HP + Galileo Partner to Accelerate Trustworthy AI
🔭 What is NER And Why It’s Hard to Get Right





In a previous post, we discussed how one can use Galileo to improve text classification models in minutes with data intelligence. In this post, we discuss the Named Entity Recognition (NER) task, why it is an important component of various NLP pipelines, and why it is particularly challenging to improve NER models.
A Primer on NER
In text classification, every sample is classified into a label category. Take, for example, classifying news articles. There may be four label categories (classes), Politics, Geography, Technology, and Humor. For each sentence, the model categorizes it into one (and only one) of those categories.
Under the hood, the model first encodes a representation of the sample, and then uses a classification layer to produce a probability distribution over those categories.
NER is a more nuanced form of classification, where each word (or words) in a sample is potentially classified into one of the label categories. Each classified word(s) is called a span. As such, NER is a form of sequence tagging where, given a sample, the model identifies various spans by predicting their span boundaries (the start and end index of the word(s) of interest) and classifying each into one of the label categories.
Let’s take a simple news article example. Given the following input sentence, listed are the outputs for a text classification model and an NER model:
Input: “Barack Obama recently visited the White House”
For a Text classification Task
Output: Politics
For a Named Entity Recognition Task
Output: “Barack Obama” (characters 0-12) = PersonOutput: “White House” (characters 34-45) = Location
Notice that the NER output has multiple labels (spans). In theory, the number of spans is limited only by the number of words in the input sentence. This is an explosion of potential tasks when compared to text classification.
NER is a very important upstream component because it supports real-world applications like conversational agents, information retrieval, question-answering, summarization, relation-extraction and many more. That is, it is often an early step in a multi-stage pipeline, with many downstream tasks consuming its outputs. Therefore, it is crucial to ensure robust NER systems that do not propagate errors to dependent applications.
The State of NER today
As you may expect, collecting NER data for custom entities is extremely time consuming, and often requires domain experts. Due to limitations in the training data, NER systems are often combined with additional rule-based features like part-of-speech tags or case-capitalization. Recently, with the rise of foundational models, fine-tuning pre-trained language models on custom data is also becoming increasingly common.
Why NER is challenging
The black-box nature of NER models makes introspection and generalization efforts particularly difficult. Finding frequent words that are causing span errors, surfacing consistent annotation errors, and other similar insights are challenging but extremely high ROI tasks to fix and improve the model’s long-term performance.
1. Data collection and annotation is expensive
Entity words (spans) in a sample are relatively sparse, with an average of about 1-2 spans per sample, creating a non-linear relationship between samples and spans. As a result, many samples must be annotated to build a generalizable system. Adding to the complexity, samples should have both varied distributions of spans and sentence structures to yield stronger models. Due to the nuance and challenge of data mining and annotation, subject matter experts often disagree as to the correct ground truth label.
2. Many error types
NER tasks can contain a wide variety of errors for any given prediction, making error analysis more challenging. A misclassified span could be a result of any number of errors:
- Incorrect span boundary prediction (span is “Barack Obama” but model predicts “Obama”
- Incorrect span label prediction (label is “Politics” but model predicts “Economics”)
- Span hallucination (model predicts a span that is not labeled)
For each of these errors, time must be spent to determine if the model is making a mistake, or if there was an annotation error, and the root cause of each. Additionally, there does not exist a single metric to benchmark NER systems. Careful considerations must be made when deciding the metrics for a given task. For example, getting the class correct could be a higher priority than getting the span boundaries correct, or a higher recall might be more relevant to the downstream task. If these metrics and error insights are readily available, one can significantly improve the process of building NER systems.
3. Semantic overlaps across classes
Because NER systems are more granular than text classification, semantic class overlap becomes a larger challenge, leading to inconsistent annotations and ill-defined class hierarchies. Annotation mistakes of this kind are particularly problematic as they directly affect the model’s ability to learn clean decision boundaries.
4. Compute cost
Finally, due to the complexities listed, NER systems require more sophisticated models, and take longer to converge, increasing GPU costs with subsequent runs.
What's next?
At Galileo, we are excited to be pushing the boundary of NER. We believe our tool addresses many of the challenges discussed above, and is the first-of-its kind, data centric approach to surfacing and fixing error patterns in NER, leading to highly efficient model iterations.
We abstract problems around non intuitive data structure and tagging schemas that can lead to slower EDA processes for the users. Because NER predictions are at the word level, generic sentence embeddings are not sufficient for model representation. Galileo solves this problem with specialized embeddings and visualization techniques for granular insights.

