HP + Galileo Partner to Accelerate Trustworthy AI
Introducing RAG & Agent Analytics


Join Galileo and Pinecone on February 13, 2024 to see these latest product enhancements in action.
Today, Galileo is excited to introduce our latest product enhancement – Retrieval Augmented Generation (RAG) & Agent Analytics.
RAG has quickly soared in popularity, becoming the technique of choice for teams building domain-specific generative AI systems. RAG is relatively compute-efficient and requires less technical expertise to configure when compared to fine-tuning.
With that said, the complexity and opaqueness of RAG systems and their many moving parts has made RAG performance evaluation labor-intensive and manual. Each of these moving parts need to be evaluated and optimized, but teams have lacked the visibility to effectively debug and optimize these components; today, AI builders are limited to the trial and error of experimenting with inputs and context, and seeing what outputs are generated.
Galileo’s RAG & Agent Analytics shines a light into the black box by providing AI builders with a powerful set of tools and metrics to evaluate and optimize the inner workings of their RAG systems.
Building Better Retrieval Mechanisms
Typical RAG systems have three key processes: Retrieval, Augmentation, and Generation. Retrieval has the greatest impact on output quality, latency, and cost.


AI builders from dozens of companies told us again and again that Retrieval is where teams have the least visibility. Teams are looking for an easy way to answer questions like:
“How should I adapt my chunking strategy?”
“Why is my RAG system returning this response?”
“Is this response a result of my chunking strategy or the context I’ve provided?”
These questions become increasingly difficult to answer as teams build more advanced chain and agent-based applications at scale.
Introducing RAG & Agent Analytics
With this in mind, we’re excited to introduce RAG & Agent Analytics – a set of powerful metrics and AI-assisted workflows that make it easier for teams to build and ship production-ready retrieval-based applications!

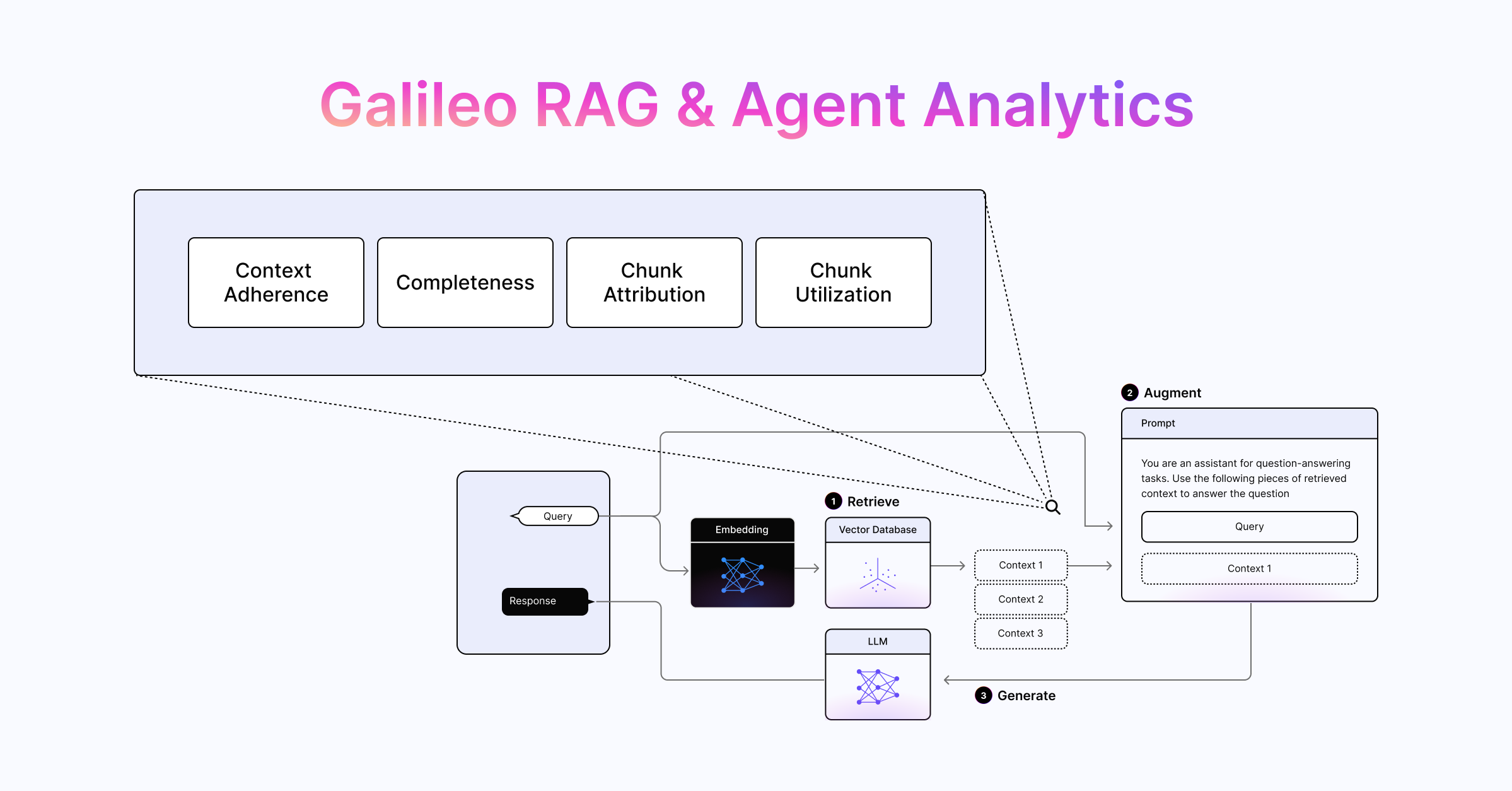
Taking Output Quality Evaluation a Step Further
First, we wanted to help teams take a more nuanced approach to evaluating output quality. Historically, the challenge with measuring output quality in retrieval-based systems is “it depends” – on the query, the context, the prompt, and more.
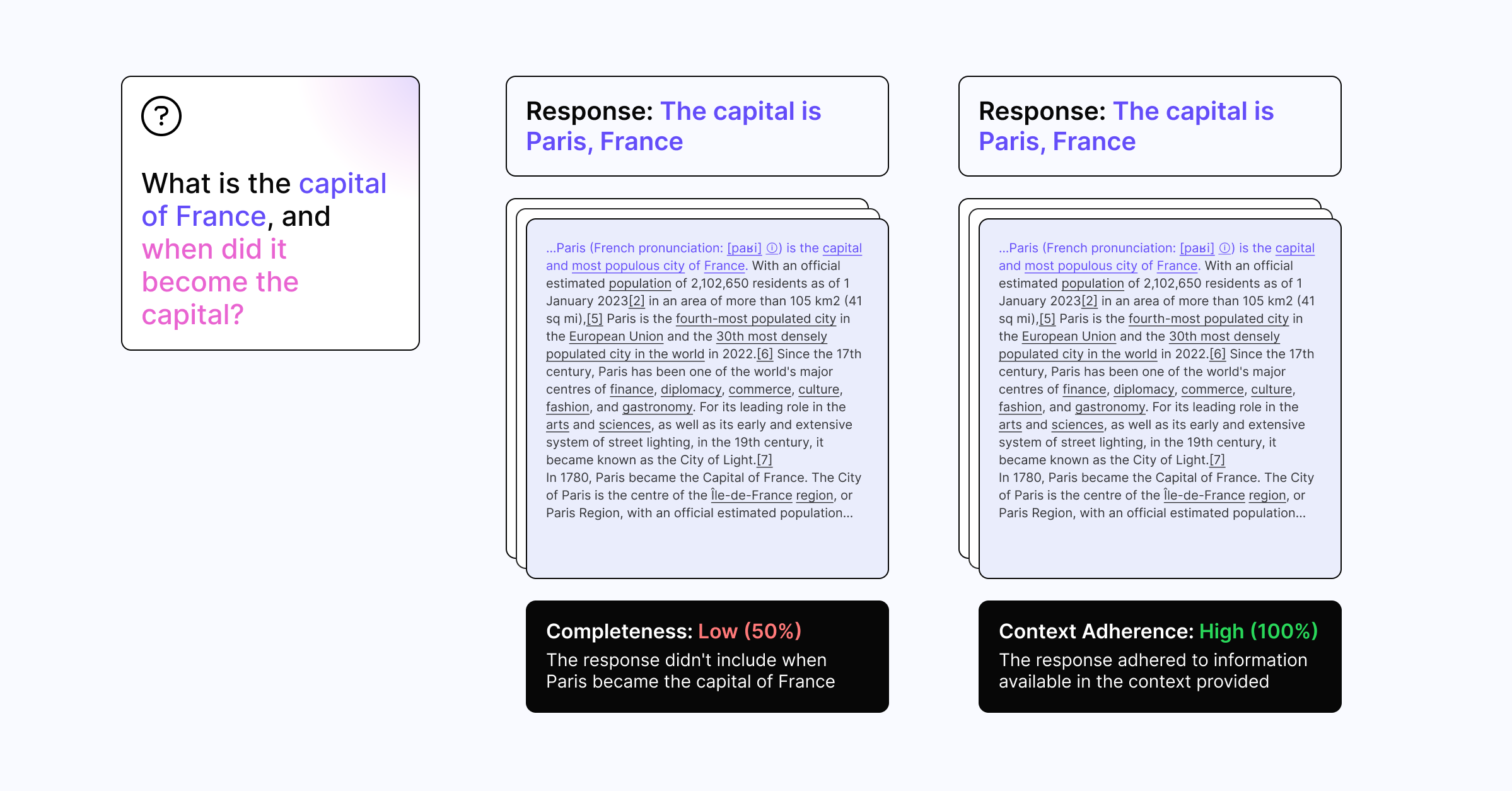
Context Adherence: Last year, to help teams measure output quality, we introduced Context Adherence. Context Adherence measures how well an output adheres to the context provided, with a low score suggesting a high likelihood of hallucination.
Completeness: To take output quality evaluation a step further, Galileo’s R&D unit, Galileo Labs, is excited to introduce Completeness – an all-new metric for measuring how well a system recalls information.
Completeness measures how comprehensively the response addresses the question using all the relevant information from the provided context. If Completeness is low, that means the output missed relevant information that was included in the context. If Completeness is high, that means the output effectively referenced available information in the provided context to answer the question.
Used together, Context Adherence and Completeness become a powerful combination for evaluating output quality and identifying ways to improve retrieval.
During testing, Completeness accuracy was 80%, which was 1.61x more accurate than baseline evaluations with GPT-3.5-Turbo, and Context Adherence accuracy was 74% - 1.65x more accurate than baseline evaluations with GPT-3.5-Turbo.
Improving Your Chunking Strategy
Chunking, or the process of splitting larger content into smaller segments, is useful for optimizing the relevance of the content returned from a vector database. Chunking strategy can be influenced by a variety of factors, like the nature of the context being provided, the embedding model you’re using, or length and complexity of user queries.
To help teams optimize their chunking strategy and make more informed chunking decisions, Galileo Labs has developed two research-backed metrics – Chunk Attribution and Chunk Utilization. Together, these proprietary evaluation metrics help teams determine which chunks were used and how much of those chunks were used when generating a response.
