Fixing Your ML Data Blindspots




Featured image courtesy of DALL-E image generator
Over 90% of the world's information is unstructured today and growing incredibly fast. According to some estimates, it grows at a rate of 55% to 65% per year. As deep learning techniques become more common and commoditized, businesses are increasingly starting to use this data to build new AI-powered applications.
Many of the key challenges today are not from the sophisticated algorithms that have been proven to generalize well across a variety of real-world modeling tasks and data domains, but mainly from the quality of the unstructured data itself.
This article highlights the different blind spots and challenges large and small data science teams face, as well as possible recommendations to address these issues.
Understanding the Challenges in Machine Learning Workflows
When working on machine learning (ML) projects, the challenges are usually centered around datasets in both the pre-training and post-training phases, with their own respective issues that need to be addressed.
During the Pre-training Phase
When curating a dataset, you will notice that effective data scientists generally have a very strong intuition about the domain and the data, more so for unstructured data domains. The reason is that you need to understand the nuances of the different data sources, data characteristics (sample-length, noise, outliers, confusing edge-cases, etc) and dataset curation strategies (e.g., performing data perturbation to achieve model robustness or fixing basic imbalances / lack of coverage in data distributions).
Many nuances come into play with the data itself during the pre-training phase when curating, exploring, and processing a dataset. It takes a few iterations and creative thinking to get your datasets to a point where it could maximize our model’s robustness in production.
In this phase, the main issues are:
- Curating well represented datasets.
- Lack of domain expertise.
Curating well represented datasets.
Curating your datasets often tends to be more than just sampling data uniformly across labels. You want to identify the necessary features to cover because unstructured data has a lot of variation. These can include different characteristics specific to your domain—for example, within speech recognition datasets, you want many different speakers with varying accents, so it's not just about what is said, or how long the audio is, but how many speakers and in what background environment each sample was recorded in. Once you understand this, you can curate your dataset better.
During this phase practitioners apply many ad hoc methods to really tease out the necessary characteristics to focus on. Unlike structured data where we can look at feature importance in a dataset, there are no predefined features in unstructured data.
Lack of domain expertise.
Finding and hiring domain experts with years of experience in the specific data that their models need to train on takes a lot of work. This makes it difficult for ML teams working on curating and understanding the dataset to truly understand potential errors (like hidden biases) that could degrade the quality of the training data.
Domain expertise also tends to be important when identifying our model’s expected behavior, annotating data and once we have a model, triage and fix long-tail errors and edge-cases where the model’s predictions may often be uncertain.
During the Post-training Phase.
Nowadays, deep learning algorithms are packaged in libraries and treated as a black-box compared to a decade ago, when people with PhDs in data science at the time had a lot of experience implementing neural network algorithms from scratch and training them. There was a magnitude of extra understanding of the math under the hood, although it's not a prerequisite now. While most of us are really applying commoditized models to our own application domain, without a deeper understanding of the model, we are often left with exploring ad-hoc methods to debug our models and try to extract the most performance from the model by fixing issues in our datasets.
Often enough, if there were issues with model performance after the training, data scientists would typically focus mainly on tuning the model to improve its performance. But now that there are many tools that automate model parameter optimization like Google’s Vizier, NNI, Optuna and more; the focus is on improving the quality of the training data.
Most of the work in debugging models goes into finding and fixing our dataset errors to eliminate the model's blind spots. To fix the training data, you have to look for "unknown unknowns" that are causing your model’s performance to be poor in specific scenarios.
In the past six months at Galileo, we've spoken to 100s of ML teams working with unstructured data with a universal message that this phase is where data scientists spend the most of their time these days. And this anecdotal evidence also points to the overwhelming statistic that more than 80% of their time spent today is just trying to debug their model performance and understand issues in their data sets.
Some of the issues we find here are:
Sampling errors.
You're missing out on a few nuances in the data set and would probably need to augment it with noise and different variations of the data.
