HP + Galileo Partner to Accelerate Trustworthy AI
Galileo + Google Cloud: Evaluate and Observe Generative AI Applications Faster




Successfully leveraging generative AI at enterprise scale requires the right guardrails (e.g. for data leakage, PII, LLM confusion detection) to reduce the risk of LLM hallucinations and low quality outputs.
We’re excited to announce that all Google Cloud users can now leverage Galileo’s algorithm-powered evaluation, experimentation and observability platform to build trustworthy AI applications!
The Evaluation Problem in Generative AI Application Development


Problem 1: Lack of effective LLM input and output evaluation metrics
With NLP, the F1 score, precision, and recall were reasonably effective metrics to determine model quality. With LLMs, those metrics do not apply. Instead, given these are sequence-to-sequence models, metrics such as BLEU and ROUGE can be used, but there are two problems here:
- These metrics need ground truth data, which might not be easy to procure, especially while prompt engineering.
- These metrics do not have a way of measuring semantic meaning and instead focus on syntactic structure, over-penalizing similar outputs that are differently worded (e.g. synonyms) than the ground truth.
To effectively evaluate LLM inputs (prompt quality, vector context quality, data quality) and LLM output (factuality, uncertainty, context groundedness) AI builders need a dedicated set of specialized metrics.
Problem 2: Lack of effective experimentation tools
