All New: Evaluations for RAG & Chain applications
A Framework to Detect & Reduce LLM Hallucinations




Why Hallucination Matters?
Hallucination in LLMs (Large Language Models) refers to a phenomenon where the model generates text that is incorrect or fabricated. There are several reasons for hallucinations in LLM models, such as a lack of the model’s capacity to memorize all of the information, training data errors, and outdated training data. To get rid of hallucination we need to make the perfect model which can predict every token correctly. But we know it’s not possible right now.
Hallucinations can significantly impact decision making across various levels, for example, court cases or can impact a company's reputation, like what happened with Google’s Bard. It can result in private information being exposed based on the information the model has seen during the training. It can also lead to incorrect facts, and incorrect medical advice being given, as well as frustrating chatbot experiences.. For now, only time can tell if we will be able to achieve this, but till then we need to develop methods to detect and tackle hallucinations in LLM.


Framework for Detecting Hallucinations
Detecting hallucinations in AI-generated text is a complex task that cannot be approached with a one-size-fits-all solution. The efficacy of identifying these inaccuracies relies heavily on the specific workflow adopted by data scientists. The industry has begun harnessing LLMs with three distinct patterns: Prompting, Prompting with RAG (Retrieval Augmented Generation), and LLM Fine Tuning. Each of these approaches demand a tailored set of metrics to pinpoint and address hallucinations. In our previous post, we described different metrics which can be used for evaluating LLM output quality. Now let’s examine how to utilize them for reducing hallucinations.
Workflow 1: Prompting
Due to the versatile nature of LLMs, many use cases have come up where users rely on prompting LLMs for tasks like summarisation, code synthesis and creative writing. They often work great, but at times they surprise you with hallucinations. Hallucinations can arise due to many factors, and because LLMs are a black box it becomes difficult to figure out when and where models are hallucinating. Here we showcase ways to leverage scientifically proven metrics to detect and fix them.
Prompt perplexity
Why does it matter: Prompt perplexity is a good predictor of potential hallucinations. To recap, perplexity measures how confidently a model predicts a given text. A higher perplexity indicates a lower understanding of the text, meaning that the model is more likely to mis-understand the prompt.
Suggested action: Experiment writing the prompt in simpler language and with better structure.