These errors can be identified by performing coverage analysis on your held-out evaluation set, compared to your training dataset.
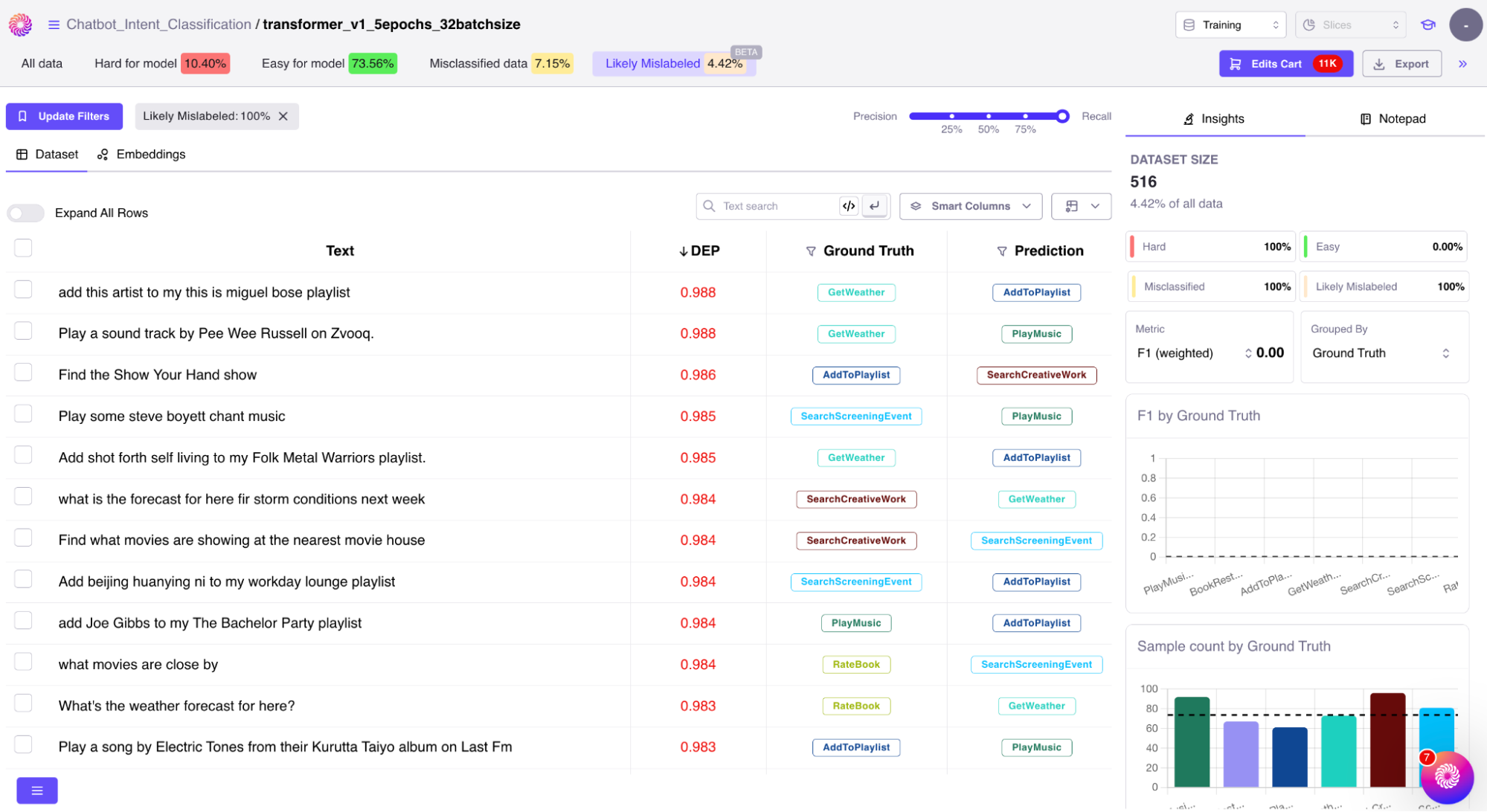
Data annotation errors.