When experimenting with dozens of prompts, parameters and LLMs, we quickly run into a lot of runs. Effective comparison of these runs is hard to do in python notebooks such as Colab or Google Sheets (often the tools of choice today) since they are not optimized for rapid, collaborative identification of the right combination of inputs.
Problem 3: Lack of effective generative AI application observability
With generative AI applications, traditional application observability solutions can be helpful, for instance to track logs, downtimes, latency, etc. But generative AI also has embeddings, vector context, and can hallucinate in production. Thus, effective generative AI application observability would need to solve these needs for AI teams, as well as provide effective feedback loops to tweak the prompt or the data.
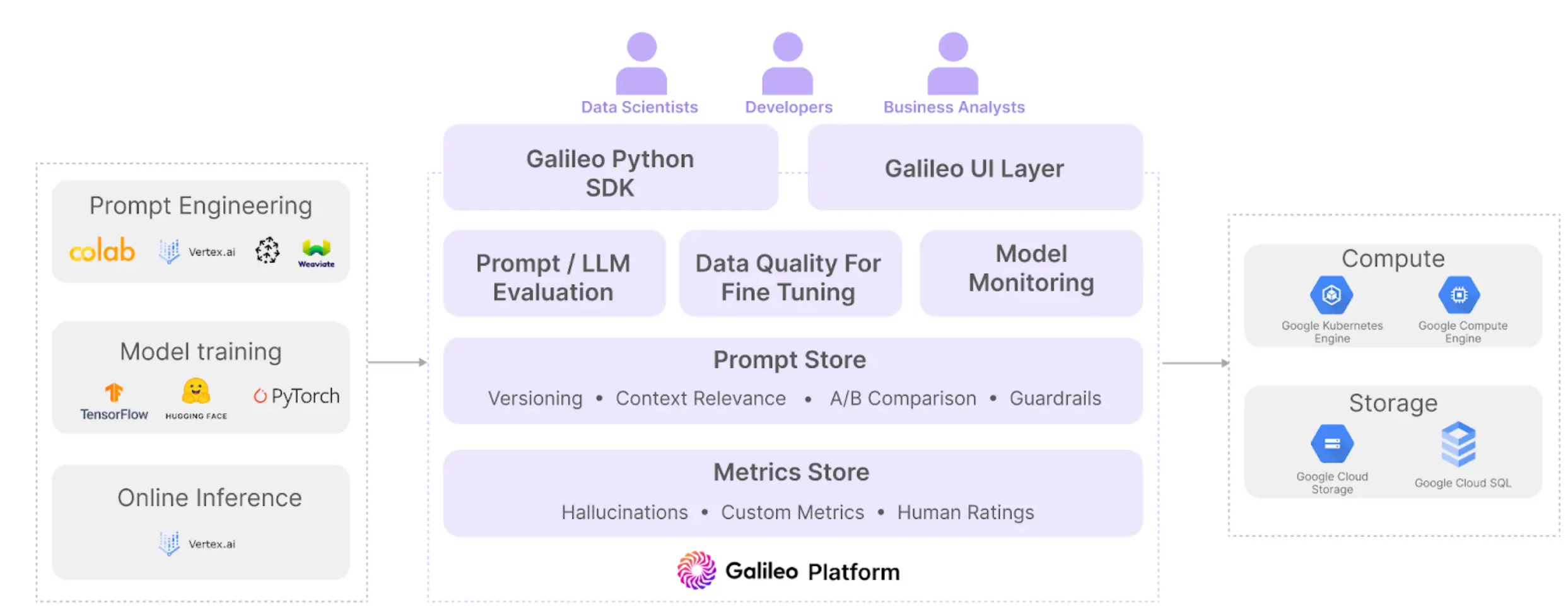
How Galileo on Google Cloud helps LLM Developers
Google Cloud provides both advanced data infrastructure and industry-leading services for building and running generative AI applications. Galileo provides the end-to-end platform for generative AI evaluation, experimentation and observability, so you can build your applications on Google Cloud faster while mitigating risks of hallucinations.

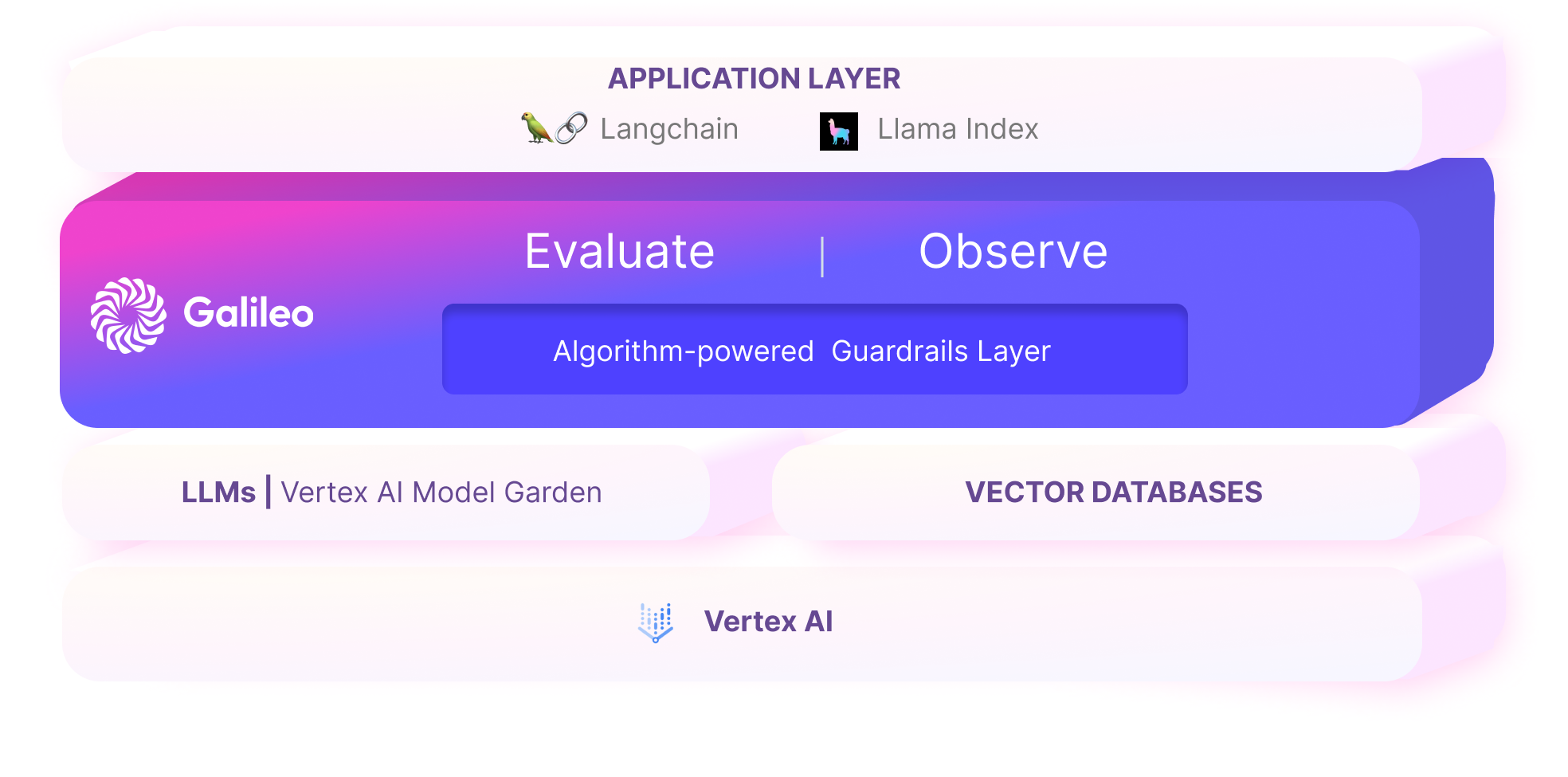
Solution 1: Evaluation metrics to detect LLM hallucinations
The Galileo research team has built a suite of LLM evaluation metrics that detect the likelihood of hallucinations in the LLM output, both when the user is not using RAG (LLM Factuality) as well as when using RAG with Vertex Vector Search (LLM Groundedness).
