HP + Galileo Partner to Accelerate Trustworthy AI
Introducing the Hallucination Index






As 2023 comes to a close, many enterprise teams have successfully deployed LLMs in production, while many others have committed to deploying Generative AI products in 2024. However, when we talk to enterprise AI teams, the biggest hurdle to deploying production-ready Generative AI products remains the fear of model hallucinations – a catch-all phrase for when the model generates incorrect or fabricated text. There can be several reasons for this, such as a lack of the model’s capacity to memorize all of the information it was fed, training data errors, and outdated training data.
What makes tackling hallucinations so tricky is the variability and nuance that comes with generative AI. LLMs are not one size fits all when it comes to hallucinations – the dataset, the task type (with or without context), and LLM all play a role in influencing hallucinations. Furthermore, every business is different. Some are optimizing for cost while others are optimizing for sheer performance.
So, with this Hallucination Index benchmark across popular LLMs, we wanted to accomplish three things:
- First, we wanted to give teams an understanding of what attributes to consider (e.g., cost, performance, task type), and a framework for evaluating the tradeoffs between these attributes.
- Second, we wanted to give teams a starting point for addressing hallucinations. While we don’t expect teams to treat the results of the Hallucination Index as gospel, we do hope the Index serves as an extremely thorough starting point to kick-start their Generative AI efforts.
- Third, we hope the metrics and evaluation methods covered in the Hallucination Index (e.g., Correctness, Context Adherence, ChainPoll) arm teams with tools to more quickly and effectively evaluate LLM models to find the perfect LLM for their initiative.
This Index aims to provide a framework to help teams select the right LLM for their project and use case.
Have a look at the Hallucination Index here!
Another Benchmark?!?!
The first question you’re probably asking is “why another benchmark?” After all, there is no shortage of benchmarks such as Stanford CRFM’s Foundation Model Transparency Index and Hugging Face’s Open LLM Leaderboard.
While existing benchmarks do much to advance the adoption of LLMs, they have a few critical blindspots.
- Not focused on LLM output quality: Existing benchmarks provide a generic evaluation of LLM attributes and performance, and not a focused evaluation of the quality of the LLMs output (hallucination likelihood). As a result, these benchmarks do not leverage metrics that measure the actual quality of LLM outputs – one of the top concerns for enterprise GenAI teams today.
- Not focused on task type: A practical benchmark useful for Enterprise genAI teams needs to cater to the variability in task types. For instance, a model that works well for chat, might not be great at text summarization.
- Not focused on the power of context: Retrieval augmented generation (RAG) is a popular technique across teams to provide LLMs with useful context. LLM benchmarks today ignore how they perform with context – granted there is nuance here with regards to the quality of the context, but measuring variability in LLM performance across RAG vs non-RAG tasks is critical.
Principles of the Hallucination Index Methodology
We designed the Hallucination Index to address the practical needs of teams building real-world applications. The Hallucination Index was built with four principles in mind.