Unstructured data heavily depends on human annotations. With humans involved (even with subject matter experts), there is always a significant error potential. Since models are completely dependent on the annotations, this can be a source of some serious misprediction once you train your model.
Finding and fixing these errors is a typical needle in a haystack problem. Data scientists often have to run custom experiments or examine the raw data themselves to validate these errors.
There are a few recent advancements in algorithms that can accurately detect these annotation errors. Galileo provides out of the box solutions to surface these errors using state-of-the-art techniques. Leveraging such tools can not only save our time when dealing with such errors but also prevent disastrous mispredictions in production by proactively fixing them instantly while we train our models.

Data freshness and relevance.
You need to make sure your test sets are relevant and that your model performs well on it. If it's not, you may have to return to your training set again and ensure it has the necessary samples to ensure everything is clear.
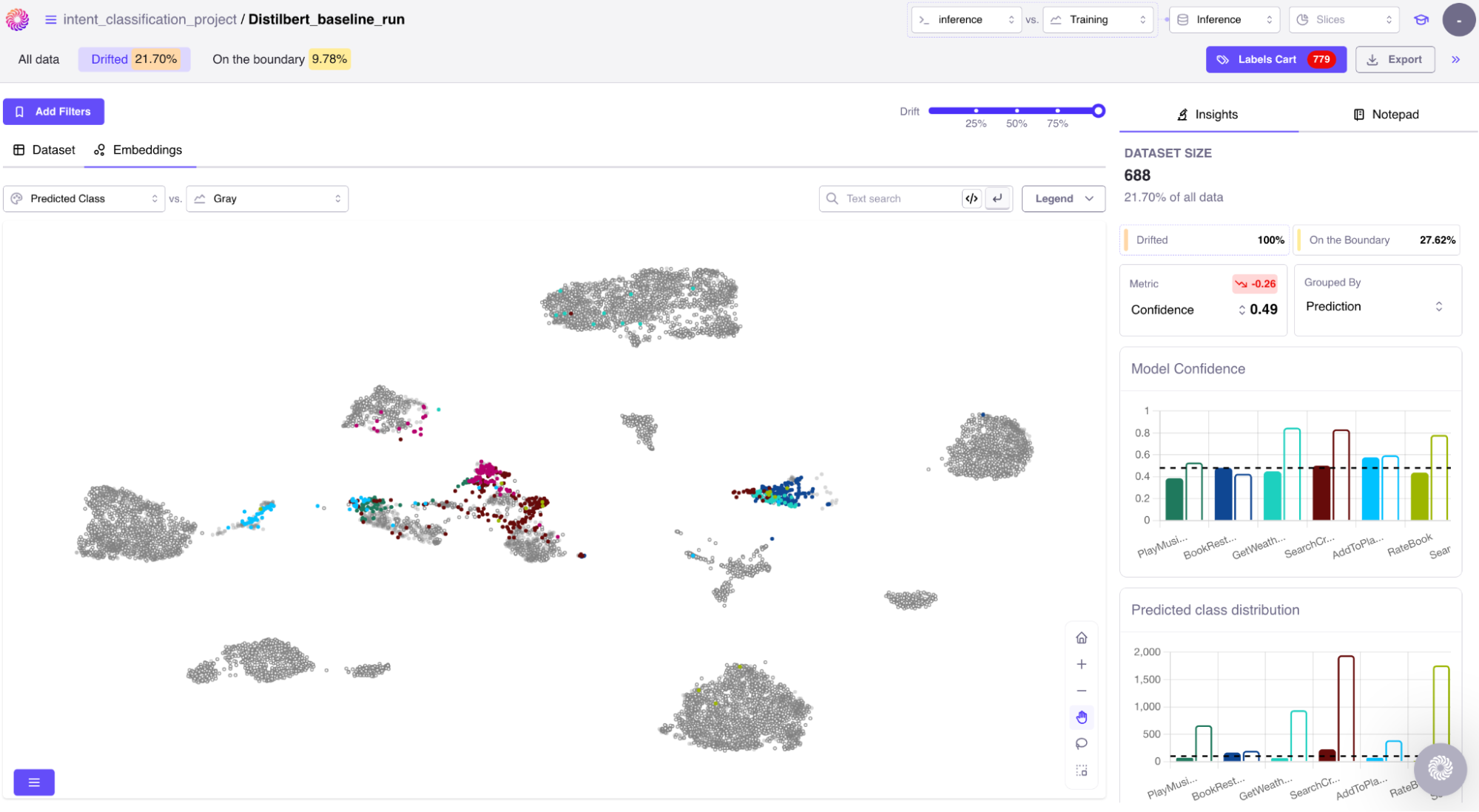
Semantic shifts in the unstructured data.
