[Webinar] 5/15 – See Galileo Protect live in action 🛡️
Being 'Data-Centric' is the Future of Machine Learning




Featured image courtesy of DALL-E image generator
Machine Learning is advancing quickly, and some patterns have emerged! In this blog, we will review the state of ML today, what being data-centric means in ML, and what the future of Machine Learning is turning into.
The State of Machine Learning
Machine Learning today drives critical decisions across key business verticals and is increasing at an extraordinary pace year over year. From self-driving cars, movie recommendations, and fighting fraud, all the way to advanced question-answering systems using Generative Models. The number of ML Engineers is growing at a rate of 70+% each year, similar to a pattern we saw during the rise of application developers in the early 2010s.
Today, we're hitting an inflection point in Machine Learning in terms of validation and practical applicability. That said, we're still in the very early days and are yet to see ML applied in full bloom to products and industries.

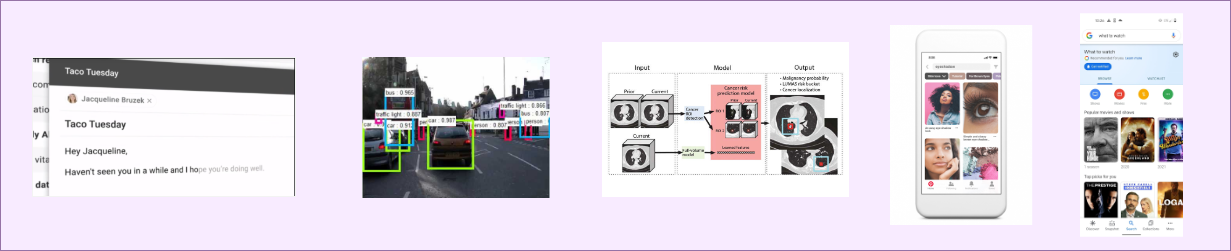
Current State of Machine Learning -- Model Centric ML.
While ML is in its infancy - the tools are maturing. Let’s look at the advances in models and new standards in the ML landscape that have helped improve model-centric ML:
Models have become increasingly commoditized.
We have seen models become commoditized, and it's become easier to get models that have been pre-trained on very large organized data sets of curated text and images from open sources of information (e.g. Wikipedia, ImageNet). This has led to the rise of techniques like transfer learning and systems like Hugging Face, paving the way for this kind of commoditization.
Hyperparameter optimization has become standardized.
We have also seen the standardization of the hyperparameter tuning process, which reduced model development to a few lines of code. Tools like Optuna, Keras Tuner, and NNI (Neural Network Intelligence) have made it possible to automate the hyperparameter optimization step of your workflow.
Mature machine learning tooling and infrastructure landscape.
The infrastructure for machine learning has grown a lot since via modeling SDKs such as PyTorch and TensorFlow allowing for the creation of models in a few lines of code, and ML data management systems like Feature Stores, as well as new ideas for embedding stores becoming industry-standard.
Essentially, running complex ML workloads at scale has become more automated and accessible than it was a few years back. Running deep learning jobs at scale has further become simple via the advent of frameworks like Horovod and Ray.
This immense maturing of the ML tooling landscape has put the onus on the one key ingredient in the ML recipe that's not only constantly changing, but also something that, when of bad quality, practically brings the entire ML system down - data.
What is the problem with Model Centric ML? -The Issues Lie in the Data
Today, ML model-centric approaches have become a simple and standard task. There is immense literature and resources on almost any topic imaginable, and so many code repositories that can be used for reference. With this standardization, the focus has shifted to the data, which has become the lifeblood of machine learning models.