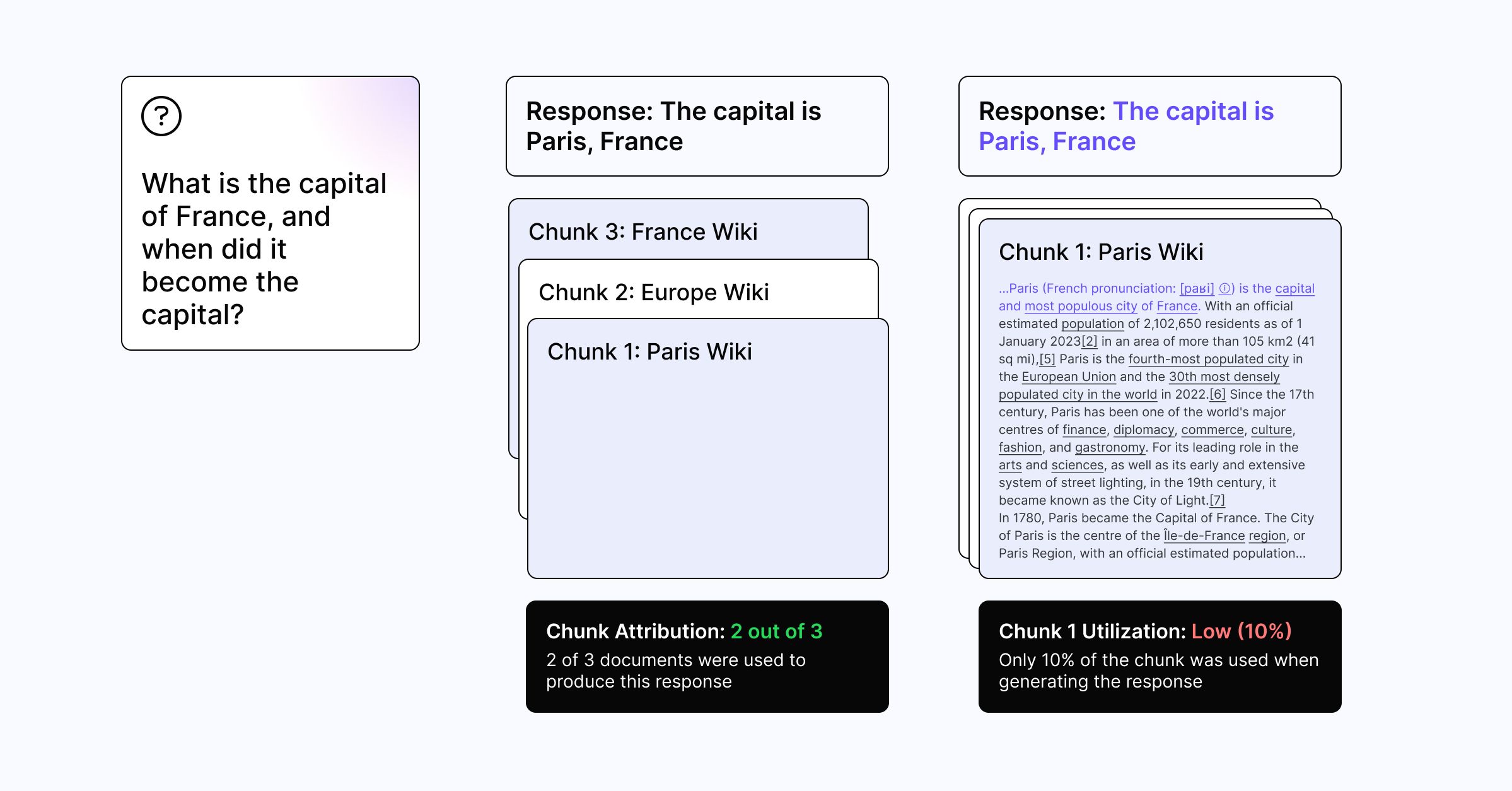
Chunk Attribution: Chunk Attribution measures the number of chunks a model uses when generating an output. By optimizing the number of chunks a model is retrieving, teams can improve output quality, increase system performance, and reduce excess costs of unused chunks.
Chunk Utilization: Chunk Utilization measures how much of each chunk was used by a model when generating an output and helps teams rightsize their chunk size. For example, having chunks that are unnecessarily large equates to more tokens, cost, and potential distractions for the model which can impact output quality.