Output uncertainty
Why does it matter: Uncertainty measures the confidence level of the model on the output token. A higher uncertainty indicates the model is not confident with its output.
Suggested action: Check the samples which have high uncertainty. Creative generations can have high uncertainty and are still acceptable. If high uncertainty is unexpected, reduce temperature and reduce top k in order to increase chances of selecting higher probability tokens. However, if these do not work you can experiment with different prompts.
Factuality
Why does it matter: Factuality leverages GPT-3.5 to check for factual errors. A factuality of 0 indicates the potential hallucination while a value of 1 means no hallucinations..
Suggested action: Add instructions in the prompt which would ask it to be truthful. Reduce the temperature and top k in order to increase chances of selecting higher probability tokens which might reduce hallucinations.
Workflow 2: Prompting with RAG
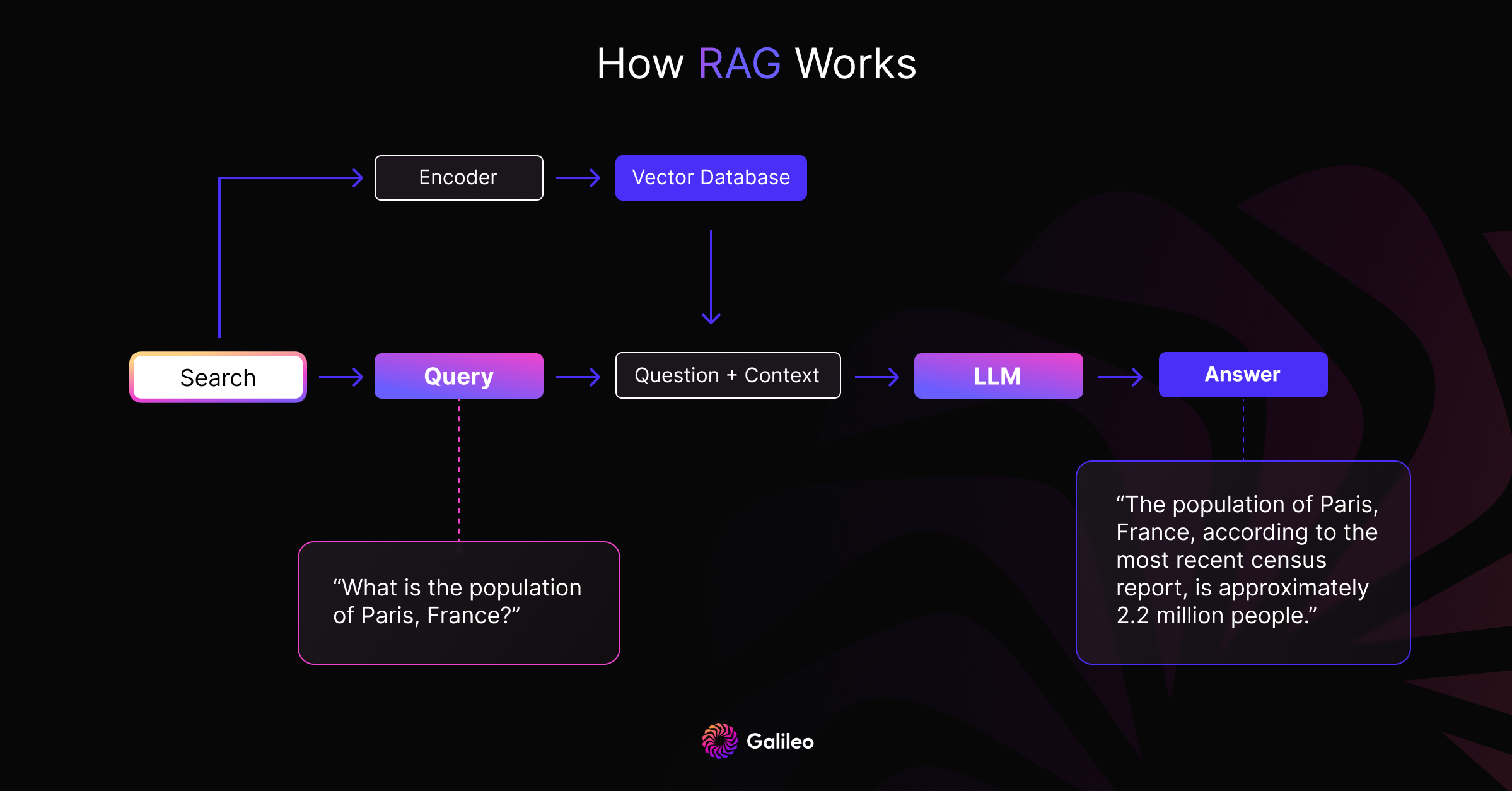
Updating LLMs with new knowledge is notoriously difficult. However, as a work around, we can directly provide models with the latest / most relevant domain knowledge (retrieved from a search engine) as context to help in completing a task. An example of such a task is a question answering system. Unfortunately, even when presented with relevant context (or especially if given irrelevant context) LLMs can still provide out of context information i.e. hallucination. Here are some metrics we can use to address this:
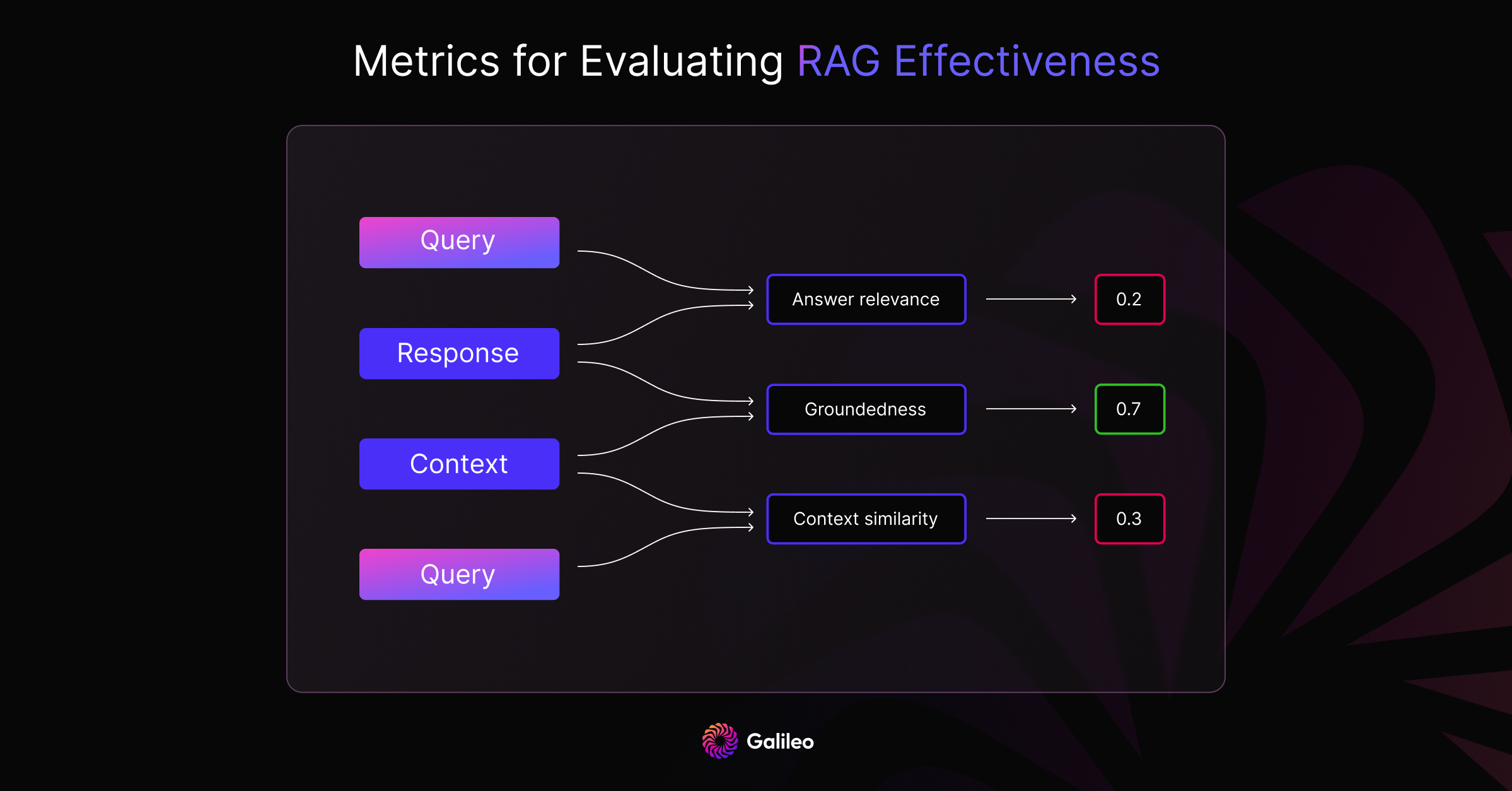
Context similarity
Why does it matter: Context similarity measures how relevant the context is for the question. Low context similarity can indicate wrong context which can lead to hallucinations.
Suggested action: Experiment with different indexing parameters of your retrieval system.
Vector DB params - text encoder, chunk size, chunking technique
Query params - semantic cutoff
Reranking - reranking model, reranking cutoff
Hybrid search (leveraging both full text and semantic search) is often used to overcome limitations of semantic search.
Answer relevance
Why does it matter: Answer relevance measures whether the generated response answers the question. A low relevance indicates potential hallucination.
Suggested action: Check if the context contains the answer to the question. To handle cases where there is not enough information in the context, add some instruction asking the model to answer with “I don’t know” or “there is not enough relevant information to answer the given question.”
Groundedness