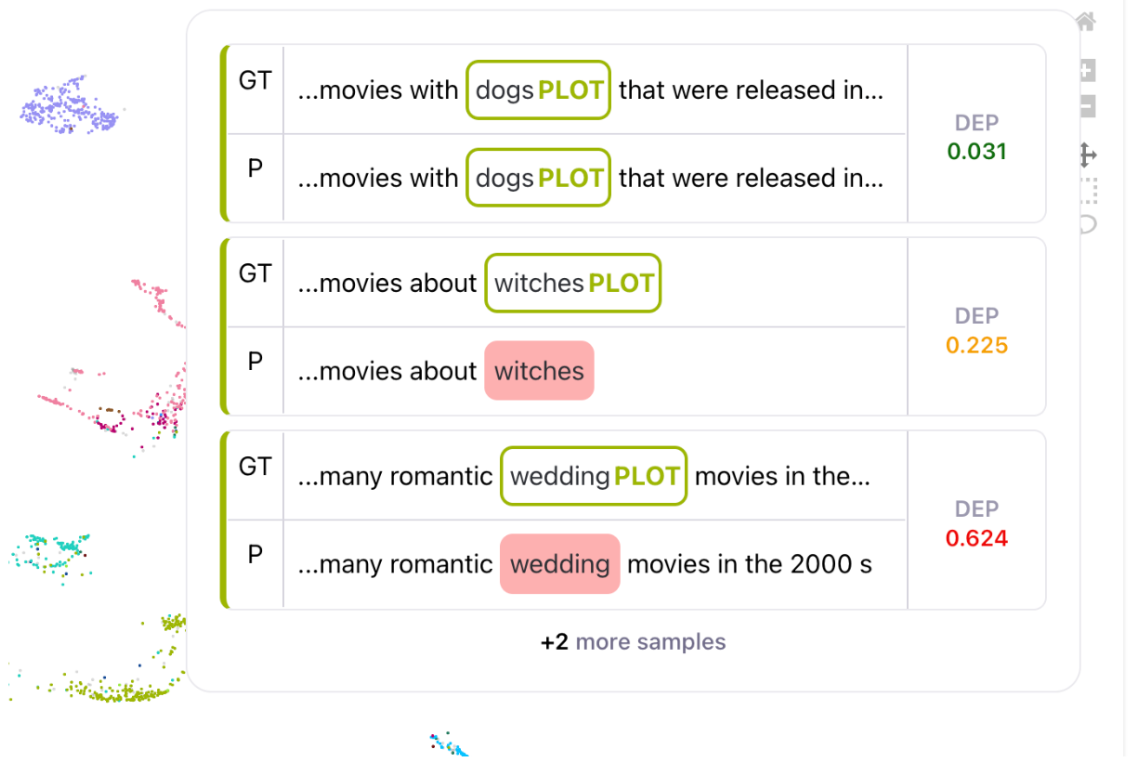
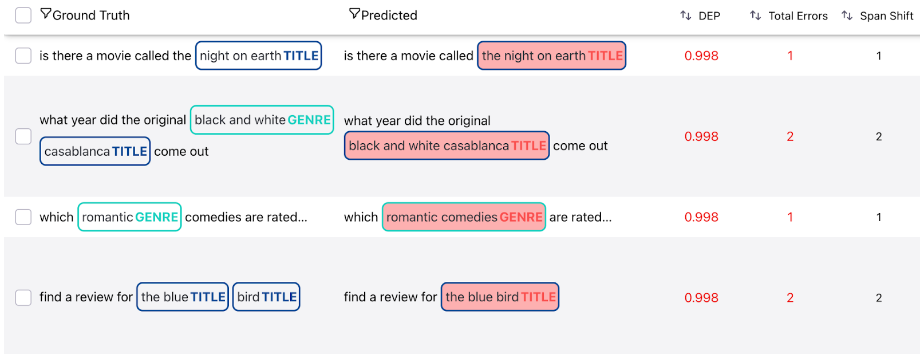
Finally, Galileo reduces the black-box nature of these systems by surfacing various weak regions of the model with respect to both spans and words. This can help pinpoint high value samples for the next model iteration to achieve maximal performance lift. Stay tuned for our next blog on how we use Galileo for MIT movies dataset and quickly fix errors to provide significant performance improvements in an NER system.

To follow along, subscribe to our blog or join our Slack channel
Also, we’re hiring across ML, Platform and a host of non-engineering roles and would love to chat with you if you’re interested!
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