As the real world keeps changing constantly, we need to be proactive in detecting and fixing drift in our datasets. There's a concept of semantic drift in unstructured data that is hard to detect. It's essential to keep your models fresh to be able to perform optimally in production, and you can’t really do this at scale without tooling and automation that help detect drift and promptly act on it to kick-off a training run that delivers a fresh, high-performing model to production. It is costly and slow to resample and relabel cohorts of production data every month or on a regular cadence, meaning teams must have an effective workflow or automation built around it to scale.
Galileo has developed extremely effective algorithms to surface only those data points from production that must be added to your dataset, which have a very low propensity to cause regressions on existing use cases that your model already serves very well.

Challenges in the Productionization Phase
Inadequate model maintenance in production.
ML teams often don’t have the capacity to manage many use cases at a time, and once a model is launched there is very little upkeep and they move onto the next project. Teams often even just set up semi-regular model and dataset refresh cycles that are just too far out, slow and costly for the team to then figure out and fix performance regressions on the refreshed model in order to refresh the current one in production.
Need for standardization across large teams.
When it comes to large teams especially, they are often working on several models, with hundreds to thousands of experiments running, but it's still ad-hoc. Everyone runs custom Python or SQL scripts on the data, looks at data dumps on their own, and then comes up with metrics and insights that only they have discovered. This causes a standardization problem where only some may perform the comprehensive set of analyses needed, with no code reviews in place on their experiments. This is the primary reason for embarrassing bugs to slip through the cracks!
Recommendations
Most of the challenges you have seen throughout the article can become blind spots for big and small companies alike, but they can be worked on with the following considerations:
Leveraging datacentric tooling to get actionable insights proactively.
With limited time and resources, small teams need to adopt data-specific tooling that can give them instant, actionable insights into issues with their data and models (both pre-training and post-deployment). You don't have to run days or weeks of experiments to get to these insights, and the tool can often provide them proactively rather than having them jump around and shift focus.
Automation is key.
Leveraging tools that can help you automate the error analysis part, every step of the way in your model’s life-cycle can go a long way in allowing you to focus on building and launching better ML applications faster, since this is the part that takes up most of our time today!
Galileo brings Data Intelligence to Machine Learning
Today, Galileo is being used by startups as well as Fortune 500 companies, with ML teams of all sizes. Galileo focuses on delivering actionable insights to you, where you're trying to find errors in your data during model training and experimentation, as well as once you have productionized your model. The most significant advantage of using Galileo is to proactively find and fix errors in your datasets instantly, whether you are just starting out experimenting with a model, or even when your model is already in production!
We also see more advanced teams with models in production now starting to build out active learning pipelines, to keep their models fresh in production. Galileo helps them figure out which new samples to annotate and add to their data set to keep their models performing optimally in the real world. When they integrate Galileo into their production stack, they are automatically notified when it is time to initiate a refresh cycle, rather than being negligent or to set take up model refreshes on an ad-hoc basis.
If you want to try Galileo out for free, sign up here.
----
Catch my full talk on YouTube.
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