Moreover, for fine-tuning, data quality is critical. The Data Error Potential metric quantifies how hard it was for the LLM to learn on each token in the ground truth. Apart from these metrics, users can easily create their own custom metrics leveraging Galileo’s python client.
Together, these guardrail metrics can be used to provide explainability and move uplevel LLM evaluation for AI teams.
(Check out our LLM Hallucination Index to see how different LLMs rank for their propensity to hallucinate across 3 different task types!)
Solution 2: Platform for rapid experimentation
Building generative AI applications requires careful investigation across a combination of prompts, parameters, vector context and LLMs. Galileo provides techniques such as Prompt Sweeps, A/B/n testing and a Prompt Editor built for iterative experimentation. These, combined with the evaluation metrics described above help AI teams accelerate their prompt engineering and LLM fine-tuning experiments.
Solution 3: Generative AI Application Observability
Despite the best guardrails being in place, and the highest quality data leveraged for fine-tuning, models need constant observability once in production. Apart from system and business metrics such as latency, cost and API failures, generative AI apps need specialized observability for hallucinations, embedding clusters, chain failures and more. Vertex AI users can now leverage the power of Galileo’s purpose-built LLM observability to not only proactively get alerted, but also take immediate action by fixing the prompt or adding the right data to further fine-tune with. Building these strong feedback loops is essential for building effective generative AI applications.
