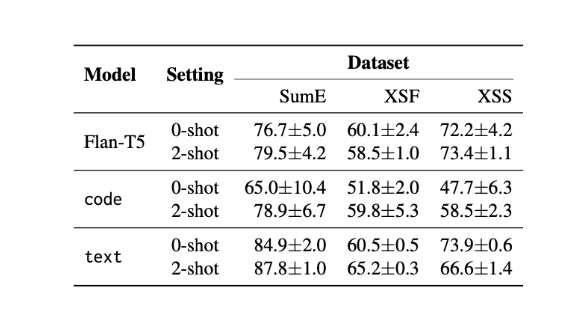
The below chart shows that performance does not necessarily improve with more samples in few-shot. The performance reduces for text-davinci-003 after 2 samples.

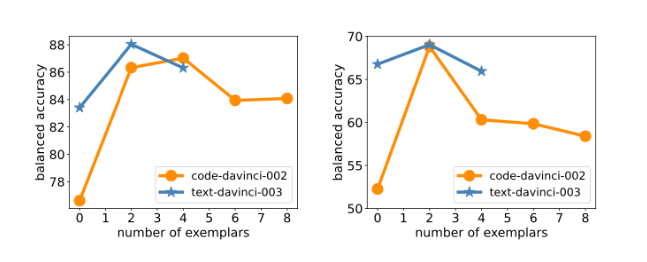
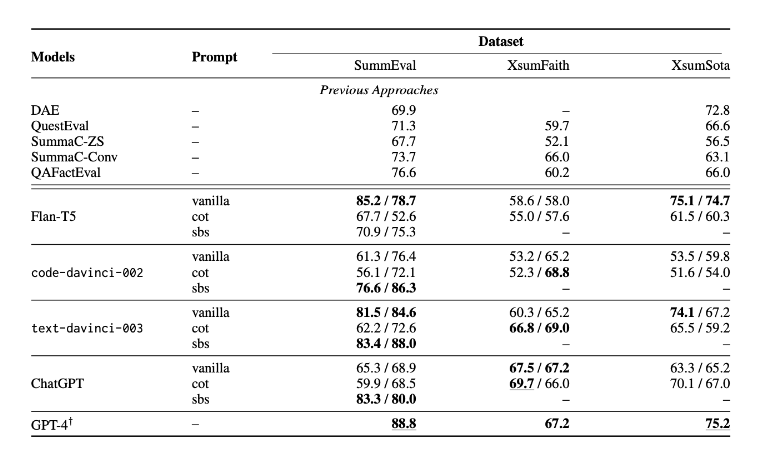
The results show that text-davinci-003 and GPT-4 are the best evaluators and beat the previous approaches. The other LLMs FLAN-T5, code-davinci-002 and ChatGPT outperform earlier SOTA on 2 out of 3 benchmarks.

5. G-EVAL
Our fifth and final technique comes from the paper G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment(Liu et al. 2023)
Summary: This paper proposes a framework for LLMs to evaluate the quality of NLG using chain of thoughts and form filling. They experiment with summary and dialogue generation datasets and beat previous approaches by a large margin.