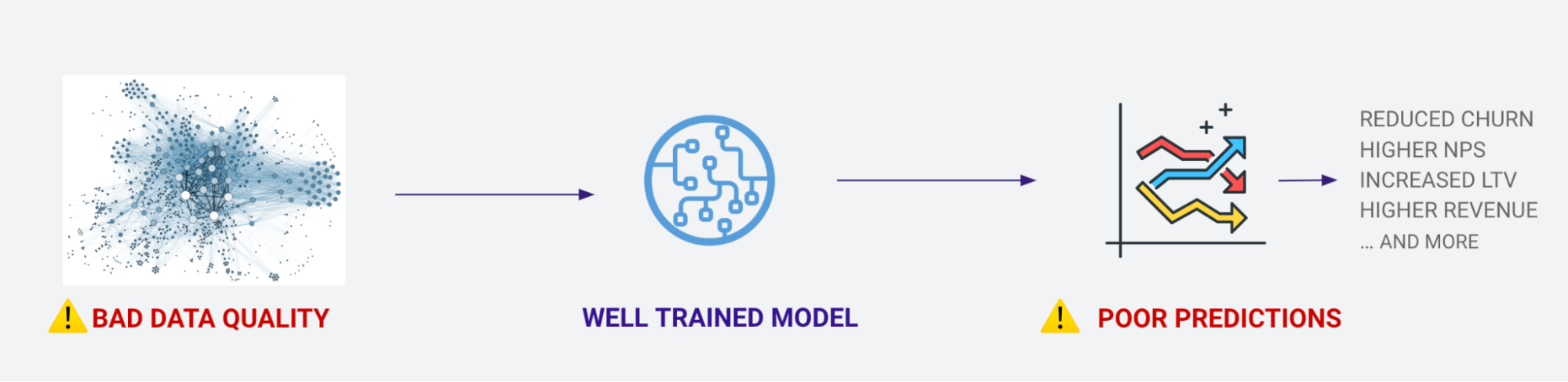
Building a well-trained model on high-quality data leads to better prediction. But poor quality data, even on a well-trained model, leads to bad predictions, and in turn bad business outcomes. The problem of data quality is even more prevalent with unstructured data like text, images, and audio, which is primarily about 80% of the world's data.
Data quality over quantity.
Companies are generating so much data that data lakes have become the equivalent of data landfills. It's led to finding high-quality data for ML nearly impossible. The outcome is that models get trained on irrelevant, poor-quality features and the lack of observability leads to models being trained on data often laden with noise, insufficiently well-labeled, or generally of low quality.
If we look at fintech, healthcare, retail companies, or even high-tech firms with a very high production ML footprint, feature engineering suffers from low-quality data seeping into ML pipelines far too often.
On top of that, data scientists typically habitually throw the kitchen sink of features at the model without a systematic approach towards pruning the right and relevant features. This, combined with the lack of observability, often leads to "model downtimes," which refer to regressed model behavior and bad-quality predictions.
So where do the data issues lie in the different lifecycle phases?

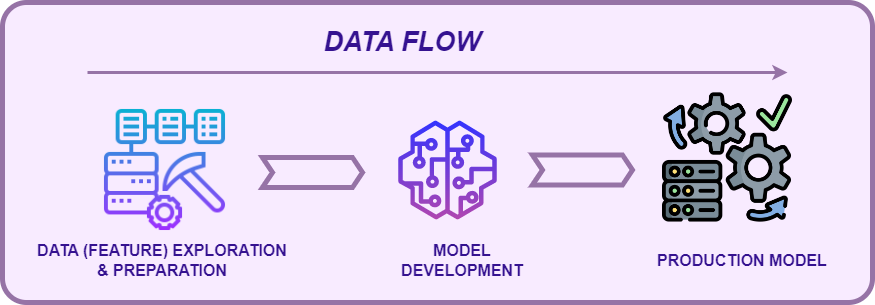
Data quality issues lead to ML Model "Soft outages"
The problem starts with the first step of feature engineering: finding the ideal dataset. By "ideal," we mean the most diverse and representative data or features that can give your model optimum performance. You want to find and organize the data set that best fits the needs of your model. Typically, this is an iterative process, but the goal is to figure out the minimal data set you want to train your model on.
In structured ML with numeric and categorical features, the best dataset includes having representative features, less redundancy, and less overlapping correlation. When it comes to unstructured data, curating the best data set can mean a multitude of things -- striking a balance across your ground truth labels, curating a representative set of samples, avoiding validation leakage, and mitigating production data imbalances and biases amongst others. Embeddings are a powerful means to assist with selecting the right data for the ML use case at hand.
What makes embeddings so powerful is the preservation of contextual information of the data samples that when clustered together, help in creating balanced training and validation datasets for your model. There's other important factors such as class imbalance, labeling errors, and anomalous data that need fixing prior to training and validating models.
