[Webinar] 5/15 – See Galileo Protect live in action 🛡️
Generative AI and LLM Insights: February 2024


Table of contents
- Evolution of Models at Pinterest
- NeurIPS 2023 Recap
- Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs
- Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM
- Fundamental LLM Courses
- A Living Catalog of Open Datasets for LLM Safety
Blending can help smaller models pack a bigger punch, and while self-attention mechanisms are critical to LLM architecture, do you actually understand how they work? Check out our roundup of the top generative AI and LLM articles for February 2024!
Evolution of Models at Pinterest
Pinterest has 480 million monthly active users! The ML team had to experiment with, iterate, and launch several state-of-the-art model architectures to serve all of them. Take a technical deep dive into the team's approach to this model evolution: https://medium.com/pinterest-engineering/evolution-of-ads-conversion-optimization-models-at-pinterest-84b244043d51

NeurIPS 2023 Recap
Explore some of the top topics from NeurIPS, including Word2Vec evolution, emergence mirage, direct preference optimization, Mamba's linear-time modeling, and more: https://www.latent.space/p/neurips-2023-papers


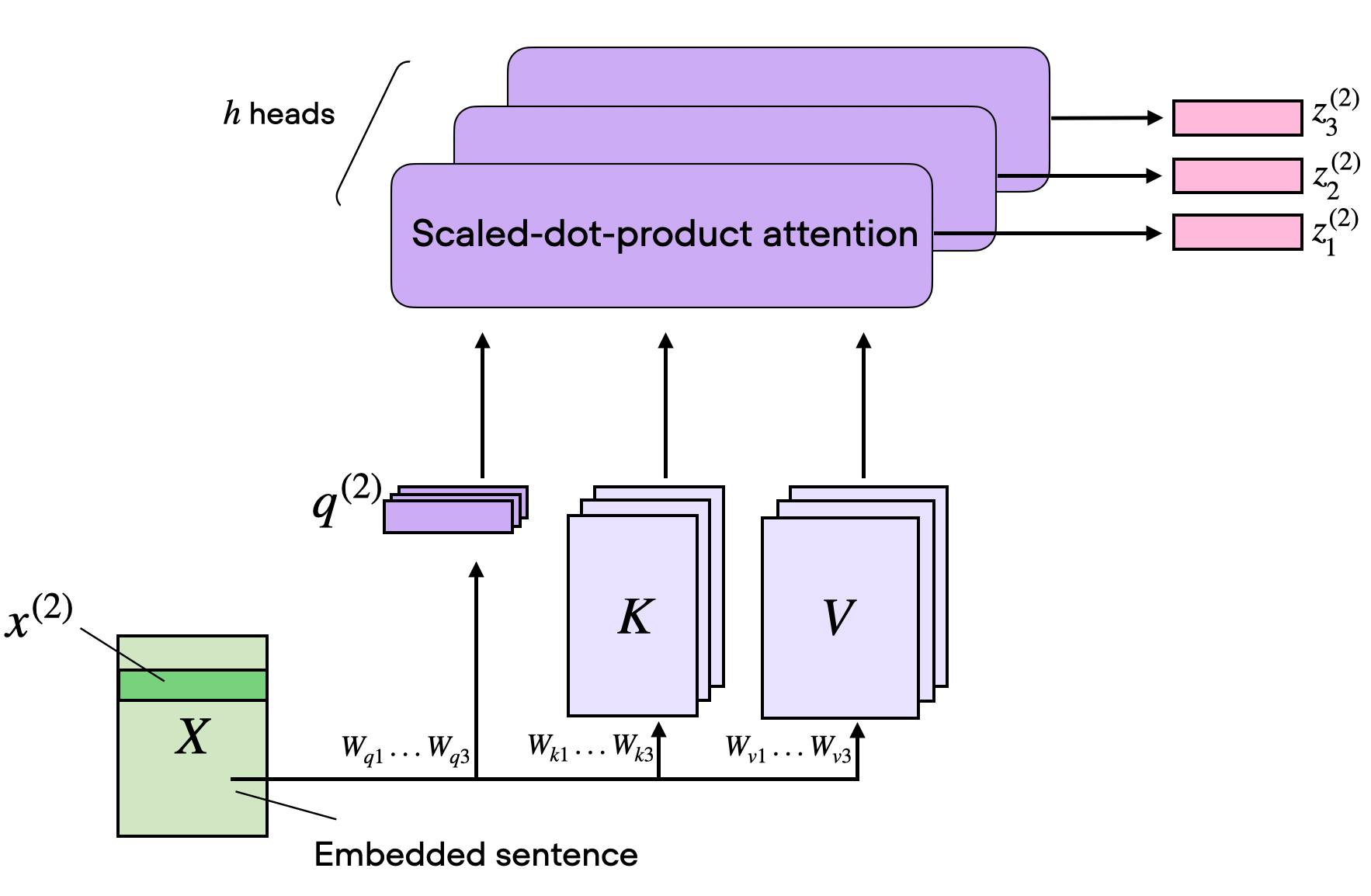
Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs
Pop quiz: What's the difference between multi-head attention, cross-attention, and casual-attention in LLMs?
Whether you're using GPT-4, Llama 2, or most other LLMs, they all rely on self-attention mechanisms as a critical component of their transformer architecture. Learn why they're important and how they work: https://magazine.sebastianraschka.com/p/understanding-and-coding-self-attentio

Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM
Can a team of smaller models defeat a singular large model?
With massive LLMs costing more and more to operate, demanding tons of energy, maybe going smaller is the key! Researchers have found integrating just three moderate-sized models (6B/13B parameters) can outcompete ChatGPT and its 175B+ parameters: https://arxiv.org/abs/2401.02994


Fundamental LLM Courses
Explore in-depth courses on LLMs, covering fundamental concepts like fine-tuning strategies, quantization techniques, and inference optimization.
The curriculum includes the fundamentals for scientists and engineers, such as Mathematics for Machine Learning, Python for Machine Learning, Neural Networks, and NLP. Dive into the GitHub repository now: https://github.com/mlabonne/llm-course


A Living Catalog of Open Datasets for LLM Safety
Evaluating LLM safety is a critical part of the generative AI app development lifecycle. Use these 74 open datasets purpose-built for safety: https://safetyprompts.com/


Better safe than sorry.
Table of contents
- Evolution of Models at Pinterest
- NeurIPS 2023 Recap
- Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs
- Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM
- Fundamental LLM Courses
- A Living Catalog of Open Datasets for LLM Safety
Subscribe to Newsletter
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