Why does it matter: Groundedness checks if the generated response is based on the context provided. A score of 0 means there is a presence of hallucination. It is possible that the response answers the question but is incorrect with respect to the context. In such cases, answer relevance will fail to catch hallucinations, but groundedness will.
Suggested action: Add instructions in the prompt to answer based on the context provided only or else say “I don’t know”.
Workflow 3: Finetuning LLM
We need to fine-tune LLMs for tasks which require new capability, high performance or privacy. Recent works like LIMA: Less Is More for Alignment, Deduplicating Training Data Makes Language Models Better & The Curse of Recursion: Training on Generated Data Makes Models Forget indicate we can get a better LLM by fine-tuning on high quality smaller data instead of a larger noisy data. Here is how we can leverage metrics to get a high quality dataset.
DEP (Data error potential)
Why does it matter: DEP is a special metric developed by Galileo which tells us potential error in the ground truth text. These errors can confuse the model during training which can lead to hallucinations in inference.
Suggested action: Filter samples where DEP score is high. Then you have 2 paths. You can reannotate all of them and retrain to get a better model. Or you can drop these problematic samples to get a better model.
Do We Need a Human in the Loop?
It is crucial to recognize that although we do have metrics for identifying hallucinations, none of them are perfect. Certain techniques may prove inadequate for tasks that lack a single correct answer, such as creative endeavors. To ensure accuracy in critical applications, it's essential to have annotations tailored to the specific task at hand. Companies should conduct experiments to determine metrics which align most closely with their human annotations and then judiciously use these metrics to minimize human annotation.
At Galileo, we've invested years in crafting algorithms to spot data errors. As a result, we've seamlessly incorporated these metrics into our LLM studio. This empowers our users to experiment with different prompts and model settings, finding the best match for their needs. By utilizing these metrics and suggested strategies, you can systematically reduce instances of hallucinations in your AI outputs.
Explore our research-backed evaluation metric for hallucination – read our paper on Chainpoll.
Galileo LLM Studio is the leading platform for rapid evaluation, experimentation and observability for teams building LLM powered applications. It is powered by a suite of metrics to identify and mitigate hallucinations. Join 1000s of developers building apps powered by LLMs and get early access!

Working with Natural Language Processing?
Read about Galileo’s NLP Studio