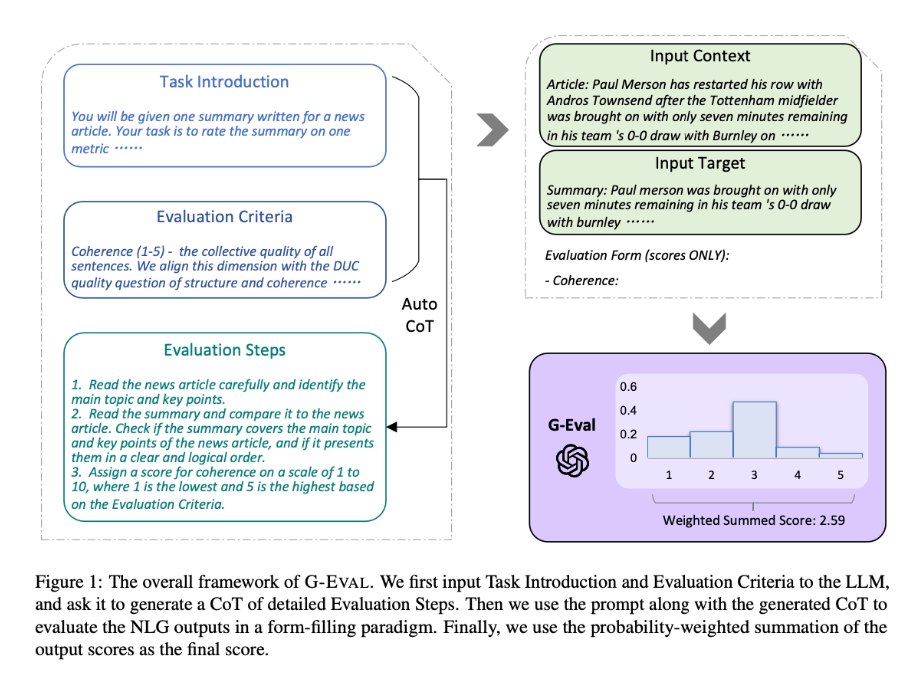
G-EVAL comprises three primary elements: a prompt defining the evaluation task and criteria, a chain-of-thoughts (CoT) consisting of intermediate instructions generated by the LLM for detailed evaluation steps, and a scoring function that utilizes the LLM to calculate scores based on returned token probabilities.
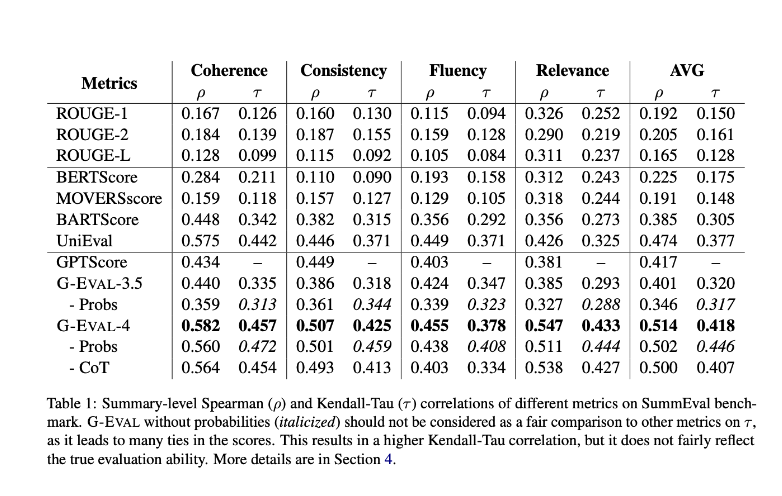
Overall G-EVAL-4 outperforms all other state of the art techniques by a large margin. This technique also performs well on QAGS-Xsum which has abstractive summaries.

The below prompt shows how hallucination is evaluated.


The below prompt shows how coherence is evaluated.


Conclusion
In this blog, we explored five approaches for detecting hallucinations in different NLP tasks. Each technique has its advantages and limitations, and the results vary depending on the task and dataset, but clearly GPT4 is best at this. It can be beneficial to combine multiple techniques for better performance.
These methodologies are crucial for enhancing the trustworthiness and adoption of these models in various enterprise applications
Galileo LLM Studio is the leading platform for rapid evaluation, experimentation and observability for teams building LLM powered applications. It is powered by a suite of metrics to identify and mitigate hallucinations. Join 1000s of developers building apps powered by LLMs and get early access!
Explore our research-backed evaluation metric for hallucination – read our paper on Chainpoll.
References
chrF++: words helping character n-grams [Popovic]
COMET: A neural framework for MT evaluation [Rei et al.]
Massively multilingual sentence embeddings for zero- shot cross-lingual transfer and beyond [Artetxe and Schwenk]Unsupervised cross-lingual representation learning at scale [Conneau et al.]
Xnli: Evaluating cross- lingual sentence representations [Conneau et al.]
Evaluating Factuality in Generation with Dependency-level Entailment [Goyal and Durrett]
QuestEval: Summarization Asks for Fact-based Evaluation [Scialom et al.]
SummEval: Re-evaluating Summarization Evaluation [Fabbri et al.]
SummaC: Re-visiting NLI- based models for inconsistency detection in summarization [Laban et al.]
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