When used together, Chunk Attribution and Chunk Utilization serve as a powerful way of evaluating and optimizing chunking and retrieval strategies.
During testing, Chunk Attribution accuracy was 86%, which is 1.36x more accurate than baseline evaluations with GPT-3.5-Turbo, and Chunk Utilization accuracy was 74% - 1.69x more accurate than baseline evaluations with GPT-3.5-Turbo.
Accelerating Debugging with Traces & Visualizations
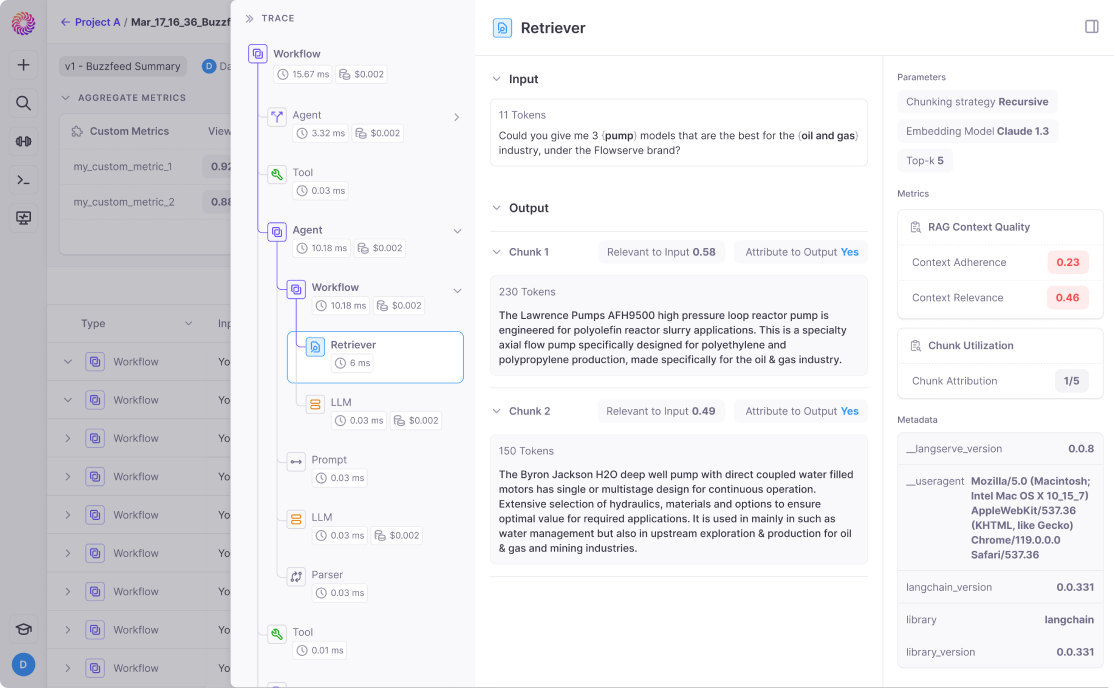
Last, but certainly not least, we wanted to make it easy for teams to trace and debug complex chains and agents directly in Galileo.
To assist with this, we’ve created trace visualizations to help you track all steps of your workflow. You can click into a step to review what inputs went into the step and what output came out. You can apply any of our Guardrail Metrics on your step to get step-by-step evaluations. This allows you to quickly identify the weak links in your system and address them before they impact output quality.

Accelerate Evaluation and Optimization with RAG & Agent Analytics
We hope our latest enhancements simplify the process of constructing, debugging, and refining retrieval-based systems. Whether you're working with chains or agents, our metrics and workflows are geared towards streamlining performance optimization, cost reduction, and accuracy improvement. Ultimately, these metrics are designed to boost explainability and foster a path toward more reliable and trustworthy AI outcomes.
Dive further into the details about these metrics in our documentation.
Or better yet get hands-on with our demo-driven webinar with Pinecone below!
Subscribe to Newsletter
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