1. Task Centric
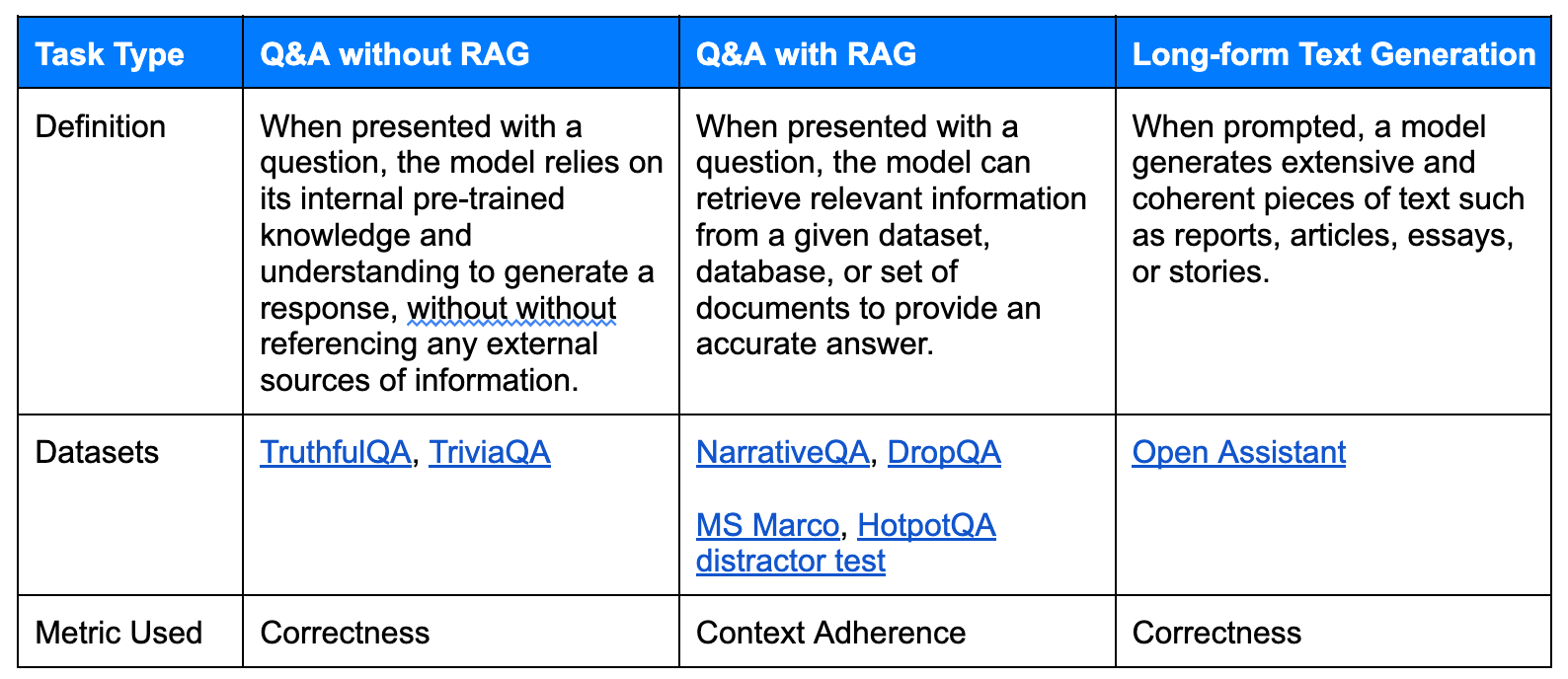
While LLM-based applications can take many shapes and sizes, in conversations with enterprise teams, we noticed a generative AI applications typically fall into one of three tasks types: Question & Answer without RAG, Question & Answer with RAG, and Long-form Text Generation.
To evaluate each LLM’s performance for each task type, the Index uses seven popular and rigorous benchmarking datasets. The datasets effectively challenge each LLM's capabilities relevant to the task at hand. For instance, for Q&A without RAG, we utilized broad-based knowledge datasets like TruthfulQA and TriviaQA to evaluate how well these models handle general inquiries.
This approach makes it easy for readers to identify the ideal LLM for their specific task type.

2. Context Matters
While the debate rages on about the best approach to use when building generative AI applications, retrieval augmented generation (RAG) is increasingly becoming a method of choice for many enterprises.
When it comes to RAG, each LLM responds differently when provided with context due to a variety of reasons, such as context limits and variability in the context window. To evaluate the impact of context on an LLM’s performance, the Index measured each LLM’s propensity to hallucinate when provided with context. To do this, we used datasets that come with verified context.
3. Measure Output Quality
While existing benchmarks stick to traditional statistical metrics, detecting hallucinations reliably has more to do with detecting qualitative nuances in the model’s output that are specific to the task types. While asking GPT-4 to detect hallucinations is a popular (albeit expensive) method to rely on, ChainPoll has emerged as a superior method to detect hallucinations from your model’s outputs, with a high correlation against human benchmarking.
The Hallucination Index is explicitly focused on addressing those qualitative aspects of the desired generated output.

