HP + Galileo Partner to Accelerate Trustworthy AI
Pinecone + Galileo = get the right context for your prompts









Tl;dr: Galileo LLM Studio enables Pineonce users to identify and visualize the right context to add powered by evaluation metrics such as the hallucination score, so you can power your LLM apps with the right context while engineering your prompts, or for your LLMs in production.
Large Language Models (LLMs) have steamrolled into our collective consciousness, triggered a wave of creativity and ushered in a whole host of use cases to explore among developers, data scientists and industry leaders alike! This is not very dissimilar to the advent of mobile and the ease of application development – imagination was the primary limiting factor then, as it is now with LLMs.
As a part of the uptick in usage, a new LLM stack has emerged. A critical part of this stack is a vector database – a powerful way for LLMs to hook into the contextual memory of an organization and provide responses that are perfectly catered to its users.
For instance, without a vector database, if you asked an LLM (such as GPT-4):
“I lost my credit card and need a new one – how should I go about doing this?”
You would likely get a generic answer since most LLMs are trained on publicly available data on the internet. However, if you are building a chatbot for a specific Bank, you will need the LLM to hook into the bank’s unique knowledge base to uncover the specific unique steps needed to be taken.
Pinecone to the rescue
Pinecone is an immensely popular and powerful vector database that allows for quick retrieval of information for LLMs – this is critical when building LLM powered apps for specific use cases.
However, it can still be challenging to retrieve the right context from within the vector database – this is critical to avoid model hallucinations, and in general to ensure more accurate LLM predictions.
Using Pinecone with Galileo
To combat hallucinations, it is critical to identify and monitor the right context during prompt-tuning and in production.
Galileo provides the diagnostics and explainability layer by hooking into the LLMs and Pinecone to build better prompts, as well as ensure LLMs are leveraging the right context in production – it is a critical part of the LLM stack.

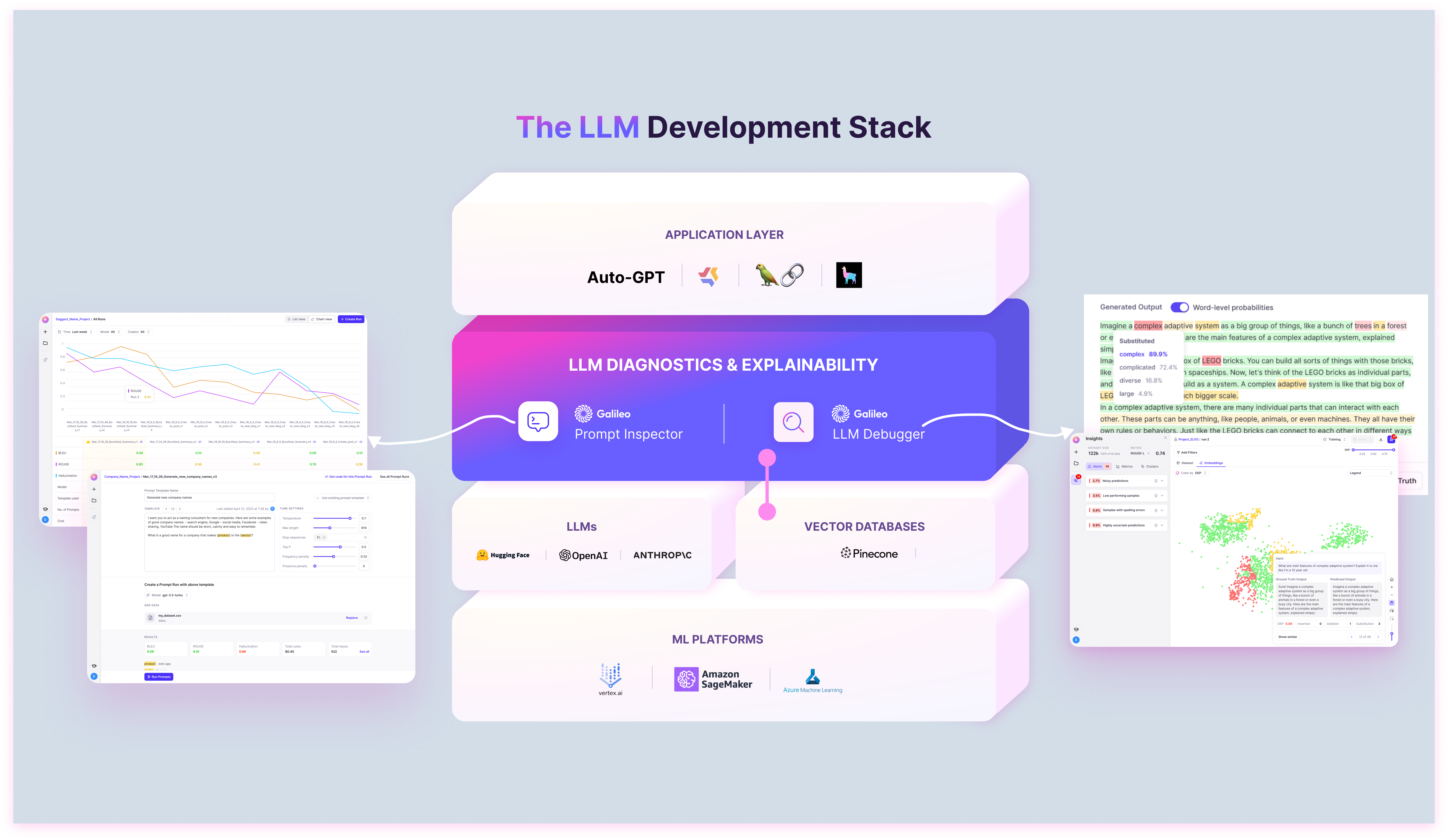
Overall, there are 3 key superpowers unlocked by using Pinecone with Galileo:
1. Identify the right context while engineering your prompts
A key use case of Pinecone with LLMs is for RAG (retrieval augmented generation). With Galileo’s Prompt Studio, you can enable prompts that expect context to be pulled from the top-k hits in Pinecone.
A canonical example of this would be building a Q/A system over a collection of podcasts. Since an LLMs fixed knowledge base does not include info about our podcast episodes, we need to provide the model with the context in the form of retrieval augmented prompt injection.