Such dataset errors, when not fixed, lead to model "soft-outages" where the model makes erroneous and awry predictions that become extremely hard to debug and root cause.
Data quality problems at the model development level.
Trusting your data set means identifying vulnerabilities, quality issues, and general errors that might degrade its quality during training. Investigating model metrics like F1 scores and confusion matrices is necessary but insufficient. It's essential to look at the data through the lens of the model, and that includes:
- Identifying different regions of model underperformance,
- Evaluating robustness across different subpopulations of your data set,
- Spotting label anomalies and identifying similar examples to these anomalies,
- Fixing the noisy data and the ground truth errors.
During the model evaluation stage, the validation and test datasets can tell you a lot about how well your model works, and you can use that information to find flaws in the data and the model.
Data quality problems at the model deployment level.
When you deploy your model to production, there’ll inevitably be changes in the underlying distribution of your production data compared to the training data. The features may drift, and anomalous data may be encountered. You must identify this drift compared to the feature distributions of your training dataset, correlate model drift with important features, and do all of this in real-time.
Remember that finding these problems is only part of the problem. The continuous loop of the ML flywheel is completed by connecting it back to the training dataset.
Model Quality Problems are Mostly Data Problems
Let’s look at some of the key challenges you might face when you want to train and deploy your models:
- Curating 'high value' training data.
- Identifying noisy data and labels.
- Finding dataset vulnerabilities.
- Data quality issues in production.
Curating 'high value' training data.
Part of the pre-training workflow is to find the most representative data. Data annotation budgeting, where active learning plays a key role, is where the challenge lies. Leveraging embeddings from the pre-trained layers of your model can help identify sparse regions in your data set and help pick a diverse data set that's ideal for your model.
Clustering can help a practitioner choose data sets with the most value and give the optimal model performance with the least amount of data. Clustering algorithms can also be helpful for automated data slicing, which is an effective way to label your datasets automatically.
Measuring feature redundancy and feature relevance to labels via mutual information helps filter out data with similar correlations to labels and other features and find features that don't add much value to the models—especially for structured data. This not only saves resources and compute, but also helps build powerful models with minimal data.
Identifying noisy data and labels.
How can you effectively identify noisy data so you can build quality models on clean data? Statistical methods can help you distinguish between noisy data and good data. For example, you can look at confidence margins and confidence correlations to see how the uncertainty in the models across different features affects the data. This can help you determine where your model isn't working well and what data you should add.
In addition to looking at uncertainty at the level of a feature vector, you can also detect errors in the ground truth labels by looking at the joint distributions of noisy and clean labels and the percentage of observed samples that are wrongly misclassified. On top of this, you can also leverage SHAP values for feature attribution and explainability.
Finding dataset vulnerabilities.
You must be able to spot model underperformance in the dataset if you want to make sure that you train and deploy high-quality models. This includes using similarity measures and nearest-neighbor methods to find interesting subpopulations and clusters of anomalous data points.
Overall, you should optimize development time by providing systematic tooling that integrates seamlessly with other frameworks and platforms in your ML workflow and automates the detection of these issues as the model moves from training to production.
Data quality issues in production.
When your models get deployed to production, adapting the model to changing data over time ensures the models are continuously making good predictions. When you put a model into production, the production traffic patterns change, the features drift, and your model encounters odd data points.
It's critical to identify these issues in the data distribution and monitor them across different subpopulations of interest in your dataset, and tie them back to the training ecosystem for example in determining when it’s a good time to re-train.
This completes a flywheel where you can use the insights to auto-retrain models by either adding synthetic data to your data sets, finding missing sparse features, or extracting new features from other knowledge bases and embeddings from pre-trained models.
Key Takeaways
Machine Learning is at an inflection point where the practical applicability has been validated, and model, hyperparameter, and infrastructure automation blueprints have been laid out. This has unlocked the building of advanced models with powerful capabilities and brought them to the hands of a citizen practitioner.
The one variable which significantly improves the quality of models is the data. Building high-quality models has hence come down to curating highly data!
At all stages of the machine learning lifecycle, data-centric techniques that detect various forms of noise in datasets and fix them to curate high-quality data can lead to high-quality models that run continuously in your ecosystem.
Watch my full talk from the Feature Store Summit.
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