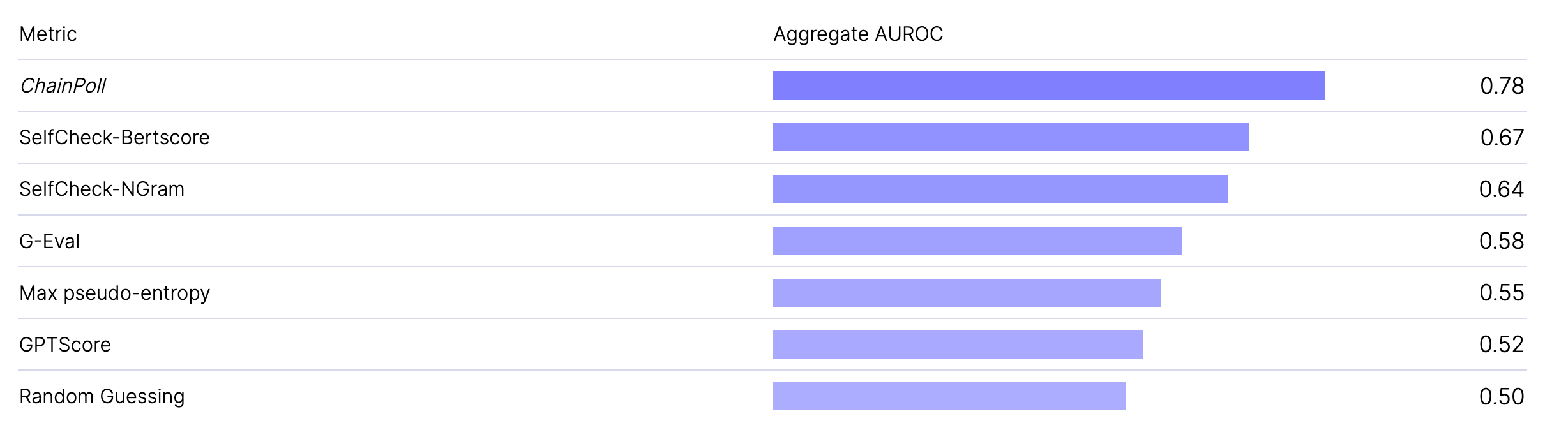
Derived from ChainPoll, this index applies 2 key metrics to reliably compare and rank the world’s most popular models on their propensity to hallucinate on the key task types.
- Correctness captures factual, logical, and reasoning-based mistakes, and was used to evaluate Q&A without RAG and Long-form Text Generation task types.
- Context Adherence measures an LLM’s reasoning abilities within provided documents and context, and was used to evaluate Q&A with RAG.
4. Backed by Human Validation
When an LLM hallucinates, it generates responses that seem plausible but are either undesirable, incorrect, or contextually inappropriate. Since reliably detecting these errors is hard and nuanced, this is not something you can just ask another GPT to do for you (...yet!).
Today, the most trusted approach for detecting hallucinations remains human evaluation.
To validate the efficacy of the Correctness and Context Adherence metrics, we invested in thousands of human evaluations across task types across each of the datasets listed above.
Results and Insights
The Index ranks LLMs by task type, and the findings were quite intriguing! In the realm of Question & Answer without Retrieval (RAG), OpenAI's GPT-4 outshines its competitors, demonstrating exceptional accuracy. In contrast, for Question & Answer with RAG tasks, OpenAI's GPT-3.5-turbo models present a cost-effective yet high-performing alternative.
The Index also underscores the potential of open-source models. Meta’s Llama-2-70b-chat and Hugging Face's Zephyr-7b emerge as robust alternatives for long-form text generation and Question & Answer with RAG tasks, respectively. These open-source options not only offer competitive performance but also significant cost savings.
With that, be sure to dig into the results and our methodology at www.rungalileo.io/hallucinationindex.
Going Forward
While we don’t expect teams to treat the results of the Hallucination Index as gospel, we do hope the Index serves as an extremely thorough starting point to help teams kick-start their Generative AI efforts.
And, we understand the LLM landscape is constantly evolving. With this in mind, we plan to update the Hallucination Index on a regular cadence. If you’d like to see additional LLMs covered or simply stay in the loop, you can reach out there.
Explore our research-backed evaluation metric for hallucination – read our paper on Chainpoll.
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