Built with Google Cloud

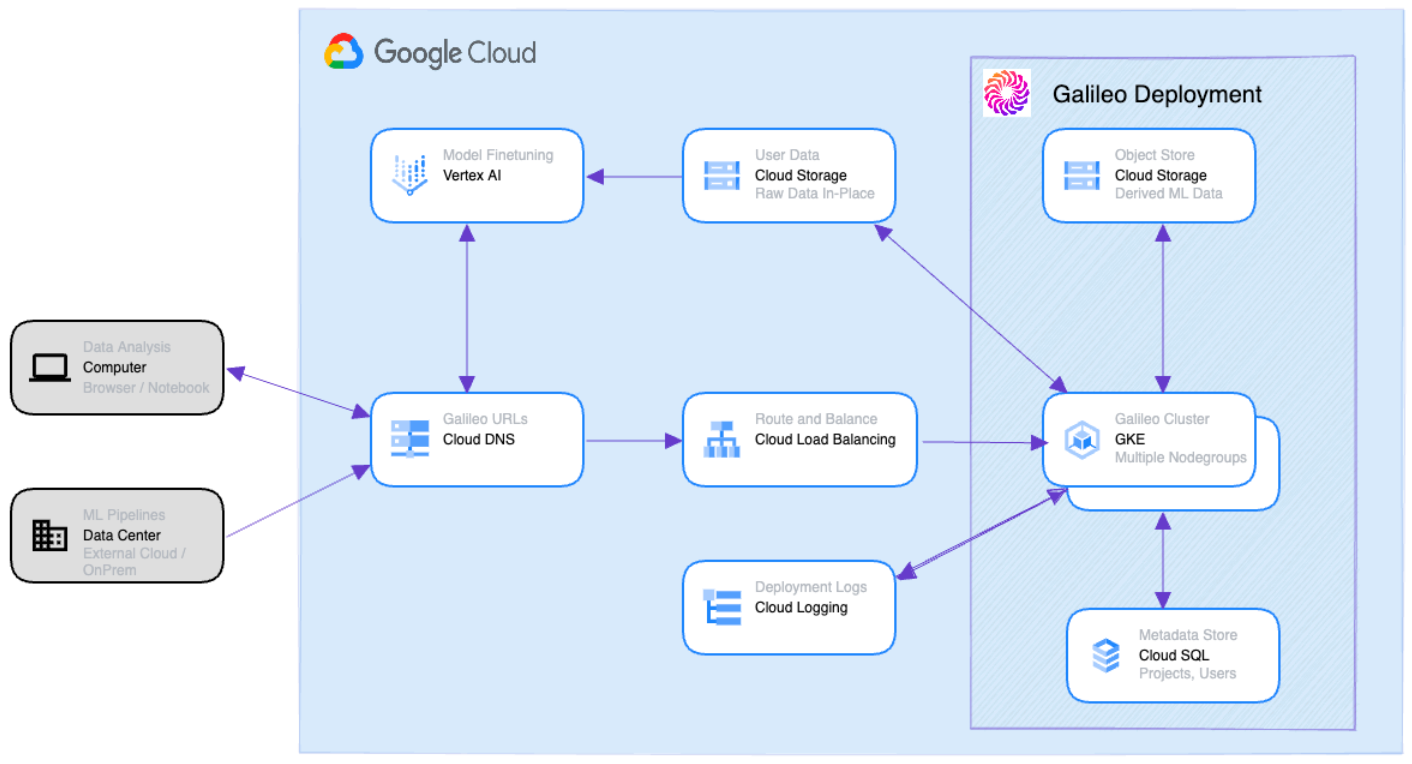
Galileo runs seamlessly and efficiently with managed services on Google Cloud Platform (GCP). While Google Cloud Storage and Cloud SQL serve as the storage backbone of our scalable, low-latency services running on the Google Kubernetes Engine (GKE), Vertex AI is the perfect ML development environment for integrating Galileo into our user’s model training, evaluation and serving pipelines.
In addition, Galileo’s powerful algorithms are built on top of Vertex AI as well as GCP’s compute platform. This allowed our research teams to expedite and automate large-scale experimentation and develop industry-first LLM evaluation metrics.
Moreover, building a world-class product requires a lot of testing. The powerful APIs offered by Vertex AI enabled faster internal testing and led Galileo to develop an AutoML platform that runs thousands of training and inference runs daily.

Galileo on Google Cloud provides an evaluation-first platform for rapid evaluation, experimentation and observability while building generative AI applications. Leveraging Galileo with Google Cloud can help AI teams mitigate LLM hallucinations, ensure compliance guardrails are in place, and accelerate application development.
With Galileo, Google Cloud customers can ensure they work with the right prompts, the right context from their vector database, high-quality data, and can monitor their LLMs in near real-time. Watch the demo now!
Get started with Galileo today!
Subscribe to Newsletter
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