Generally how this works is, given a question "What was that story about Apple deciding to build the next self-driving golf cart?"
- Galileo would query Pinecone using the embedding representation of the question
- Take the top-k hits (ideally relating to the story about Apple)
- Include these as a reference in the prompt automatically.
2. Monitor your production LLMs to identify new context that needs to be added
Leverage Galileo’s Drift Detection algorithm and Pinecone’s embeddings store to find drift in production data! For users that do RAG, Galileo measures whether Pinecone contains relevant context for the queries the model is seeing in production or if it needs to be augmented.
This ensures that, as time passes, and the nature of prompts from your users start to diverge from the dataset available in the vectorDB as context, you can get alerted about this ‘drift’, and instantly see the prompts where the LLM couldn’t find sufficient context, and likely hallucinated.
3. Visualize and analyze context embeddings to identify the right context fast
Sometimes, it helps to simply see the context that is being added to your prompts, and tweak it! Galileo enables developers that store context embeddings on Pinecone to visualize them using Galileo.
Galileo provides an ‘intelligence layer’ atop these embeddings to, for instance, immediately surface the data the LLM struggled with powered by a host of evaluation metrics, including a powerful hallucination score.
Galileo’s LLM Studio is currently behind a waitlist and being used by a selective set of teams to build LLM powered apps they can trust in production.
In conclusion, the integration of Pinecone with Galileo unlocks three essential superpowers that enhance the effectiveness and reliability of language model systems. By leveraging Pinecone's retrieval augmented generation capabilities, Galileo enables the identification of the right context during prompt engineering, ensuring accurate and contextually relevant responses. Additionally, Galileo's drift detection algorithm combined with Pinecone's embeddings store allows for real-time monitoring of production LLMs, identifying the need for new context additions and mitigating potential hallucinations. Furthermore, Galileo's visualization and analysis tools provide developers with a fast and intuitive way to assess and optimize context embeddings, ensuring optimal performance and trustworthiness of LLM-powered applications. As Galileo continues to refine its LLM Studio and expand its adoption, it offers a promising solution for teams seeking reliable and high-performing language models in production environments.
The Galileo LLM Studio is free – join 1000s of developers in the waitlist here!
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
